Fahim Farook
Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"Don't Play Favorites: Minority Guidance for Diffusion Models. (arXiv:2301.12334v1 [cs.LG])" — A framework that can make the generation process of the diffusion models focus on the minority samples, which are instances that lie on low-density regions of a data manifold.
Paper: http://arxiv.org/abs/2301.12334
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion models play favorites…

Paper: http://arxiv.org/abs/2301.12334
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion models play favorites…
 0
0
 1
1
 0
0
Fahim Farook
f
"SEGA: Instructing Diffusion using Semantic Dimensions. (arXiv:2301.12247v1 [cs.CV])" — A semantic guidance method for diffusion models to allow making subtle and extensive edits and changes in composition and style, as well as optimize the overall artistic conception.
Paper: http://arxiv.org/abs/2301.12247
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Semantic control over image gen…

Paper: http://arxiv.org/abs/2301.12247
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Semantic control over image gen…
0
1
0
Fahim Farook
f
"Anticipate, Ensemble and Prune: Improving Convolutional Neural Networks via Aggregated Early Exits. (arXiv:2301.12168v1 [cs.LG])" — A new training technique based on weighted ensembles of early exits, which aims at exploiting the information in the structure of networks to maximise their performance.
Paper: http://arxiv.org/abs/2301.12168
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outline of the AEP technique. O…
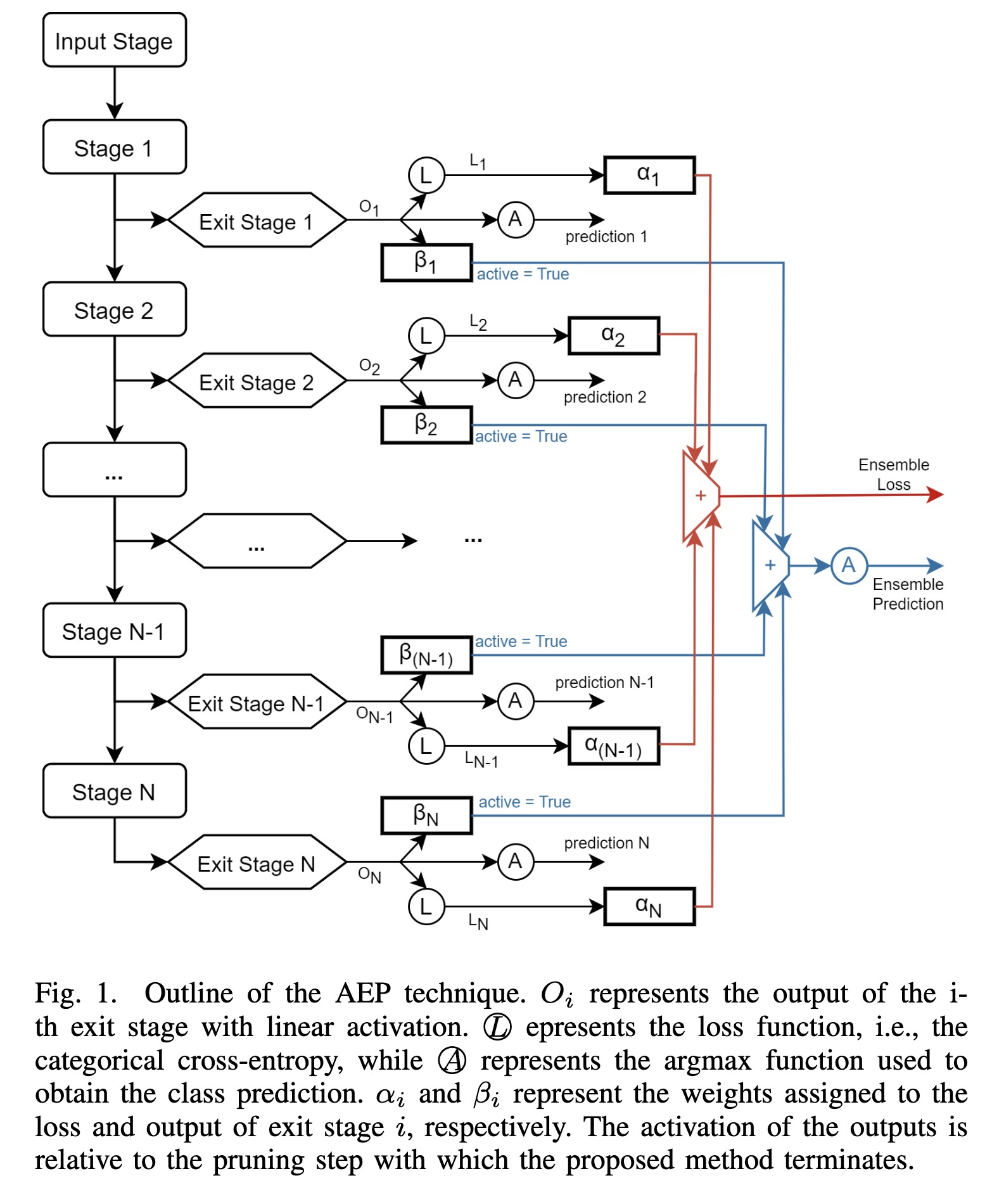
Paper: http://arxiv.org/abs/2301.12168
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outline of the AEP technique. O…
0
1
0
Fahim Farook
f
"ClusterFuG: Clustering Fully connected Graphs by Multicut. (arXiv:2301.12159v1 [cs.CV])" — A simpler and potentially better performing graph clustering formulation based on multicut (a.k.a. weighted correlation clustering) on the complete graph.
