Fahim Farook
Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"ReDi: Efficient Learning-Free Diffusion Inference via Trajectory Retrieval. (arXiv:2302.02285v1 [cs.CV])" — A simple yet learning-free Retrieval-based Diffusion sampling framework capable of fast inference, which retrieves a trajectory similar to the partially generated trajectory from a precomputed knowledge base at an early stage of generation, skips a large portion of intermediate steps, and continues sampling from a later step in the retrieved trajectory.
Paper: http://arxiv.org/abs/2302.02285
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion Inference (upper) and…
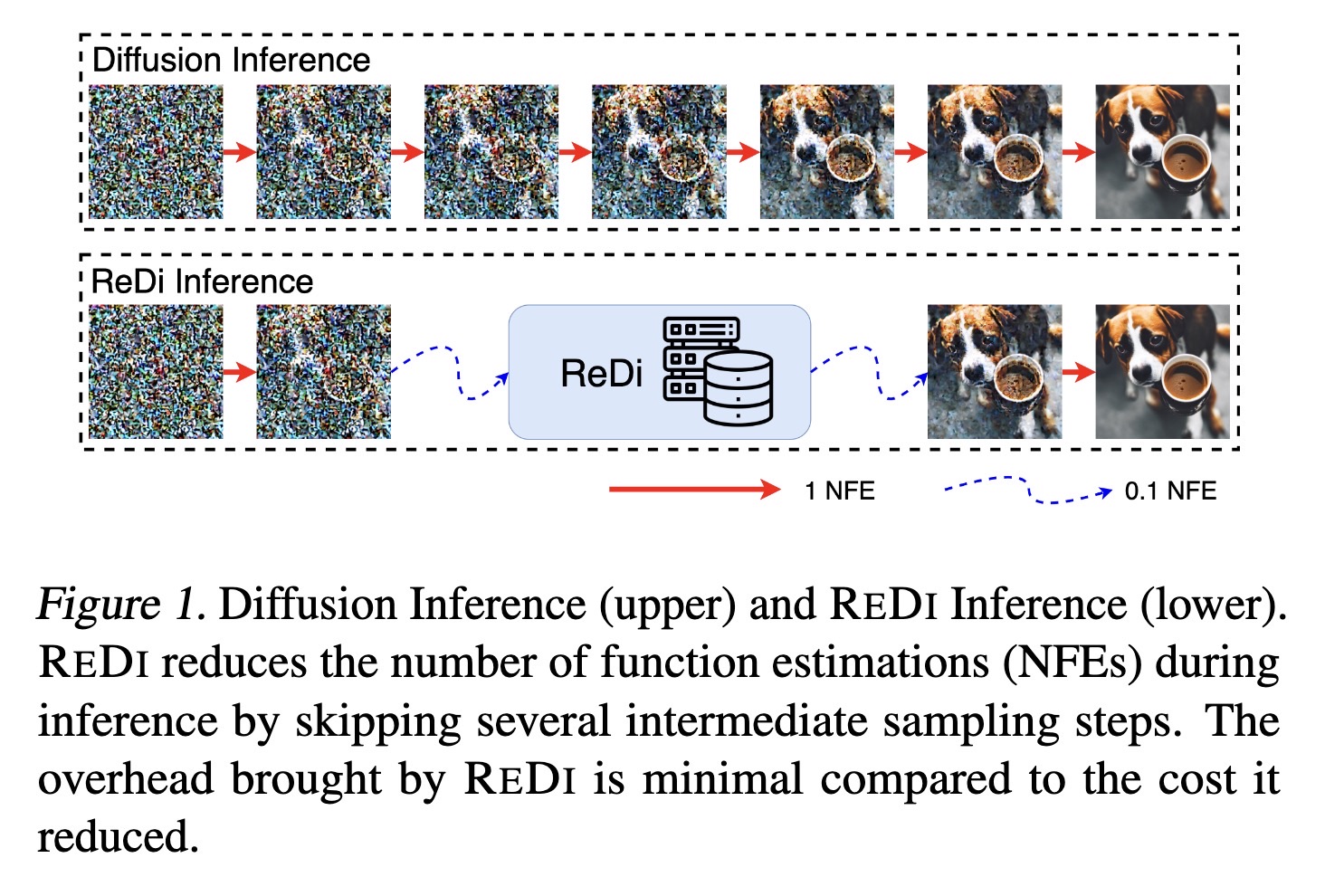
Paper: http://arxiv.org/abs/2302.02285
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion Inference (upper) and…
 0
0
 1
1
 0
0
Fahim Farook
f
"Design Booster: A Text-Guided Diffusion Model for Image Translation with Spatial Layout Preservation. (arXiv:2302.02284v1 [cs.CV])" — A new approach for flexible image translation by learning a layout-aware image condition together with a text condition, which co-encodes images and text into a new domain during the training phase.
Paper: http://arxiv.org/abs/2302.02284
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Style image translation and sem…

Paper: http://arxiv.org/abs/2302.02284
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Style image translation and sem…
0
1
0
Fahim Farook
f
"Divide and Compose with Score Based Generative Models. (arXiv:2302.02272v1 [cs.CV])" — Learning image components in an unsupervised manner in order to compose those components to generate and manipulate images in an informed manner.
Paper: http://arxiv.org/abs/2302.02272
Code: https://github.com/sandeshgh/Score-based-disentanglement
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Using all score components resu…
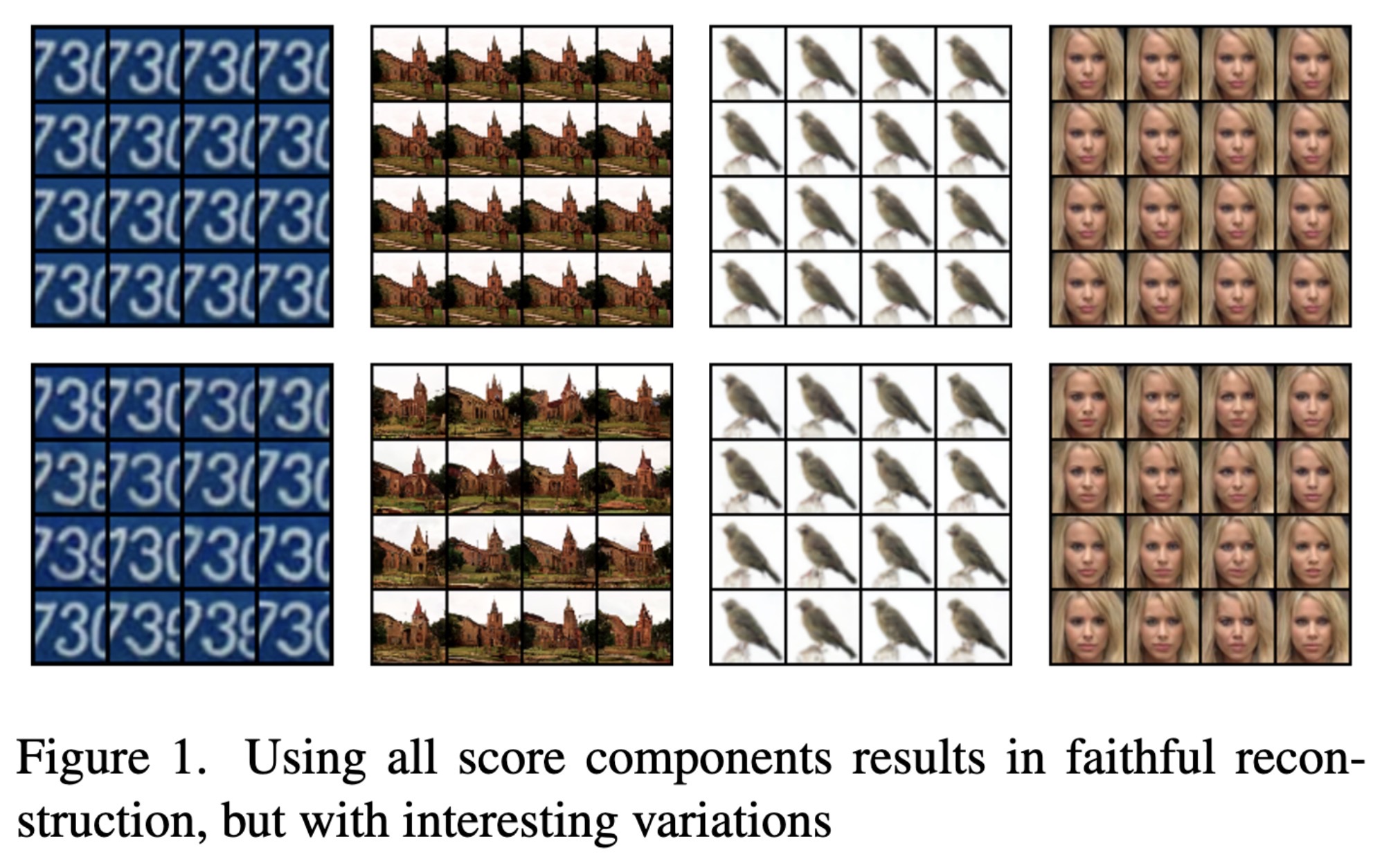
Paper: http://arxiv.org/abs/2302.02272
Code: https://github.com/sandeshgh/Score-based-disentanglement
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Using all score components resu…
0
1
0
Fahim Farook
f
"Real-Time Image Demoireing on Mobile Devices. (arXiv:2302.02184v1 [cs.CV])" — A study on accelerating demoireing networks and a dynamic demoireing acceleration method (DDA) capable of real-time deployment on mobile devices.
