Conversation
Fahim Farook
f
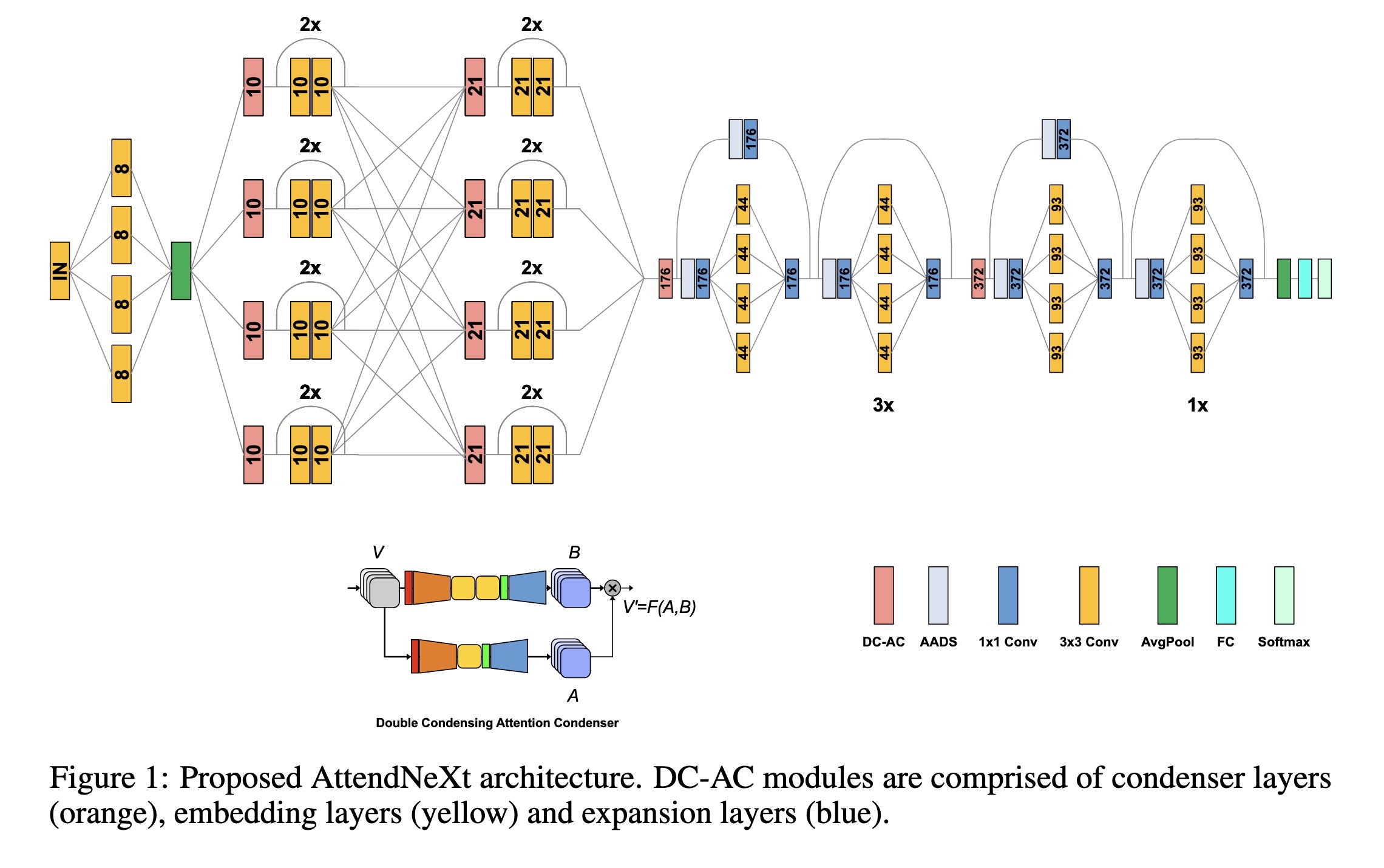
"Faster Attention Is What You Need: A Fast Self-Attention Neural Network Backbone Architecture for the Edge via Double-Condensing Attention Condensers. (arXiv:2208.06980v3 [cs.CV] UPDATED)" — A faster attention condenser design called double-condensing attention condensers that allow for highly condensed feature embeddings.
Paper: http://arxiv.org/abs/2208.06980
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Proposed AttendNeXt architectur…
Paper: http://arxiv.org/abs/2208.06980
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Proposed AttendNeXt architectur…
 0
0
 1
1
 2
2