Paper: http://arxiv.org/abs/2301.12159
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example illustration of dense m…
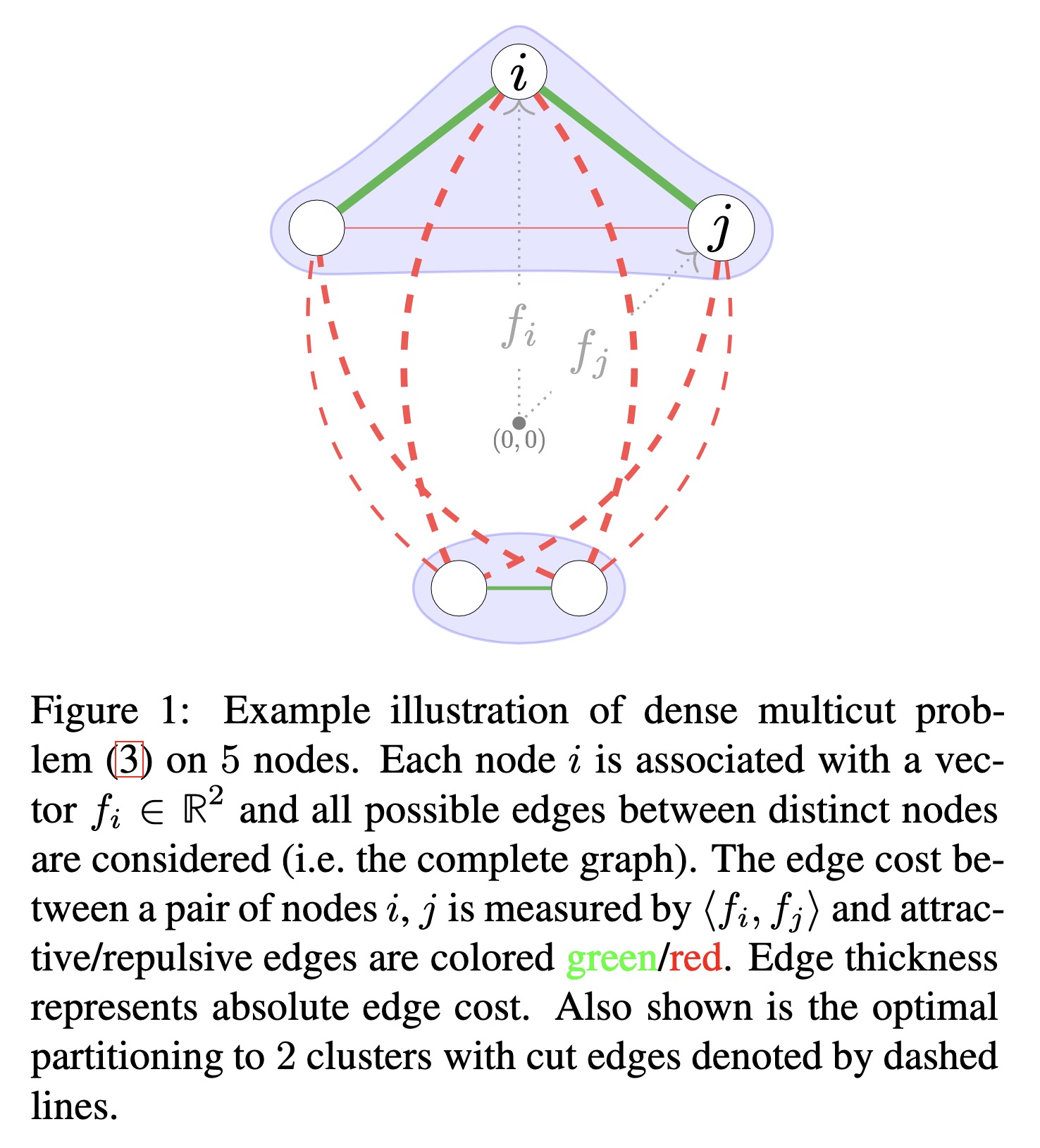
Paper: http://arxiv.org/abs/2301.12159
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example illustration of dense m…
0
1
0
Fahim Farook
f
"Towards Equitable Representation in Text-to-Image Synthesis Models with the Cross-Cultural Understanding Benchmark (CCUB) Dataset. (arXiv:2301.12073v1 [cs.CV])" — A culturally-aware priming approach for text-to-image synthesis using a small but culturally curated dataset to fight the bias prevalent in giant datasets.
Paper: http://arxiv.org/abs/2301.12073
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Sample images generated for fiv…

Paper: http://arxiv.org/abs/2301.12073
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Sample images generated for fiv…
0
1
0
Fahim Farook
f
"Cross-Architectural Positive Pairs improve the effectiveness of Self-Supervised Learning. (arXiv:2301.12025v1 [cs.CV])" — A novel self-supervised learning approach that leverages Transformer and CNN simultaneously to overcome the issues with existing self-supervised techniques which have extreme computational requirements and suffer a substantial drop in performance with a reduction in batch size or pretraining epochs.
Paper: http://arxiv.org/abs/2301.12025
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
In our proposed self-supervised…
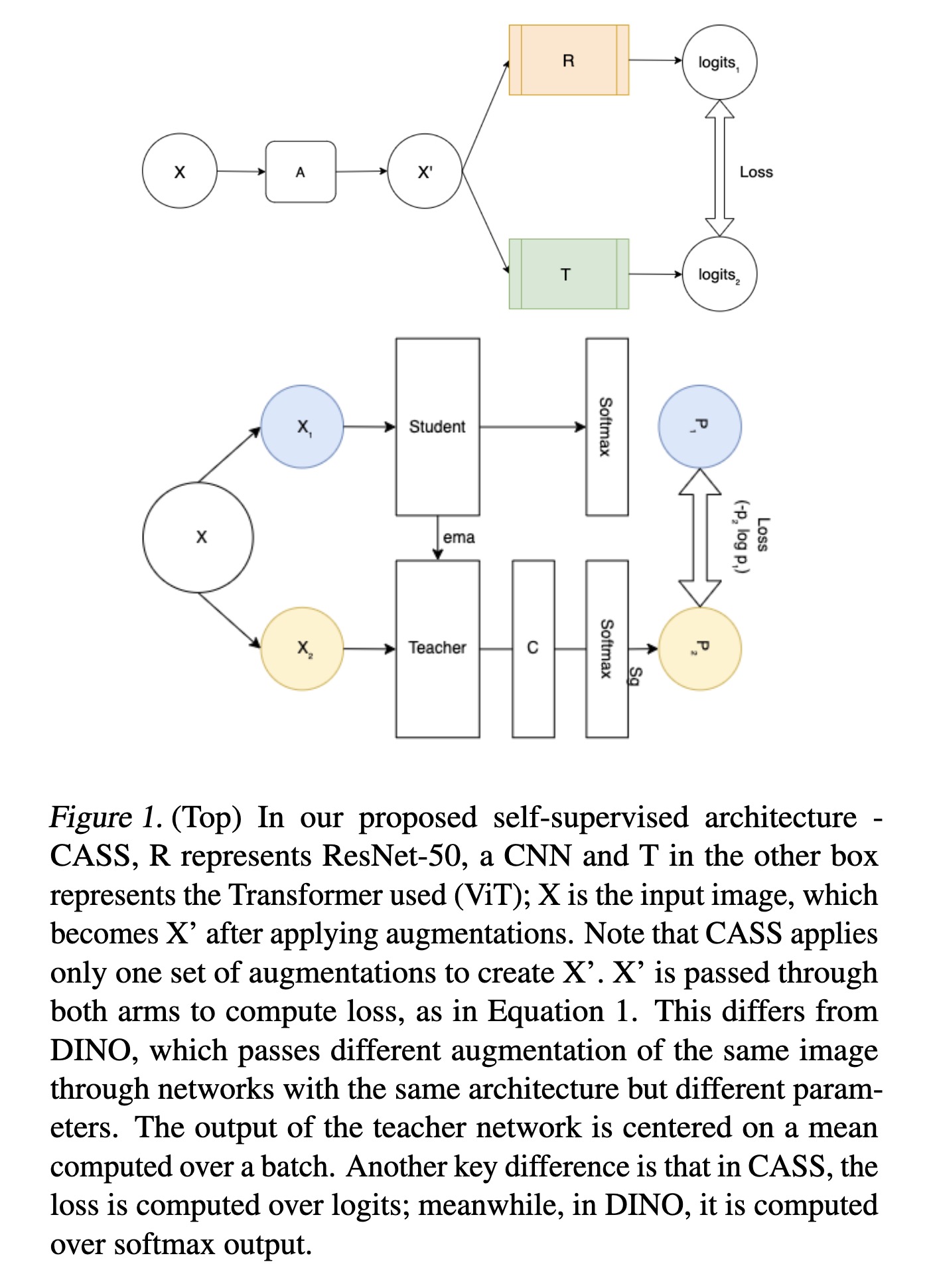
Paper: http://arxiv.org/abs/2301.12025
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
In our proposed self-supervised…
0
2
1
Fahim Farook
f
"Improved knowledge distillation by utilizing backward pass knowledge in neural networks. (arXiv:2301.12006v1 [cs.LG])" — Addressing the issue with Knowledge Distillation (KD) where there is no guarantee that the model would match in areas for which you do not have enough training samples, by generating new auxiliary training samples based on extracting knowledge from the backward pass of the teacher in the areas where the student diverges greatly from the teacher.