Paper: http://arxiv.org/abs/2302.02184
Code: https://github.com/zyxxmu/DDA
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Images with moir ́e patterns. Th…

Paper: http://arxiv.org/abs/2302.02184
Code: https://github.com/zyxxmu/DDA
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Images with moir ́e patterns. Th…
0
1
0
Fahim Farook
f
"DeepAstroUDA: Semi-Supervised Universal Domain Adaptation for Cross-Survey Galaxy Morphology Classification and Anomaly Detection. (arXiv:2302.02005v1 [astro-ph.GA])" — A universal domain adaptation method to overcome the challenge of artificial intelligence methods extracting dataset-specific, non-robust features.
Paper: http://arxiv.org/abs/2302.02005
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example images from the source …

Paper: http://arxiv.org/abs/2302.02005
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example images from the source …
0
1
0
Fahim Farook
f
"PDEBENCH: An Extensive Benchmark for Scientific Machine Learning. (arXiv:2210.07182v4 [cs.LG] UPDATED)" — A benchmark suite of time-dependent simulation tasks based on Partial Differential Equations (PDEs), which comprises both code and data to benchmark the performance of novel machine learning models against both classical numerical simulations and machine learning baselines.
Paper: http://arxiv.org/abs/2210.07182
Code: https://github.com/pdebench/PDEBench
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
PDEBENCH provides multiple non-…
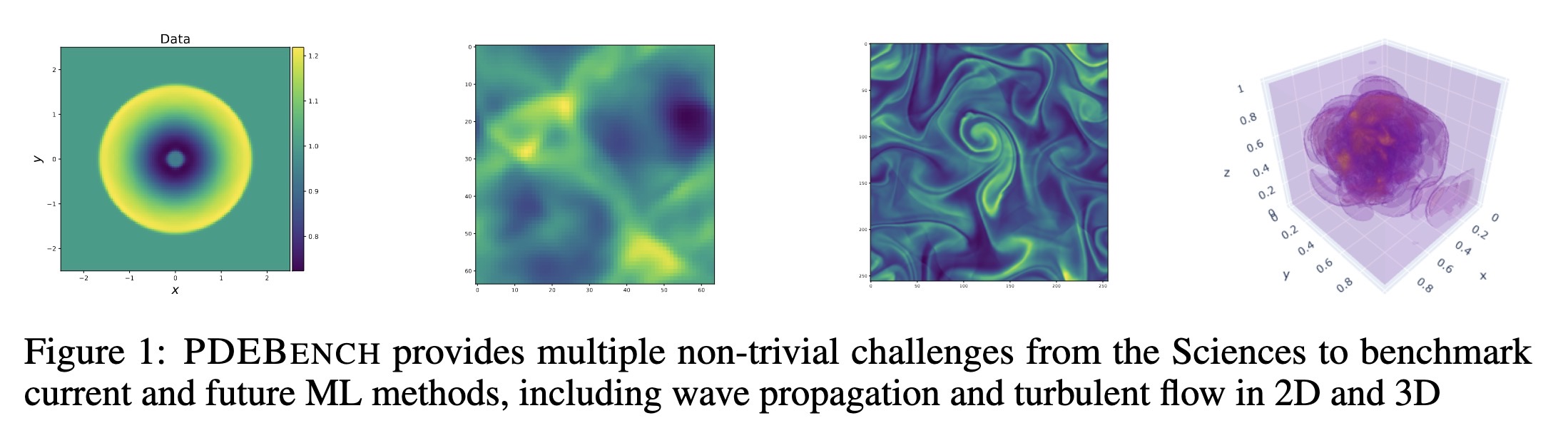
Paper: http://arxiv.org/abs/2210.07182
Code: https://github.com/pdebench/PDEBench
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
PDEBENCH provides multiple non-…
0
2
0
Fahim Farook
f
"Faster Attention Is What You Need: A Fast Self-Attention Neural Network Backbone Architecture for the Edge via Double-Condensing Attention Condensers. (arXiv:2208.06980v3 [cs.CV] UPDATED)" — A faster attention condenser design called double-condensing attention condensers that allow for highly condensed feature embeddings.
Paper: http://arxiv.org/abs/2208.06980
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Proposed AttendNeXt architectur…
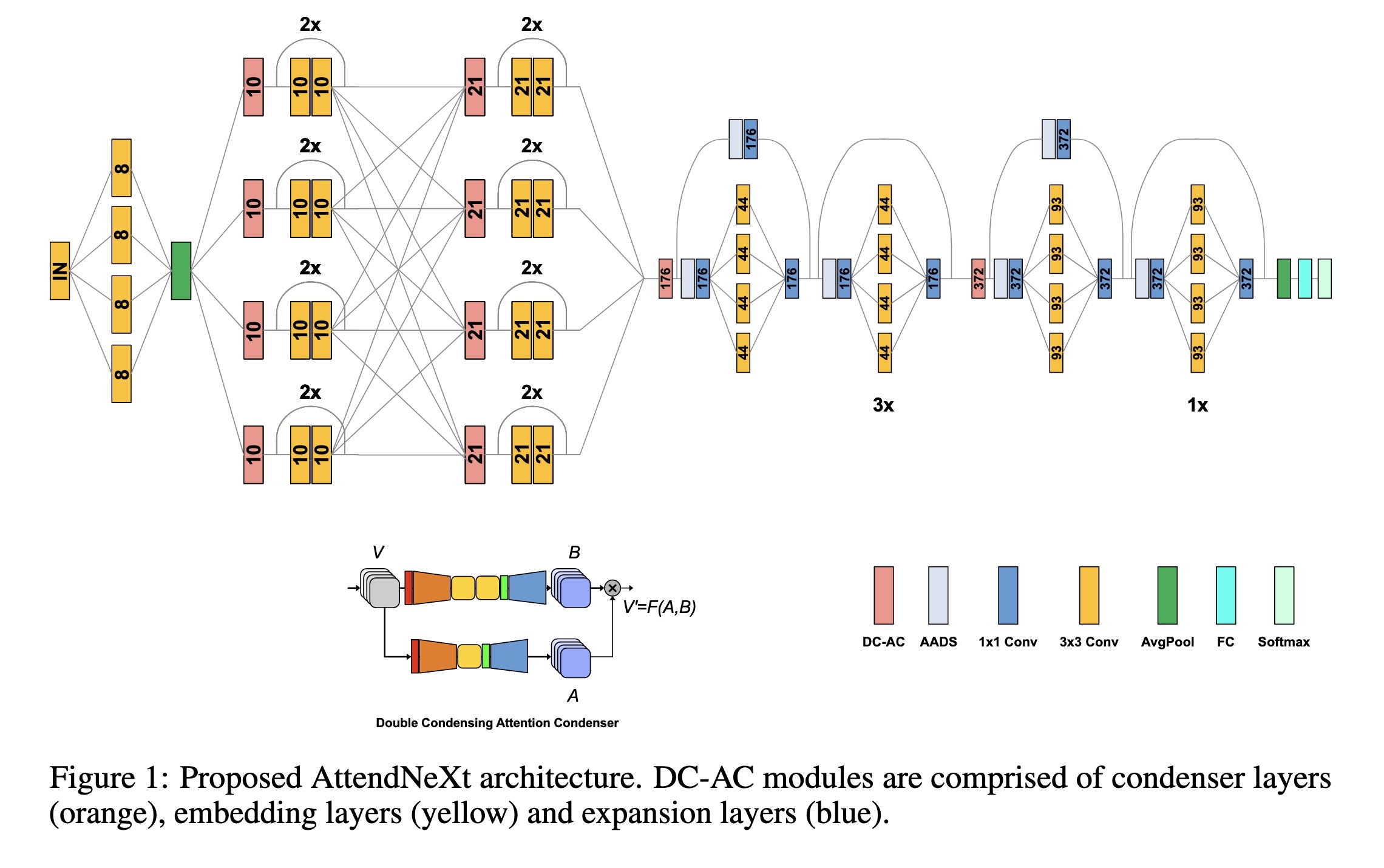
Paper: http://arxiv.org/abs/2208.06980
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Proposed AttendNeXt architectur…
0
1
2
Fahim Farook
f
"IKEA-Manual: Seeing Shape Assembly Step by Step. (arXiv:2302.01881v1 [cs.CV])" — A dataset consisting of 102 IKEA objects paired with assembly manuals to help improve/test shape assembly activities since the manuals provide step-by-step guidance on how we should move and connect different parts in a convenient and physically-realizable way.
