Fahim Farook
Posts
1641Following
139Followers
887I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"BiBench: Benchmarking and Analyzing Network Binarization. (arXiv:2301.11233v1 [cs.CV])" — A rigorously designed benchmark with in-depth analysis for network binarization where they scrutinize the requirements of binarization in the actual production and define evaluation tracks and metrics for a comprehensive investigation.
Paper: http://arxiv.org/abs/2301.11233
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Evaluation tracks of BiBench. O…
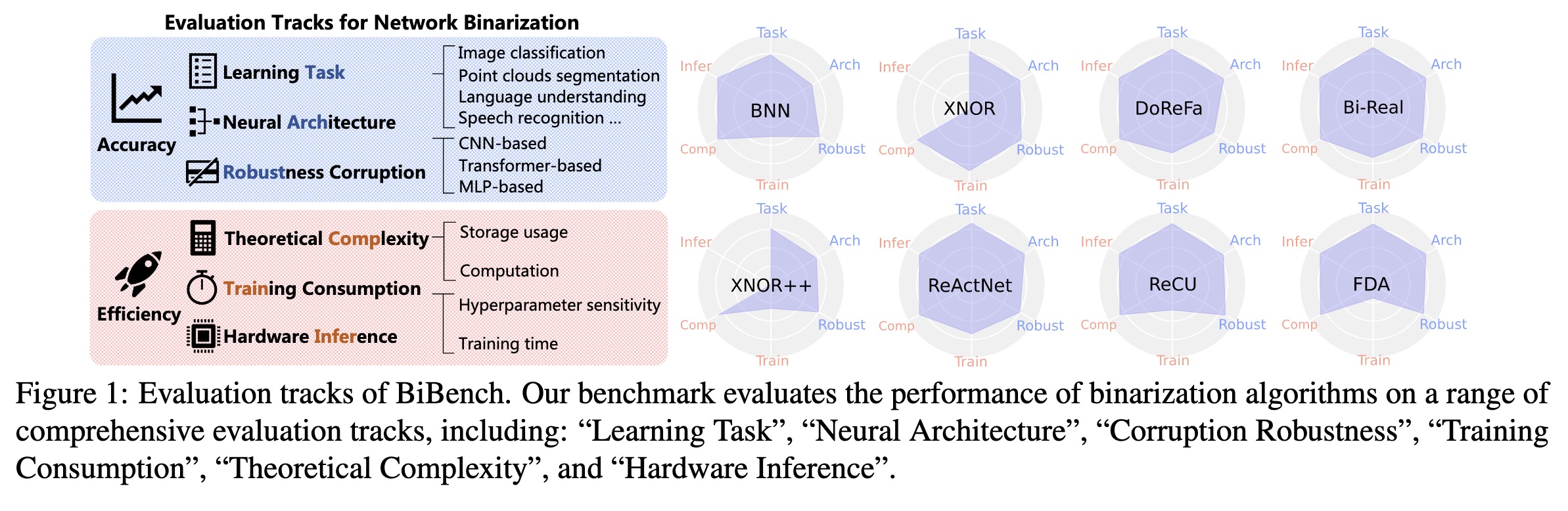
Paper: http://arxiv.org/abs/2301.11233
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Evaluation tracks of BiBench. O…
 0
0
 1
1
 0
0
Fahim Farook
f
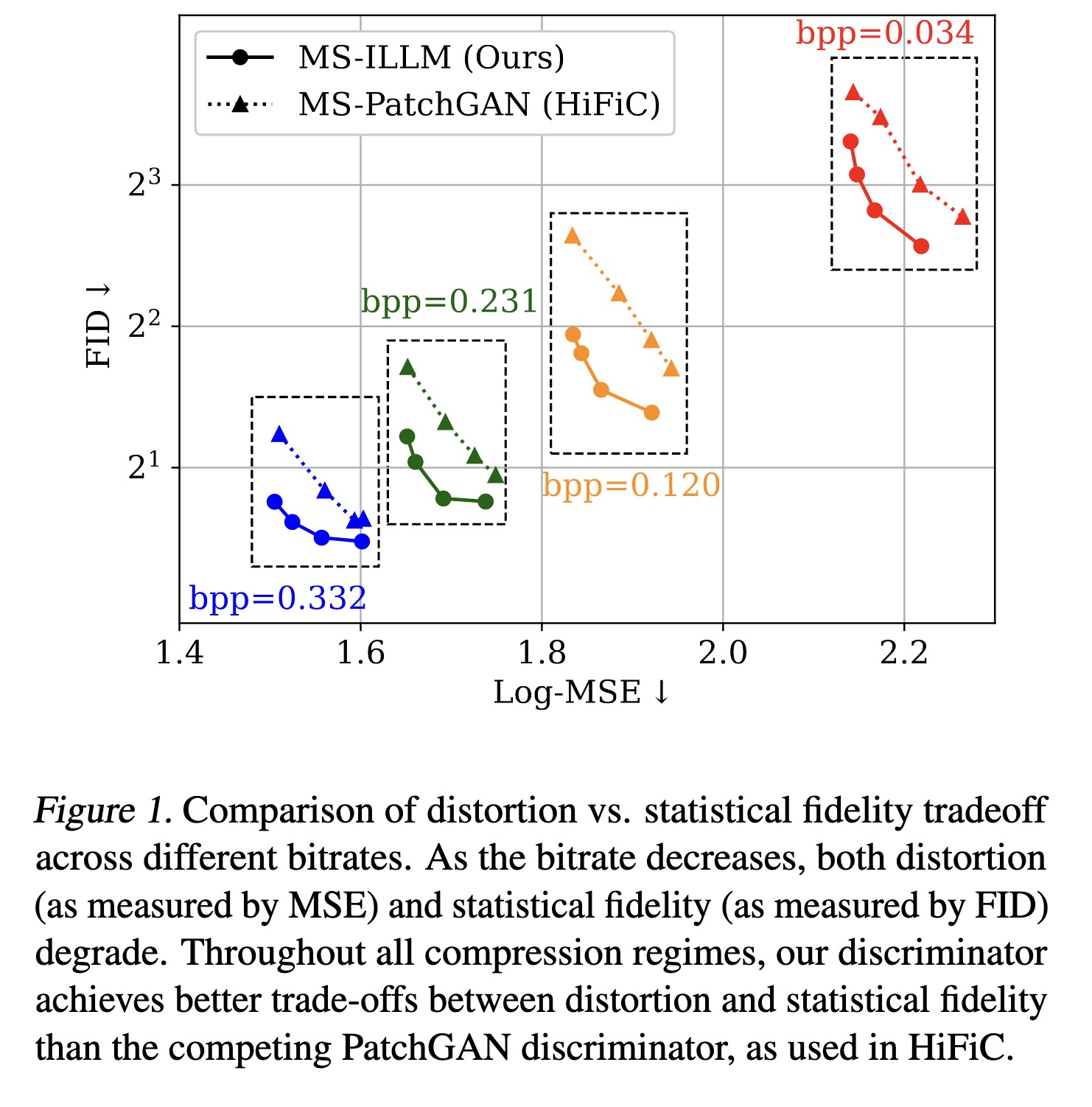
"Improving Statistical Fidelity for Neural Image Compression with Implicit Local Likelihood Models. (arXiv:2301.11189v1 [eess.IV])" — A non-binary discriminator that is conditioned on quantized local image representations obtained via VQ-VAE autoencoders, for lossy image compression.