Paper: http://arxiv.org/abs/2301.12006
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
a) Minimization Step: Using the…
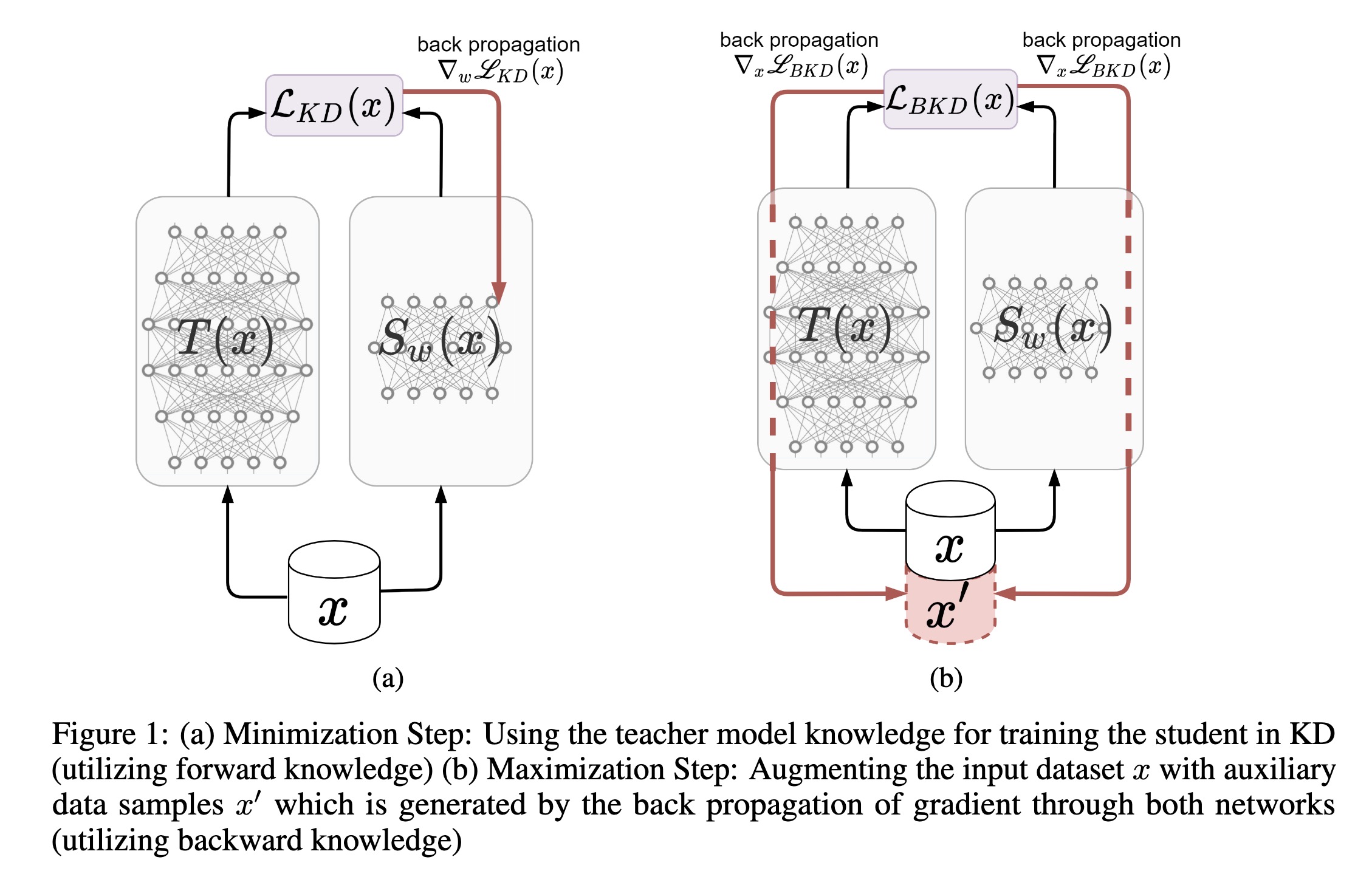
Paper: http://arxiv.org/abs/2301.12006
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
a) Minimization Step: Using the…
0
1
0
Fahim Farook
f
"RGB Arabic Alphabets Sign Language Dataset. (arXiv:2301.11932v1 [cs.CV])" — An Arabic Alphabet Sign Language (AASL) dataset comprising of 7,856 raw and fully labelled RGB images of the Arabic sign language alphabets which might be the first such publicly available dataset.
Paper: http://arxiv.org/abs/2301.11932
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Sample images from the dataset
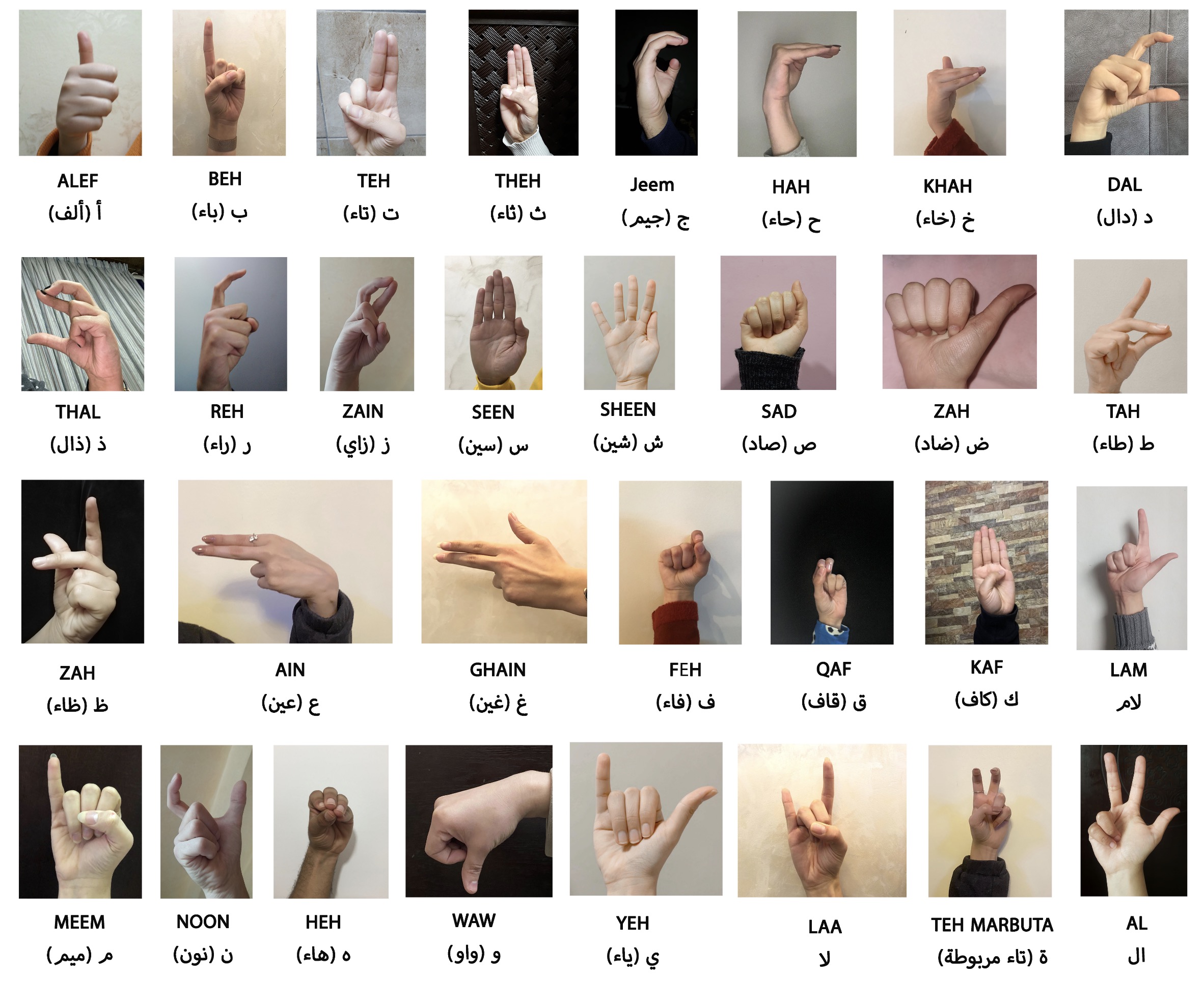
Paper: http://arxiv.org/abs/2301.11932
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Sample images from the dataset
0
1
1
Fahim Farook
f
"Input Perturbation Reduces Exposure Bias in Diffusion Models. (arXiv:2301.11706v1 [cs.LG])" — An exploration of the fact that the the long sampling chain in Denoising Diffusion Probabilistic Models (DDPM) leads to an error accumulation phenomenon, which is similar to the exposure bias problem in autoregressive text generation.