Paper: http://arxiv.org/abs/2302.01881
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
IKEA-Manual, a dataset for step…
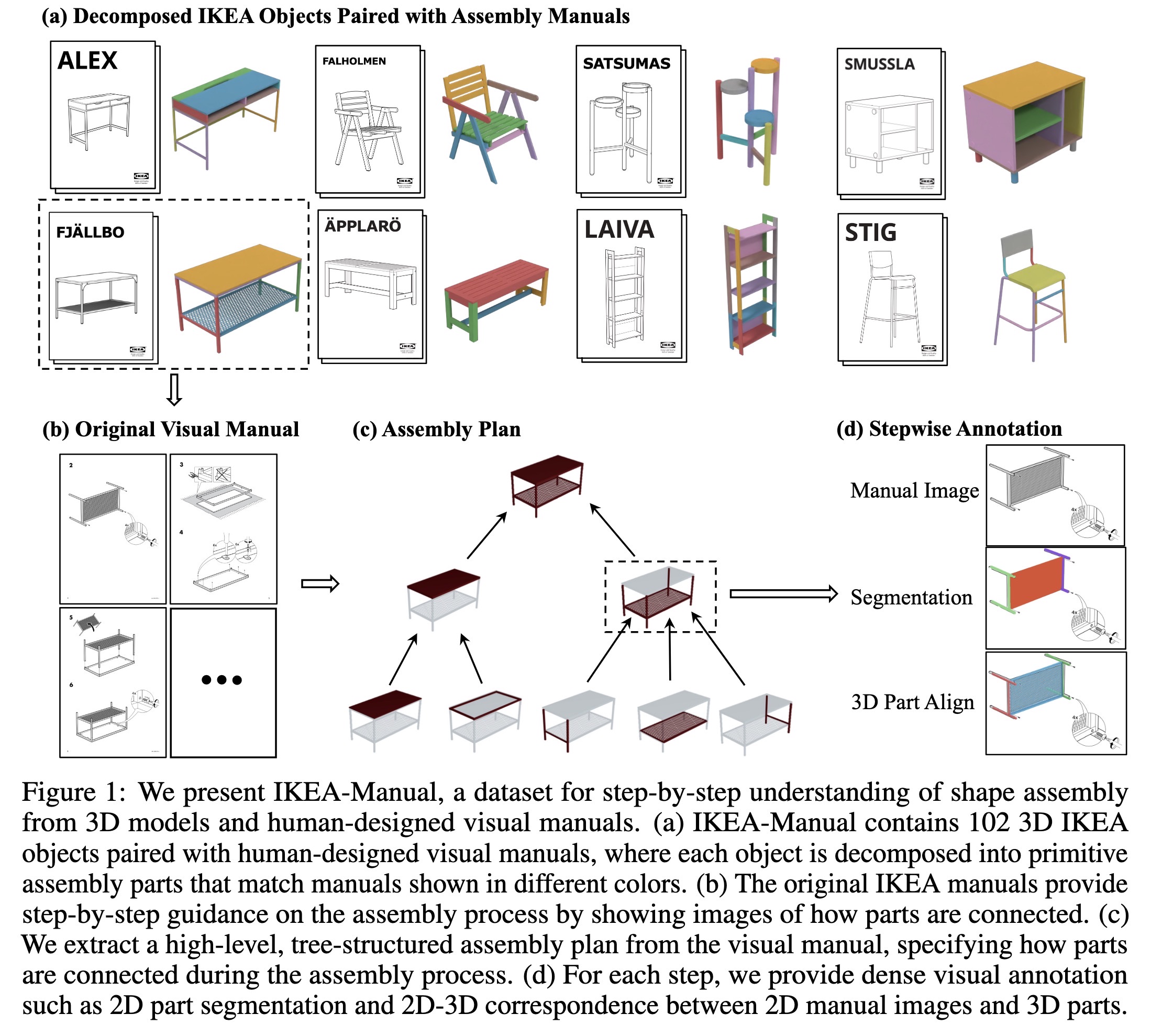
Paper: http://arxiv.org/abs/2302.01881
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
IKEA-Manual, a dataset for step…
0
1
0
Fahim Farook
f
"BackdoorBox: A Python Toolbox for Backdoor Learning. (arXiv:2302.01762v1 [cs.CR])" — An open-sourced Python toolbox that implements representative and advanced backdoor attacks and defenses under a unified and flexible framework to help detect and possibly defend against backdoor attacks against deep neural networks (DNNs).
Paper: http://arxiv.org/abs/2302.01762
Code: https://github.com/THUYimingLi/BackdoorBox
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The framework of BackdoorBox
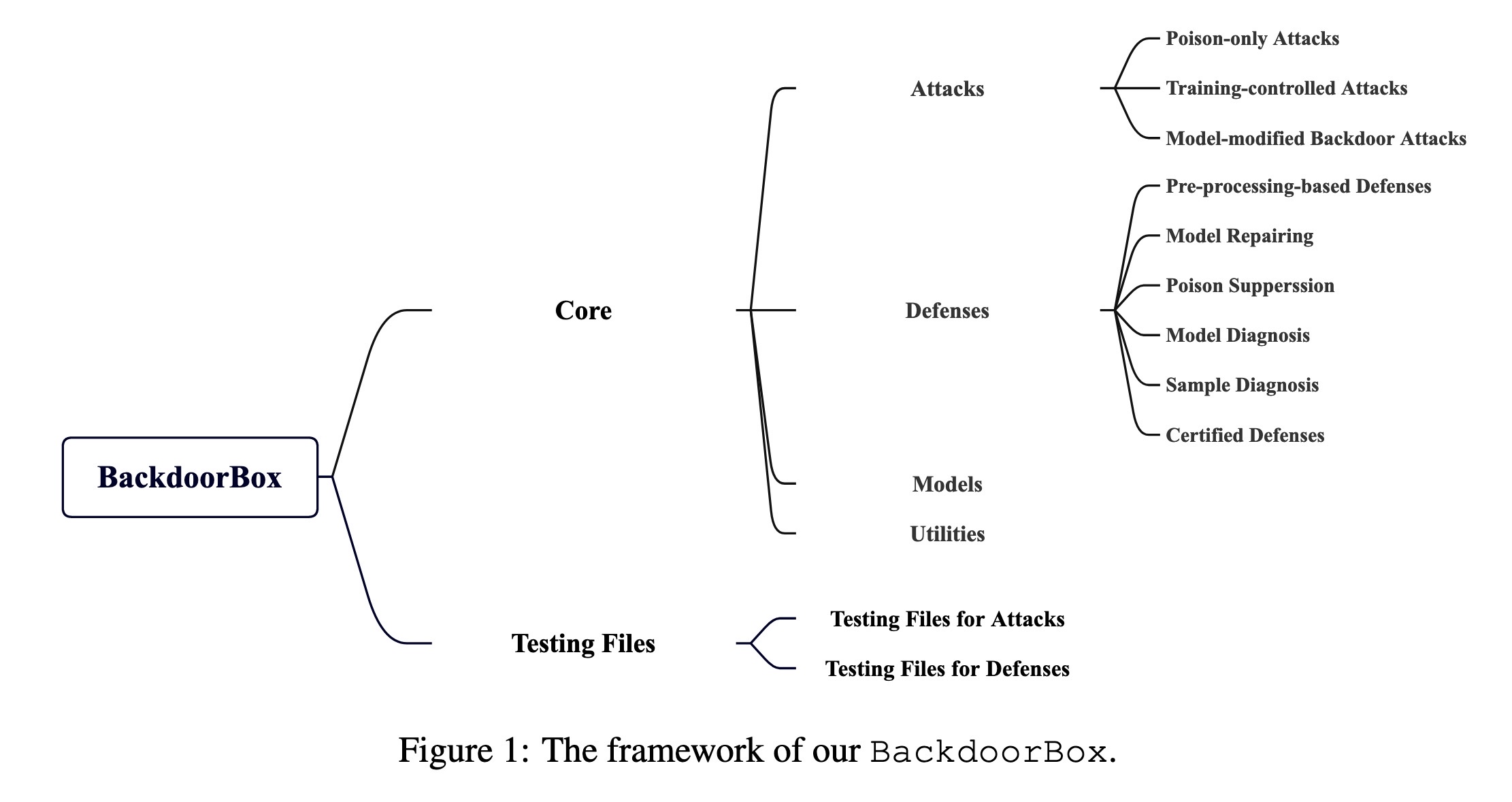
Paper: http://arxiv.org/abs/2302.01762
Code: https://github.com/THUYimingLi/BackdoorBox
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The framework of BackdoorBox
0
0
0
Fahim Farook
f
“Creating a Large Language Model of a Philosopher” — Tries to answer the question: “Can large language models be trained to produce philosophical texts that are difficult to distinguish from texts produced by human philosophers?” by fine-tuning OpenAI's GPT-3 with the works of philosopher Daniel C. Dennett.