Paper: http://arxiv.org/abs/2301.11189
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of distortion vs. st…
Paper: http://arxiv.org/abs/2301.11189
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of distortion vs. st…
0
0
0
Fahim Farook
f
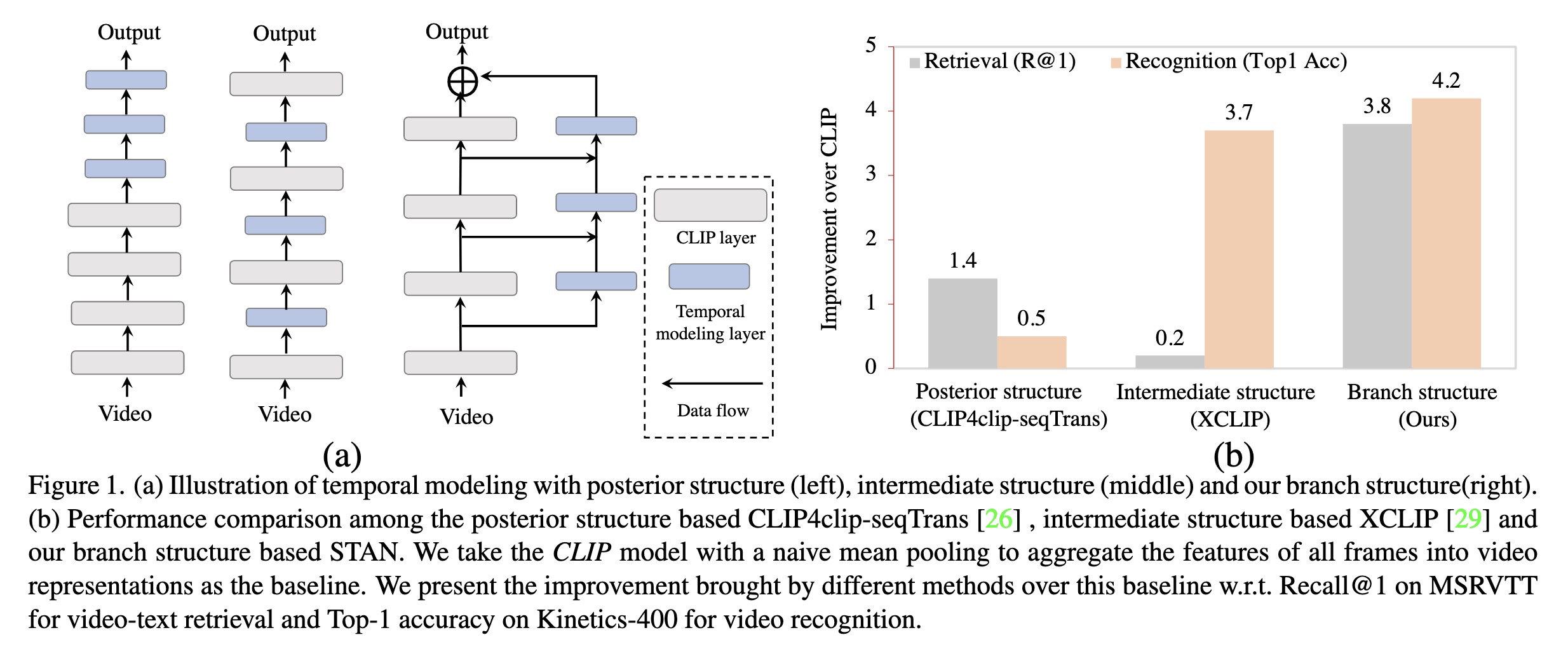
"Revisiting Temporal Modeling for CLIP-based Image-to-Video Knowledge Transferring. (arXiv:2301.11116v1 [cs.CV])" — A look at temporal modeling in the context of image-to-video knowledge transferring, which is the key point for extending image-text pretrained models to the video domain.
Paper: http://arxiv.org/abs/2301.11116
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) Illustration of temporal mo…
Paper: http://arxiv.org/abs/2301.11116
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) Illustration of temporal mo…
0
1
0
Fahim Farook
f
"Explaining Visual Biases as Words by Generating Captions. (arXiv:2301.11104v1 [cs.LG])" — Diagnosing the potential biases in image classifiers by leveraging two types (generative and discriminative) of pre-trained vision-language models to describe the visual bias as a word.