Paper: http://arxiv.org/abs/2301.11706
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The inputs and the prediction t…
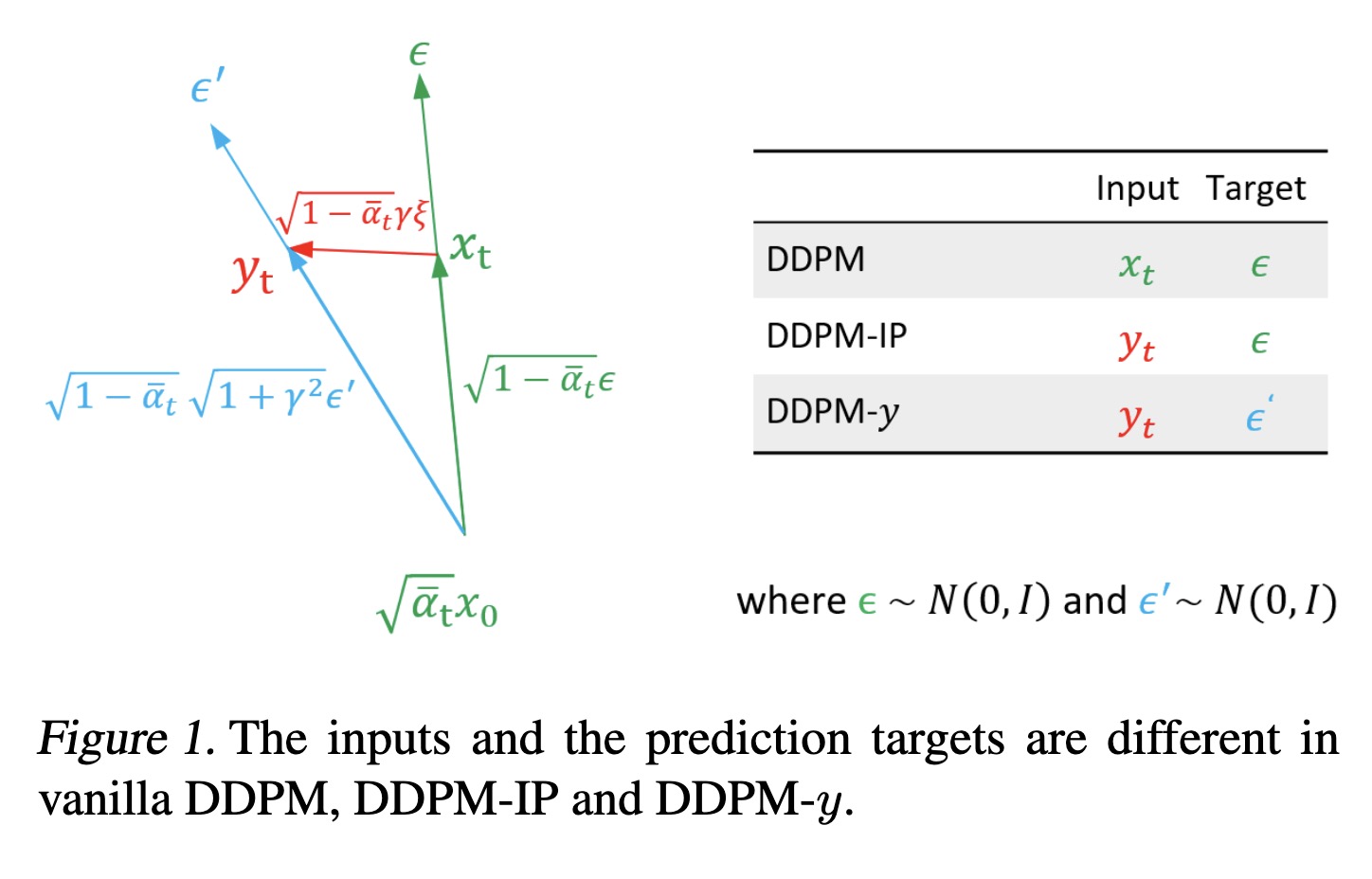
Paper: http://arxiv.org/abs/2301.11706
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The inputs and the prediction t…
0
1
0
Fahim Farook
f
"Image Restoration with Mean-Reverting Stochastic Differential Equations. (arXiv:2301.11699v1 [cs.LG])" — A stochastic differential equation (SDE) approach for general-purpose image restoration which can restore images without relying on any task-specific prior knowledge.
Paper: http://arxiv.org/abs/2301.11699
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An overview of our proposed con…

Paper: http://arxiv.org/abs/2301.11699
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An overview of our proposed con…
0
1
0
Fahim Farook
f
"Accelerating Guided Diffusion Sampling with Splitting Numerical Methods. (arXiv:2301.11558v1 [cs.CV])" — A solution to speeding up guided diffusion image generation based on operator splitting methods, motivated by the finding that classical high-order numerical methods are unsuitable for the conditional function.