Paper: https://arxiv.org/abs/2302.01339
#AI #CL #NewPaper #DeepLearning #MachineLearning #Language
<<Find this useful? Please boost so that others can benefit too 🙂>>”
A graph showing the success rat…
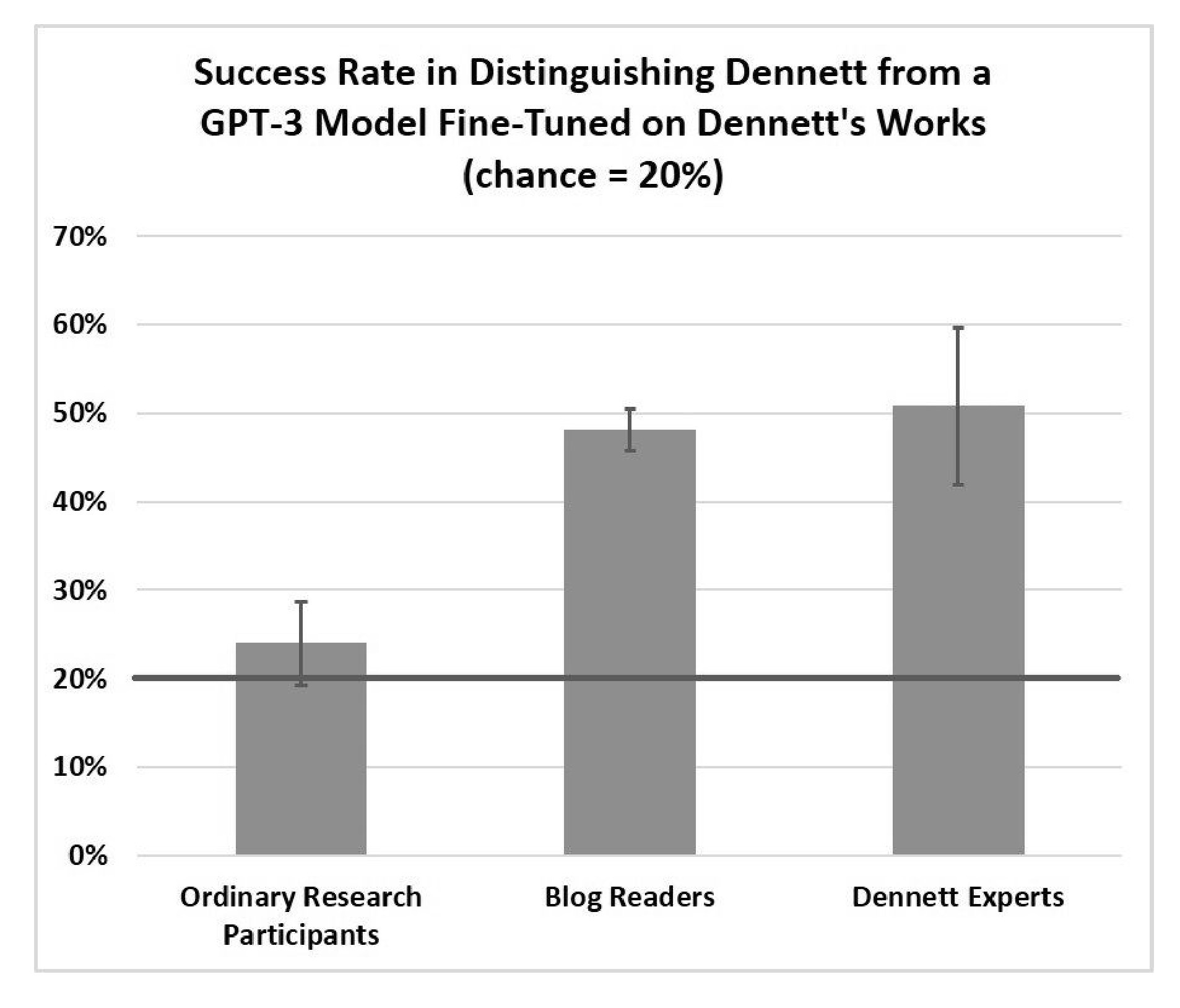
Paper: https://arxiv.org/abs/2302.01339
#AI #CL #NewPaper #DeepLearning #MachineLearning #Language
<<Find this useful? Please boost so that others can benefit too 🙂>>”
A graph showing the success rat…
0
5
2
Fahim Farook
f
“Towards Attention-aware Rendering for Virtual and Augmented Reality” — An attention-aware model of contrast sensitivity based on measuring contrast sensitivity under different attention distributions and discovering that sensitivity in the periphery drops significantly when the user is required to allocate attention to the fovea.
Paper: https://arxiv.org/abs/2302.01368
#NewPaper #HumanComputerInteraction #Graphics #VR #AR #ImageProcessing #VideoProcessing
<<Find this useful? Please boost so that others can benefit too 🙂>>
Foveated graphics techniques re…
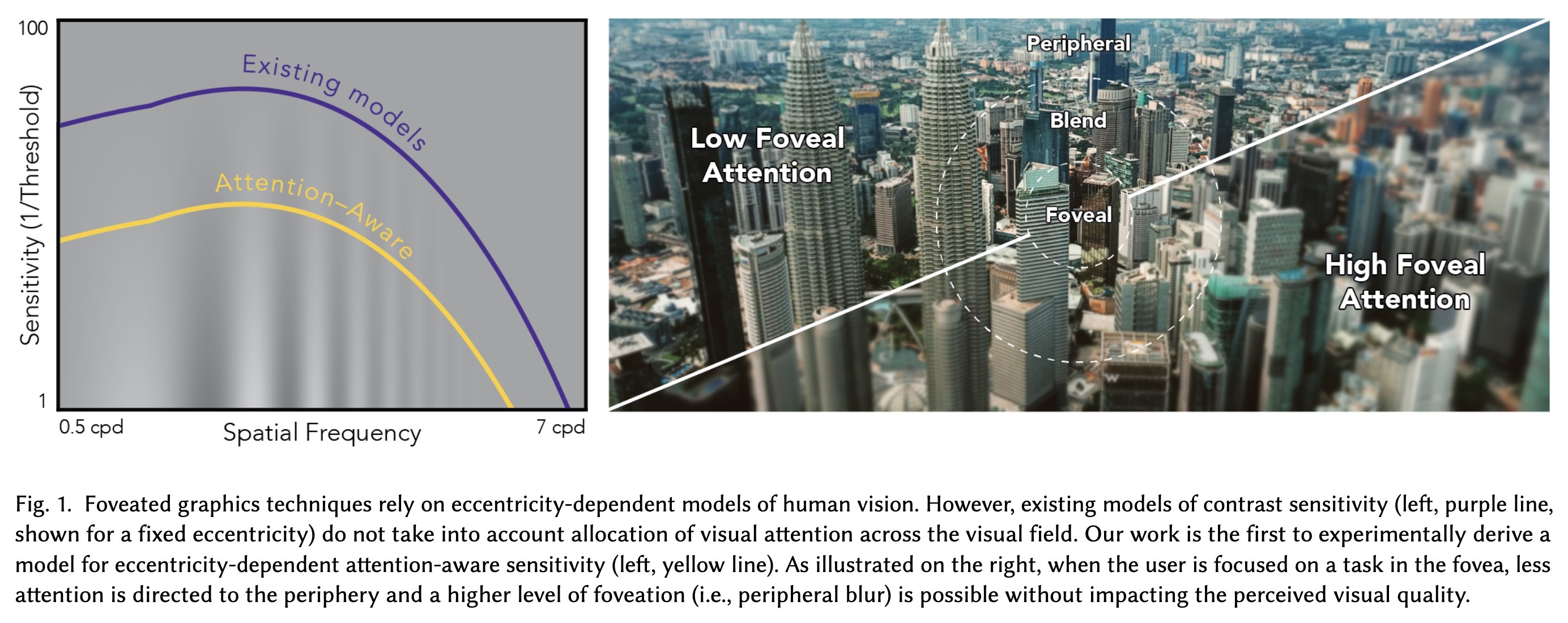
Paper: https://arxiv.org/abs/2302.01368
#NewPaper #HumanComputerInteraction #Graphics #VR #AR #ImageProcessing #VideoProcessing
<<Find this useful? Please boost so that others can benefit too 🙂>>
Foveated graphics techniques re…
0
1
0
Fahim Farook
f
"The Learnable Typewriter: A Generative Approach to Text Line Analysis. (arXiv:2302.01660v1 [cs.CV])" — A generative document-specific approach to character analysis and recognition in text lines which builds on unsupervised multi-object segmentation methods, and in particular, those that reconstruct images based on a limited amount of visual elements, called sprites. This approach can learn a large number of different characters and leverage line-level annotations when available.