Paper: http://arxiv.org/abs/2301.11558
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Generated samples of a classifi…
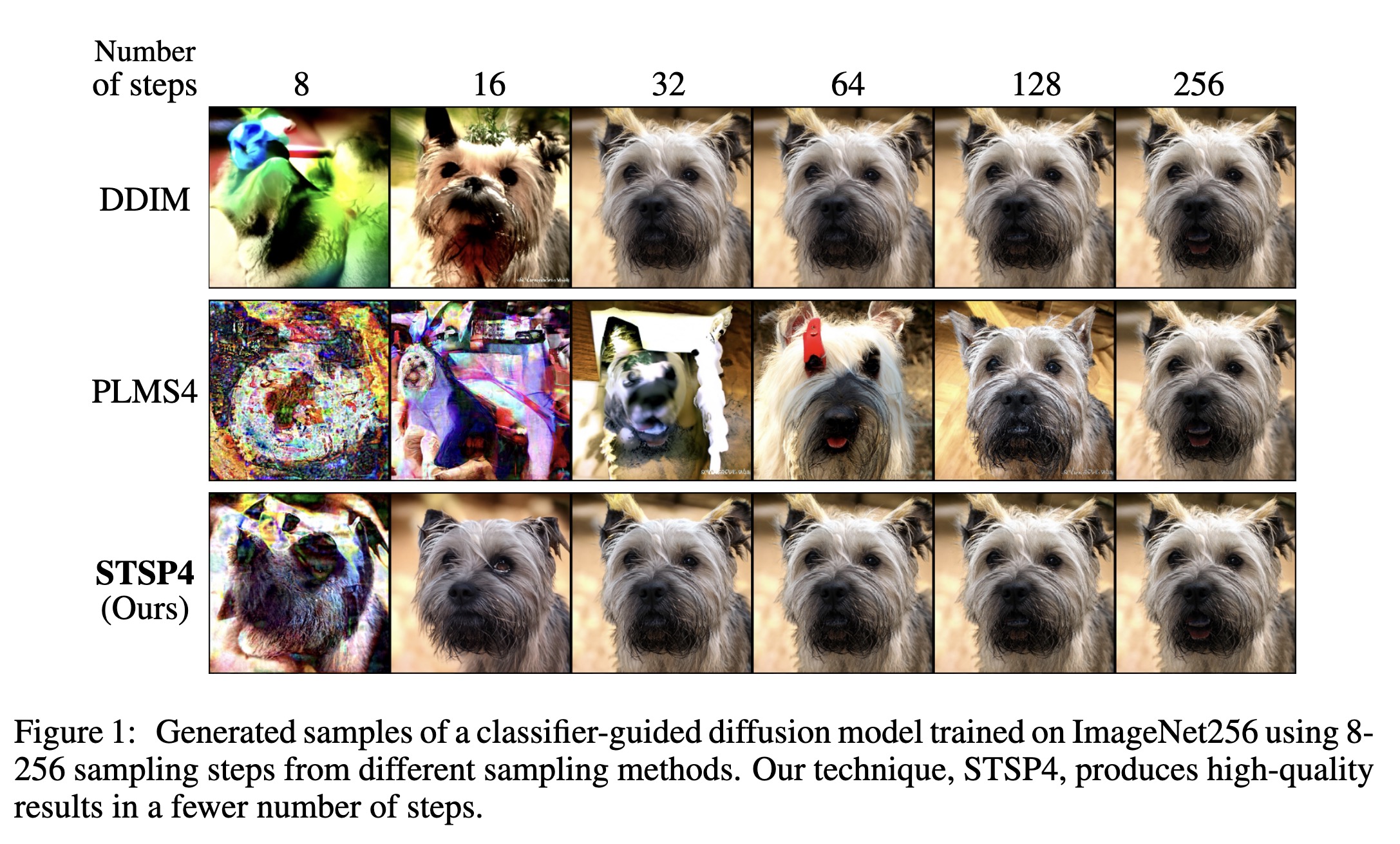
Paper: http://arxiv.org/abs/2301.11558
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Generated samples of a classifi…
0
1
0
Fahim Farook
f
"3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models. (arXiv:2301.11445v1 [cs.CV])" — A novel shape representation for neural fields designed for generative diffusion models, which can encode 3D shapes given as surface models or point clouds, and represents them as neural fields.
Paper: http://arxiv.org/abs/2301.11445
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: Shape autoencoding result…
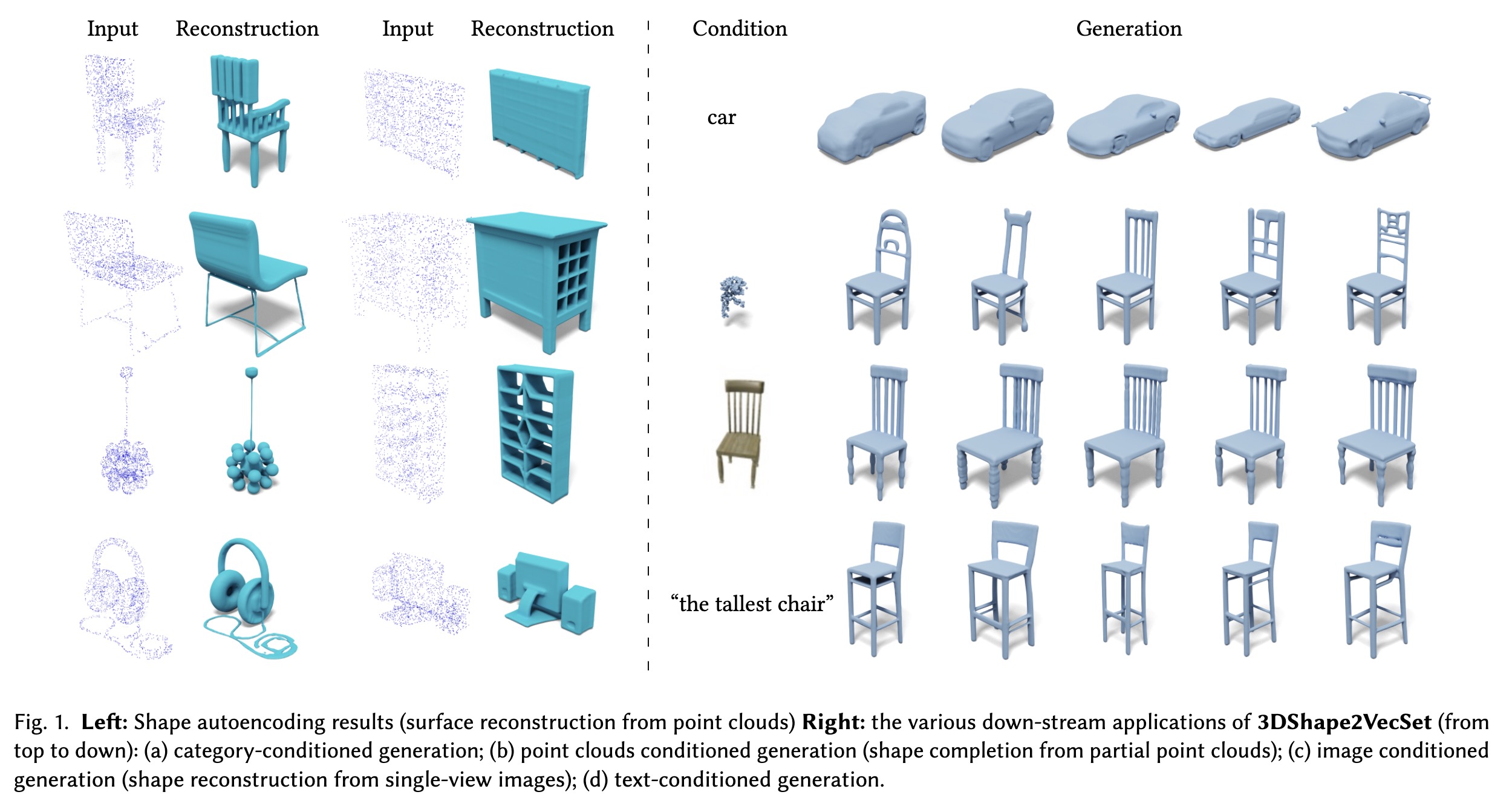
Paper: http://arxiv.org/abs/2301.11445
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: Shape autoencoding result…
0
1
0
Fahim Farook
f
"Improving Cross-modal Alignment for Text-Guided Image Inpainting. (arXiv:2301.11362v1 [cs.CV])" — A model for text-guided image inpainting by improving cross-modal alignment (CMA) using cross-modal alignment distillation and in-sample distribution distillation.
Paper: http://arxiv.org/abs/2301.11362
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Different categories of vision-…
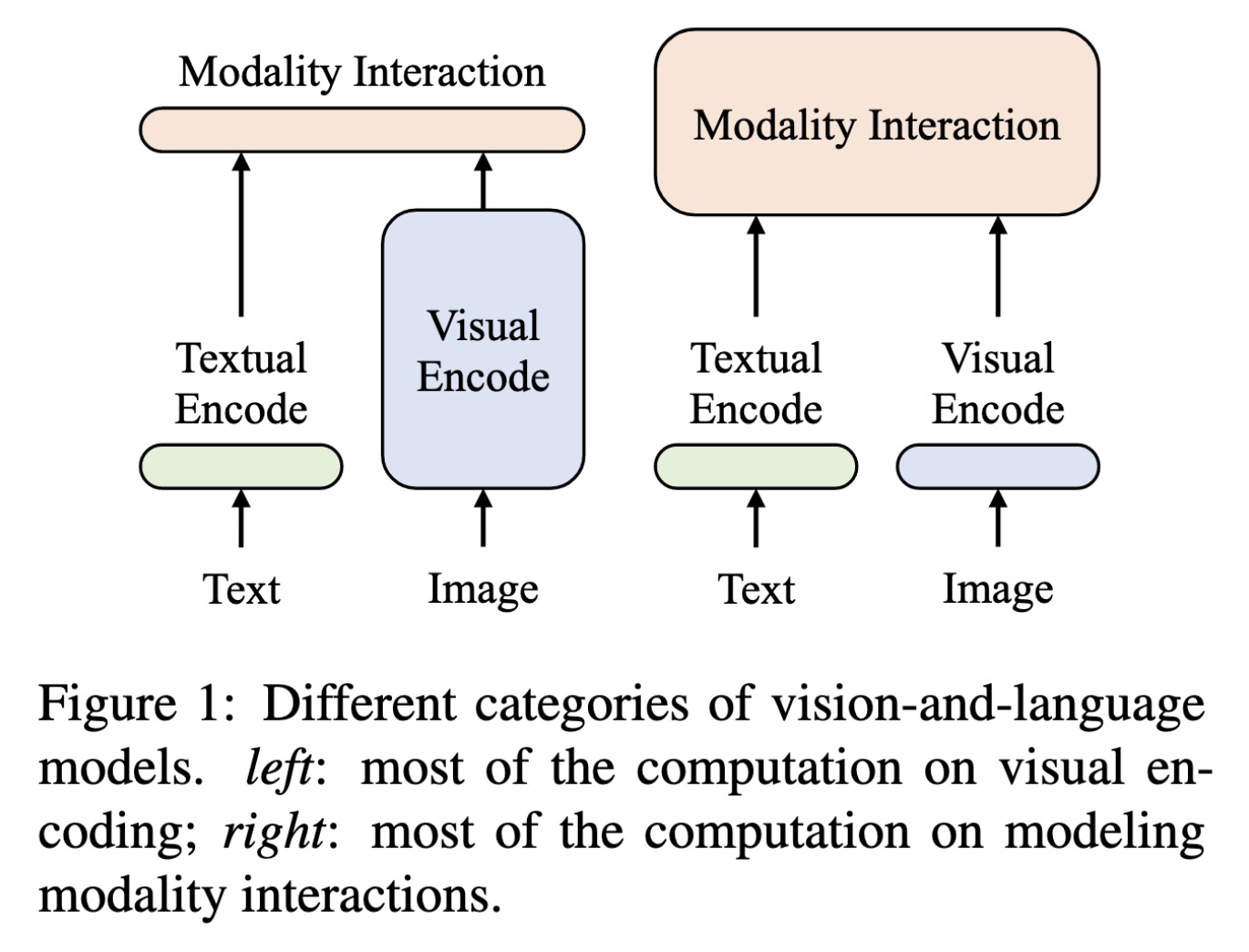
Paper: http://arxiv.org/abs/2301.11362
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Different categories of vision-…
0
1
0
Fahim Farook
f
"Rethinking 1x1 Convolutions: Can we train CNNs with Frozen Random Filters?. (arXiv:2301.11360v1 [cs.CV])" — An exploration into whether Convolutional Neural Networks (CNN) learning the weights of vast numbers of convolutional operators is really necessary.
Paper: http://arxiv.org/abs/2301.11360
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Validation accuracy of LCResNet…
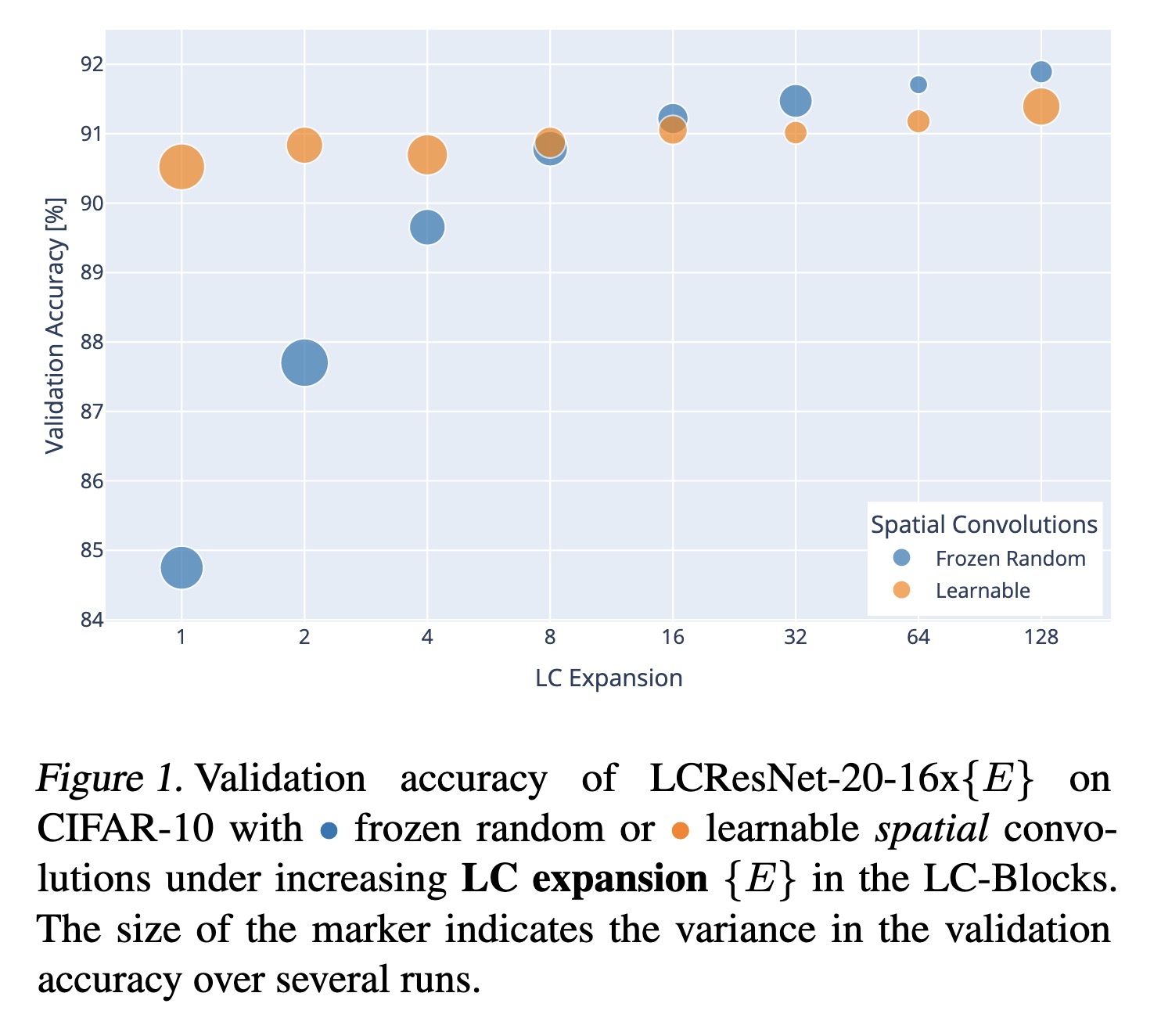
Paper: http://arxiv.org/abs/2301.11360
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Validation accuracy of LCResNet…
0
4
4
Fahim Farook
f
"Multimodal Event Transformer for Image-guided Story Ending Generation. (arXiv:2301.11357v1 [cs.CV])" — A multimodal event transformer, an event-based reasoning framework for image-guided story ending generation which constructs visual and semantic event graphs from story plots and ending image, and leverages event-based reasoning to reason and mine implicit information in a single modality.