Paper: http://arxiv.org/abs/2302.01660
Code: https://github.com/ysig/learnable-typewriter
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The Learnable Typewriter. (a) G…
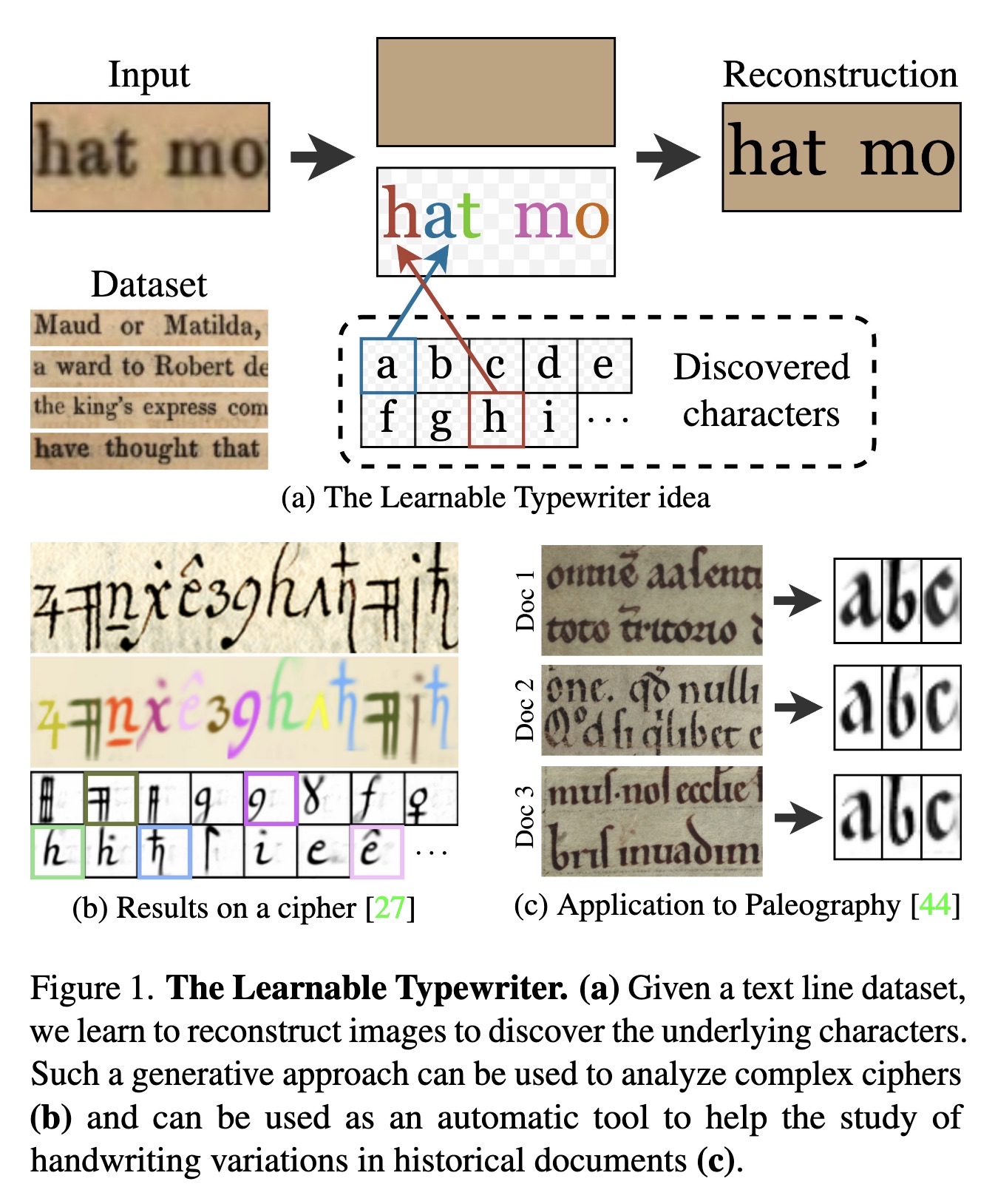
Paper: http://arxiv.org/abs/2302.01660
Code: https://github.com/ysig/learnable-typewriter
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The Learnable Typewriter. (a) G…
0
1
2
Fahim Farook
f
"Cluster-CAM: Cluster-Weighted Visual Interpretation of CNNs' Decision in Image Classification. (arXiv:2302.01642v1 [cs.CV])" — An effective and efficient gradient-free Convolutional Neural Network (CNN) interpretation algorithm which can significantly reduce the times of forward propagation by splitting the feature maps into clusters in an unsupervised manner.