Paper: http://arxiv.org/abs/2301.11357
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given a multi-sentence story pl…

Paper: http://arxiv.org/abs/2301.11357
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given a multi-sentence story pl…
0
3
2
Fahim Farook
f
"Animating Still Images. (arXiv:2209.10497v2 [cs.CV] UPDATED)" — A method for imparting motion to a still 2D image which uses deep learning to segment part of the image as the subject, uses in-paining to complete the background, and then adds animation to the subject.
Paper: http://arxiv.org/abs/2209.10497
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Interactive segmentation: Green…

Paper: http://arxiv.org/abs/2209.10497
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Interactive segmentation: Green…
0
1
1
Fahim Farook
f
"VAuLT: Augmenting the Vision-and-Language Transformer for Sentiment Classification on Social Media. (arXiv:2208.09021v3 [cs.CV] UPDATED)" — An extension of the popular Vision-and-Language Transformer (ViLT) to improve performance on vision-and-language (VL) tasks that involve more complex text inputs than image captions while having minimal impact on training and inference efficiency.
Paper: http://arxiv.org/abs/2208.09021
Code: https://github.com/gchochla/vault
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VAuLT propagates representation…
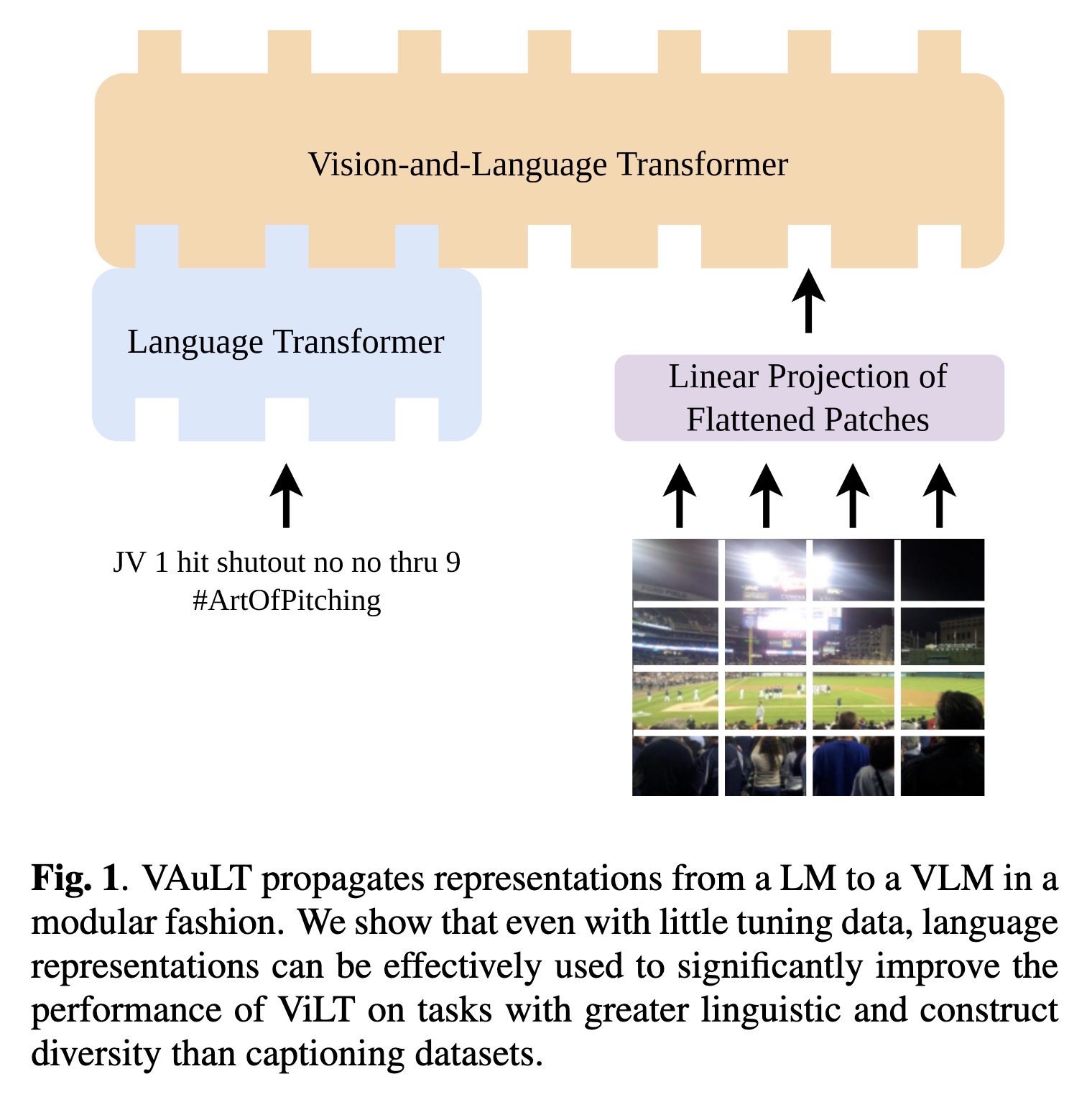
Paper: http://arxiv.org/abs/2208.09021
Code: https://github.com/gchochla/vault
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VAuLT propagates representation…
0
1
0
Fahim Farook
f
"SIViDet: Salient Image for Efficient Weaponized Violence Detection. (arXiv:2207.12850v4 [cs.CV] UPDATED)" — A new dataset that contains videos depicting weaponized violence, non-weaponized violence, and non-violent events; and a proposal for a novel data-centric method that arranges video frames into salient images while minimizing information loss for comfortable inference by SOTA image classifiers.