Paper: http://arxiv.org/abs/2302.01642
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The heatmaps are produced by di…
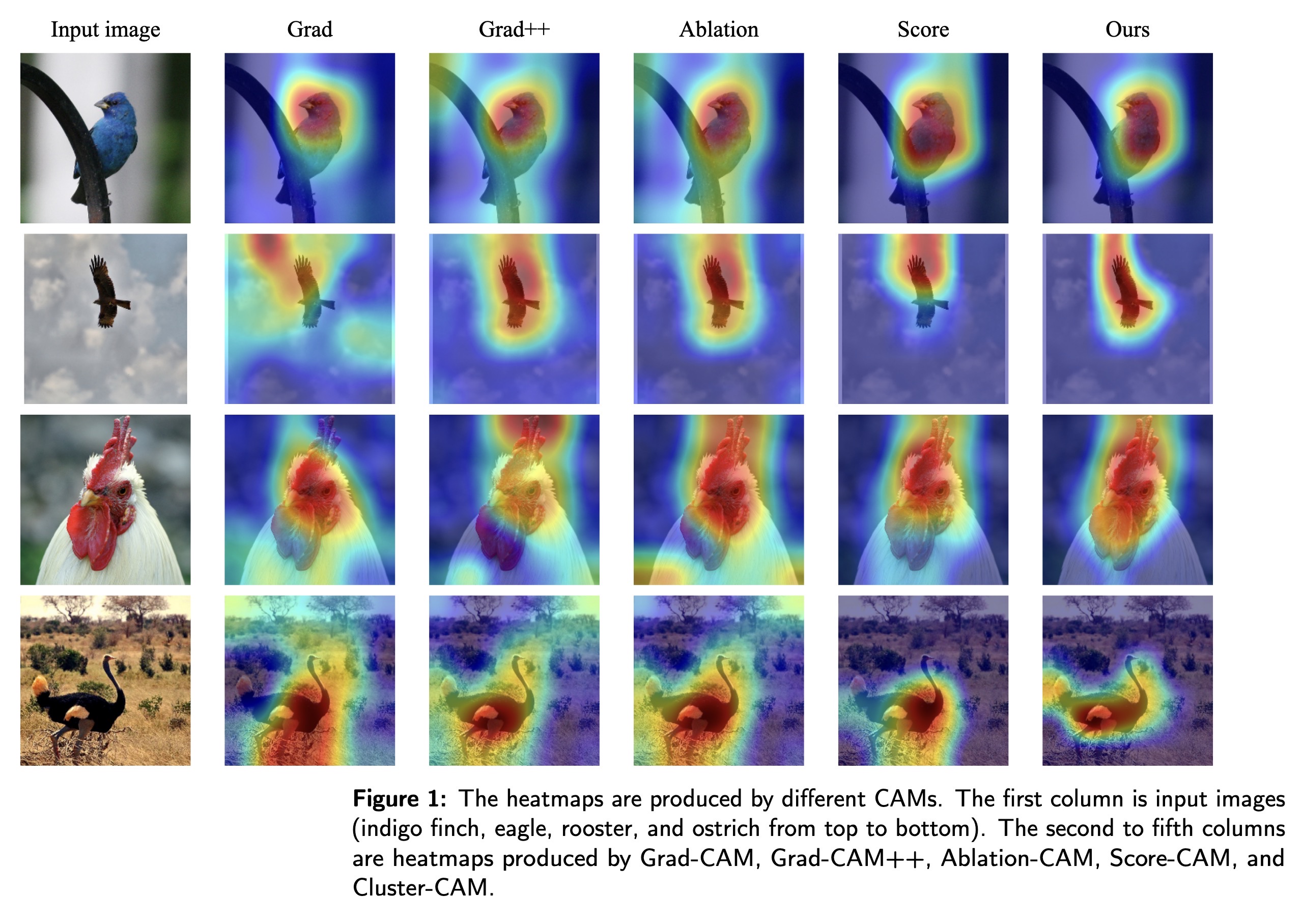
Paper: http://arxiv.org/abs/2302.01642
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The heatmaps are produced by di…
0
1
0
Fahim Farook
f
"CTE: A Dataset for Contextualized Table Extraction. (arXiv:2302.01451v1 [cs.CL])" — A task which aims to extract and define the structure of tables considering the textual context of the document providing data that helps you with document layout analysis and table understanding using a dataset which comprises 75k fully annotated pages of scientific papers, including more than 35k tables.
Paper: http://arxiv.org/abs/2302.01451
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example page (content is intent…

Paper: http://arxiv.org/abs/2302.01451
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example page (content is intent…
0
1
0
Fahim Farook
f
"Understanding and contextualising diffusion models. (arXiv:2302.01394v1 [cs.CV])" — An explanation about how common diffusion models work by focusing on the mathematical theory behind them, i.e. without analyzing in detail the specific implementations and related methods.
Paper: http://arxiv.org/abs/2302.01394
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Intuitive representation of the…