Paper: http://arxiv.org/abs/2207.12850
Code: https://github.com/Ti-Oluwanimi/Violence_Detection
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Salient Image: A sequence of vi…

Paper: http://arxiv.org/abs/2207.12850
Code: https://github.com/Ti-Oluwanimi/Violence_Detection
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Salient Image: A sequence of vi…
0
1
0
Fahim Farook
f
"BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning. (arXiv:2206.08657v3 [cs.CV] UPDATED)" — A proposal for multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder.
Paper: http://arxiv.org/abs/2206.08657
Code: https://github.com/microsoft/BridgeTower
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) – (d) are four categories o…
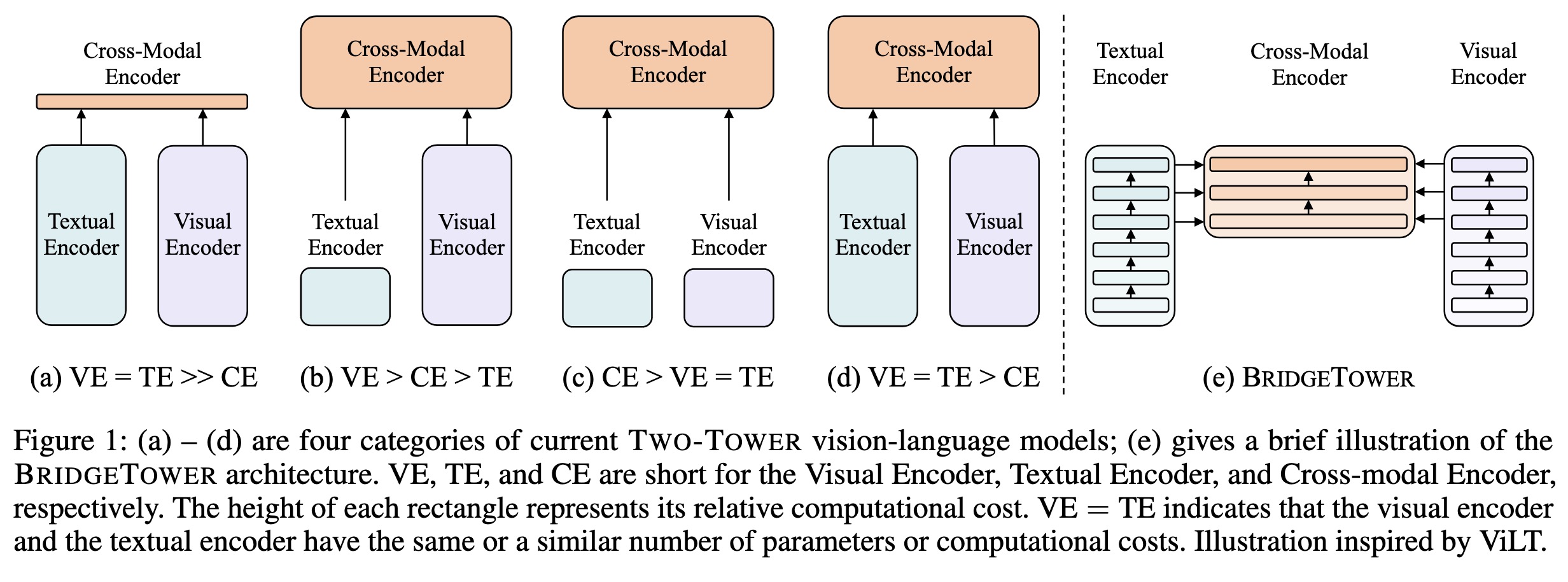
Paper: http://arxiv.org/abs/2206.08657
Code: https://github.com/microsoft/BridgeTower
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) – (d) are four categories o…
0
1
0
Fahim Farook
f
"Text-To-4D Dynamic Scene Generation. (arXiv:2301.11280v1 [cs.CV])" — A method for generating three-dimensional dynamic scenes from text descriptions which uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by querying a Text-to-Video (T2V) diffusion-based model.
Paper: http://arxiv.org/abs/2301.11280
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by MAV3D alon…
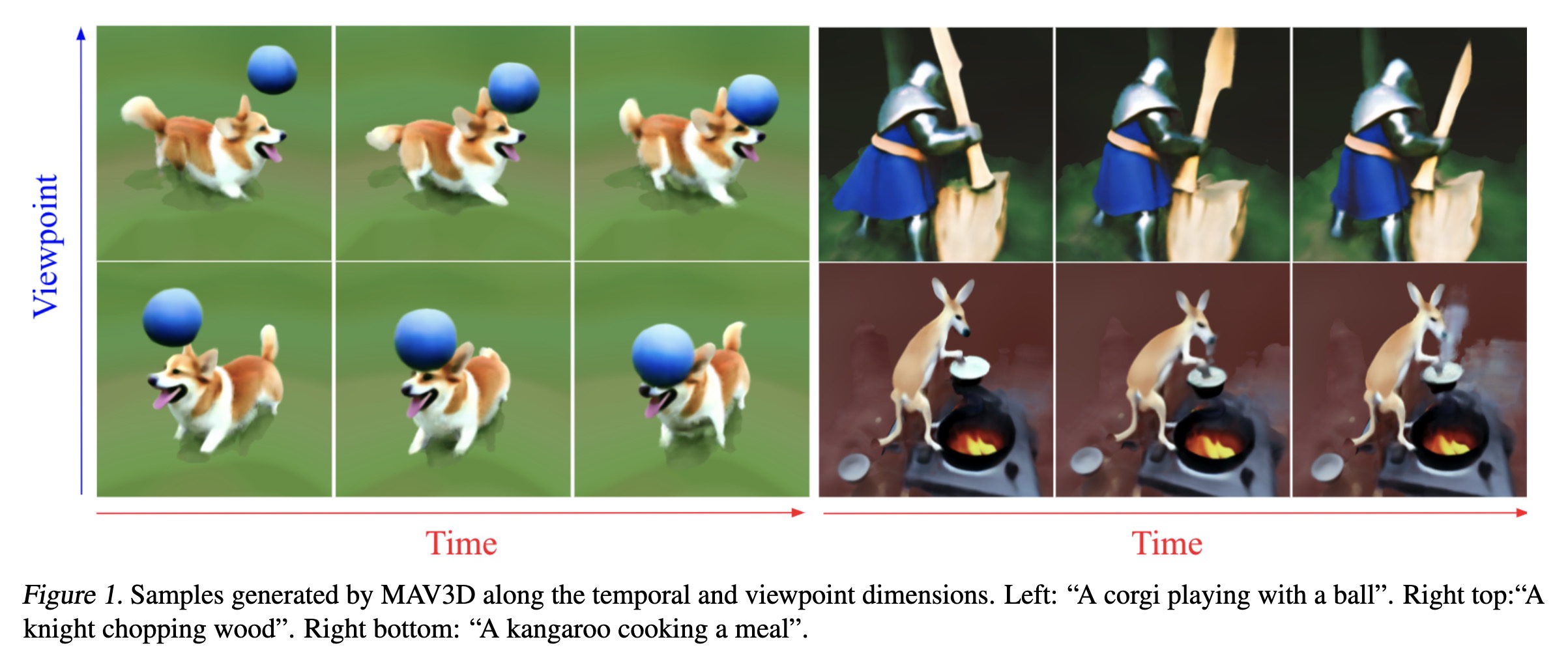
Paper: http://arxiv.org/abs/2301.11280
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by MAV3D alon…
0
1
1