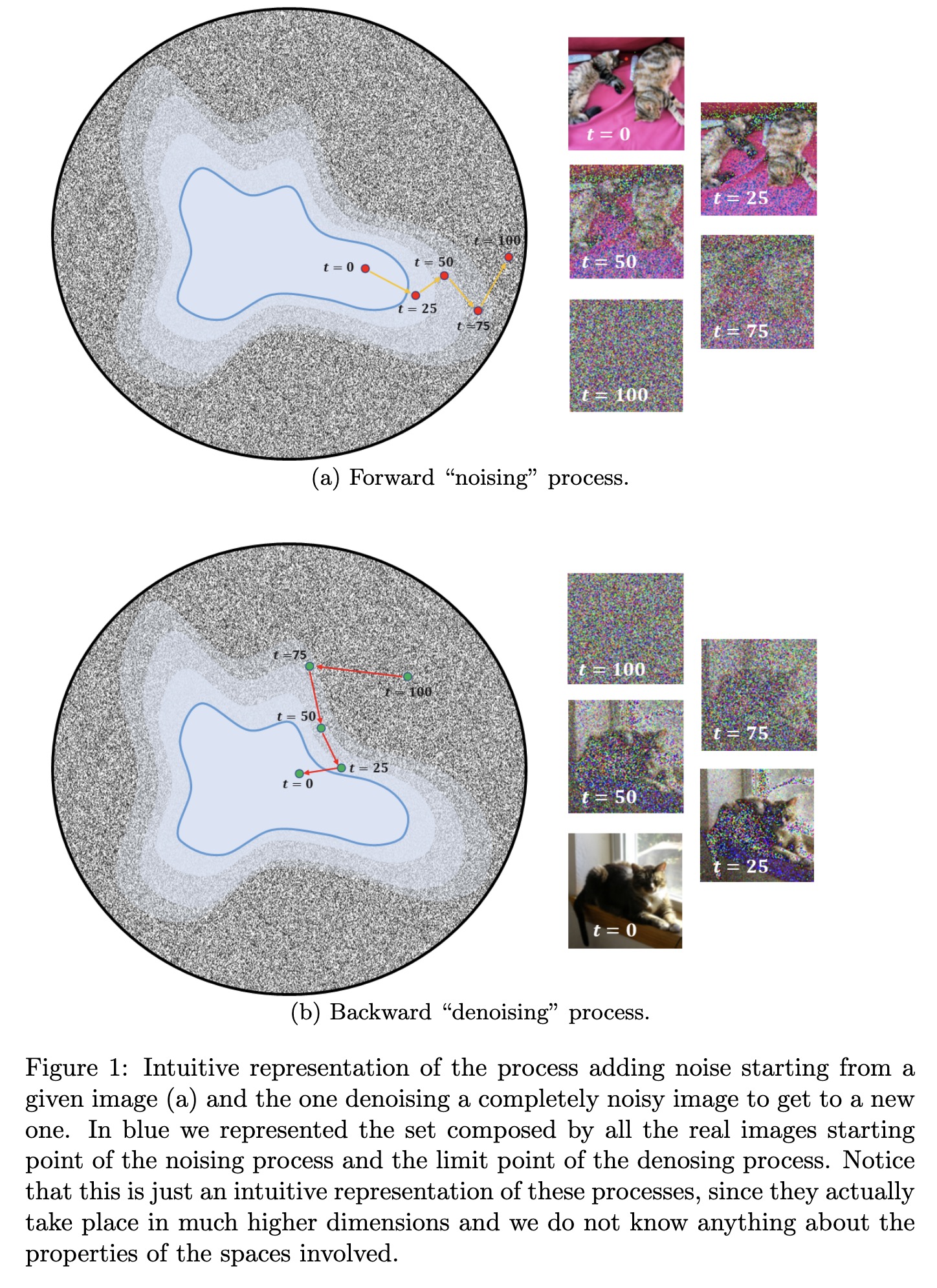
Paper: http://arxiv.org/abs/2302.01394
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Intuitive representation of the…
0
2
1
Fahim Farook
f
Edited 3 years ago
Added a couple of extra filtering options to the home timeline in Tusker and suddenly the timeline is that much more manageable 😃
#Tusker #FediClient #iOS #macOS
A screenshot showing a set of f…
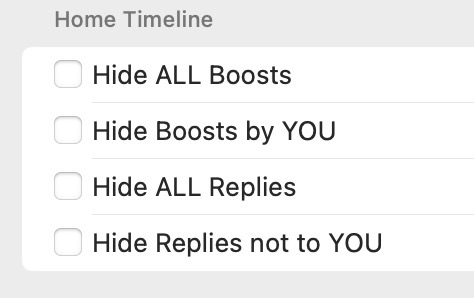
#Tusker #FediClient #iOS #macOS
A screenshot showing a set of f…
1
2
5
Fahim Farook
f
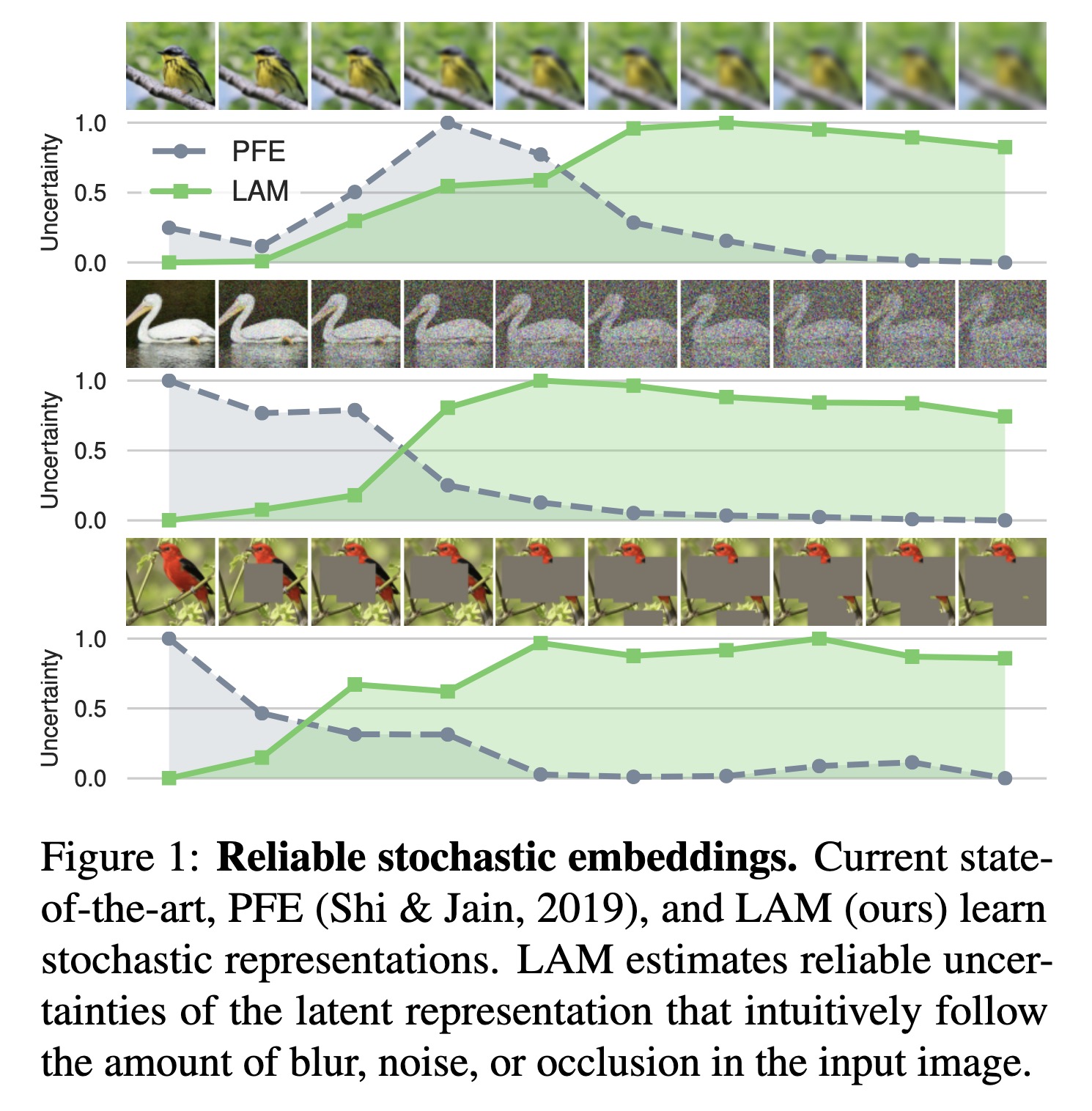
"Bayesian Metric Learning for Uncertainty Quantification in Image Retrieval. (arXiv:2302.01332v1 [cs.LG])" — A Bayesian encoder for metric learning which, rather than relying on neural amortization as done in prior works, learns a distribution over the network weights with the Laplace Approximation.
Paper: http://arxiv.org/abs/2302.01332
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reliable stochastic embeddings.…
Paper: http://arxiv.org/abs/2302.01332
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reliable stochastic embeddings.…
0
1
0
Fahim Farook
f
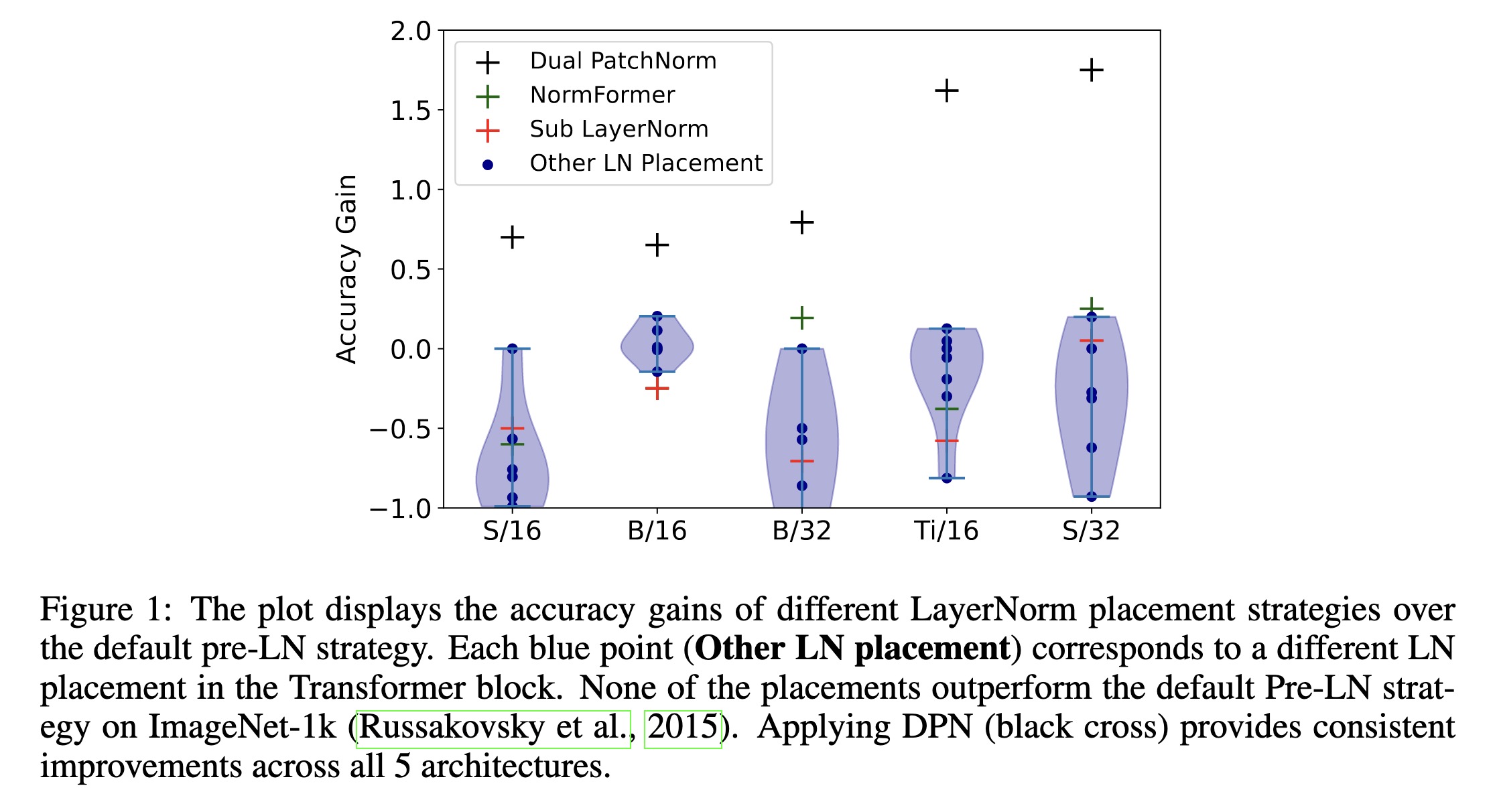
"Dual PatchNorm. (arXiv:2302.01327v1 [cs.CV])" — Experiments with adding two Layer Normalization layers (LayerNorms), before and after the patch embedding layer in Vision Transformers, to see how it affects accuracy.
Paper: http://arxiv.org/abs/2302.01327
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The plot displays the accuracy …
Paper: http://arxiv.org/abs/2302.01327
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The plot displays the accuracy …
0
1
1
Fahim Farook
f
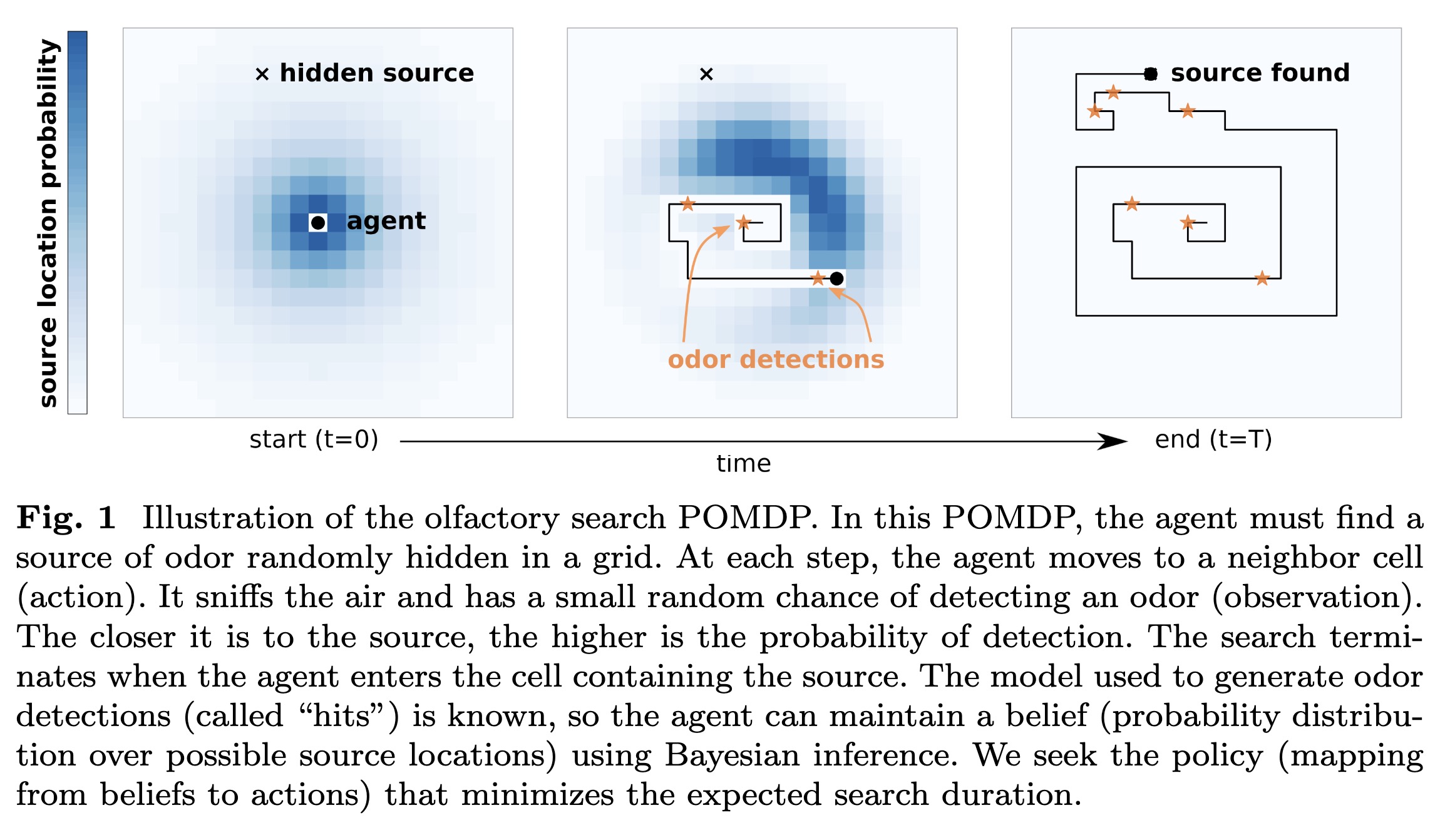
"Deep reinforcement learning for the olfactory search POMDP: a quantitative benchmark" — Using deep reinforcement learning to search for a source of odor in turbulence, as applicable to sniffer robots.
Paper: https://arxiv.org/abs/2302.00706
#NewPaper #Robotics #DeepLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the olfactory s…
Paper: https://arxiv.org/abs/2302.00706
#NewPaper #Robotics #DeepLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the olfactory s…
0
0
0
Fahim Farook
f
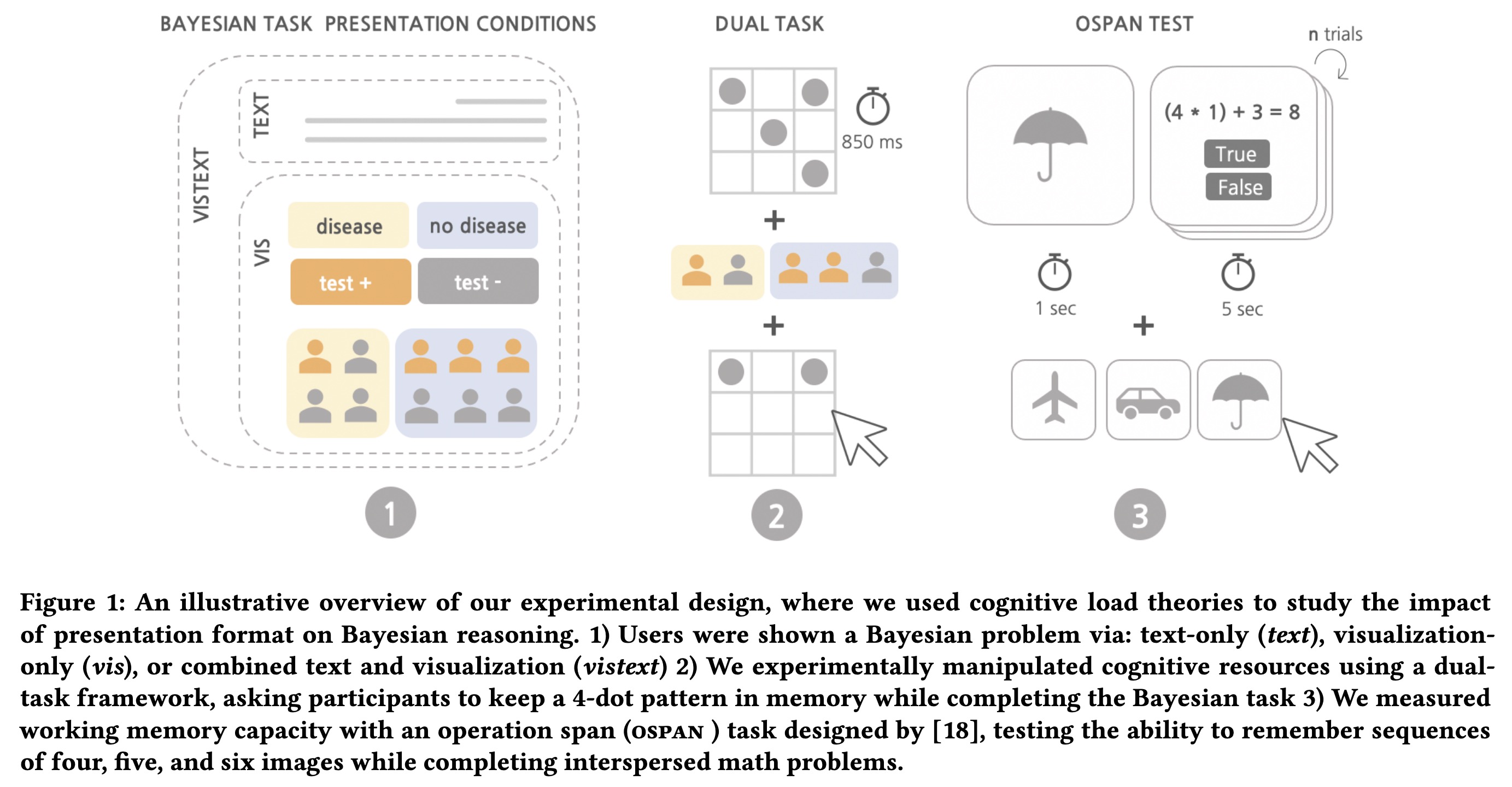
"Why Combining Text and Visualization Could Improve Bayesian Reasoning: A Cognitive Load Perspective" — An examination of the cognitive load elicited when solving Bayesian problems using icon arrays, text, and a juxtaposition of text and icon arrays.
Paper: https://arxiv.org/abs/2302.00707
#NewPaper #HumanComputerInteraction #HC
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustrative overview of our…
Paper: https://arxiv.org/abs/2302.00707
#NewPaper #HumanComputerInteraction #HC
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustrative overview of our…
0
1
0