Paper: http://arxiv.org/abs/2301.11104
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of the proposed bias-to…

Paper: http://arxiv.org/abs/2301.11104
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of the proposed bias-to…
0
1
0
Fahim Farook
f
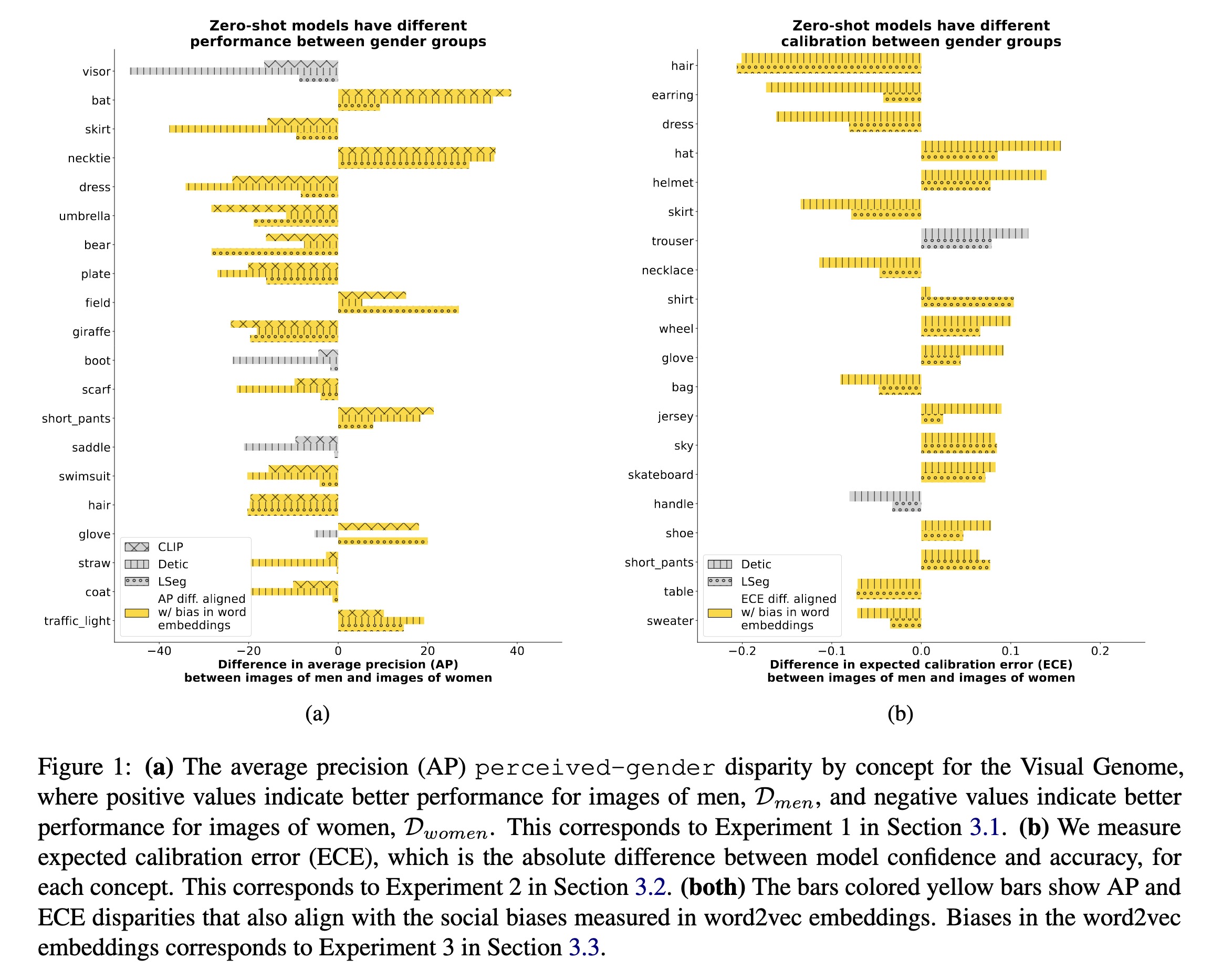
"Vision-Language Models Performing Zero-Shot Tasks Exhibit Gender-based Disparities. (arXiv:2301.11100v1 [cs.CV])" — An exploration of the extent to which zero-shot vision-language models exhibit gender bias for different vision tasks.
Paper: http://arxiv.org/abs/2301.11100
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) The average precision (AP) …
Paper: http://arxiv.org/abs/2301.11100
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) The average precision (AP) …
0
0
0
Fahim Farook
f
"simple diffusion: End-to-end diffusion for high resolution images. (arXiv:2301.11093v1 [cs.CV])" — Improve denoising diffusion for high resolution images while keeping the model as simple as possible and obtaining performance comparable to the latent diffusion-based approaches?
Paper: http://arxiv.org/abs/2301.11093
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A dslr photo of a frog wearing…

Paper: http://arxiv.org/abs/2301.11093
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A dslr photo of a frog wearing…
0
1
1
Fahim Farook
f
"Rewarded meta-pruning: Meta Learning with Rewards for Channel Pruning. (arXiv:2301.11063v1 [cs.CV])" — A method to reduce the parameters and FLOPs for computational efficiency in deep learning models by introducing accuracy and efficiency coefficients to control the trade-off between the accuracy of the network and its computing efficiency.
Paper: http://arxiv.org/abs/2301.11063
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reward at varying Accuracies an…
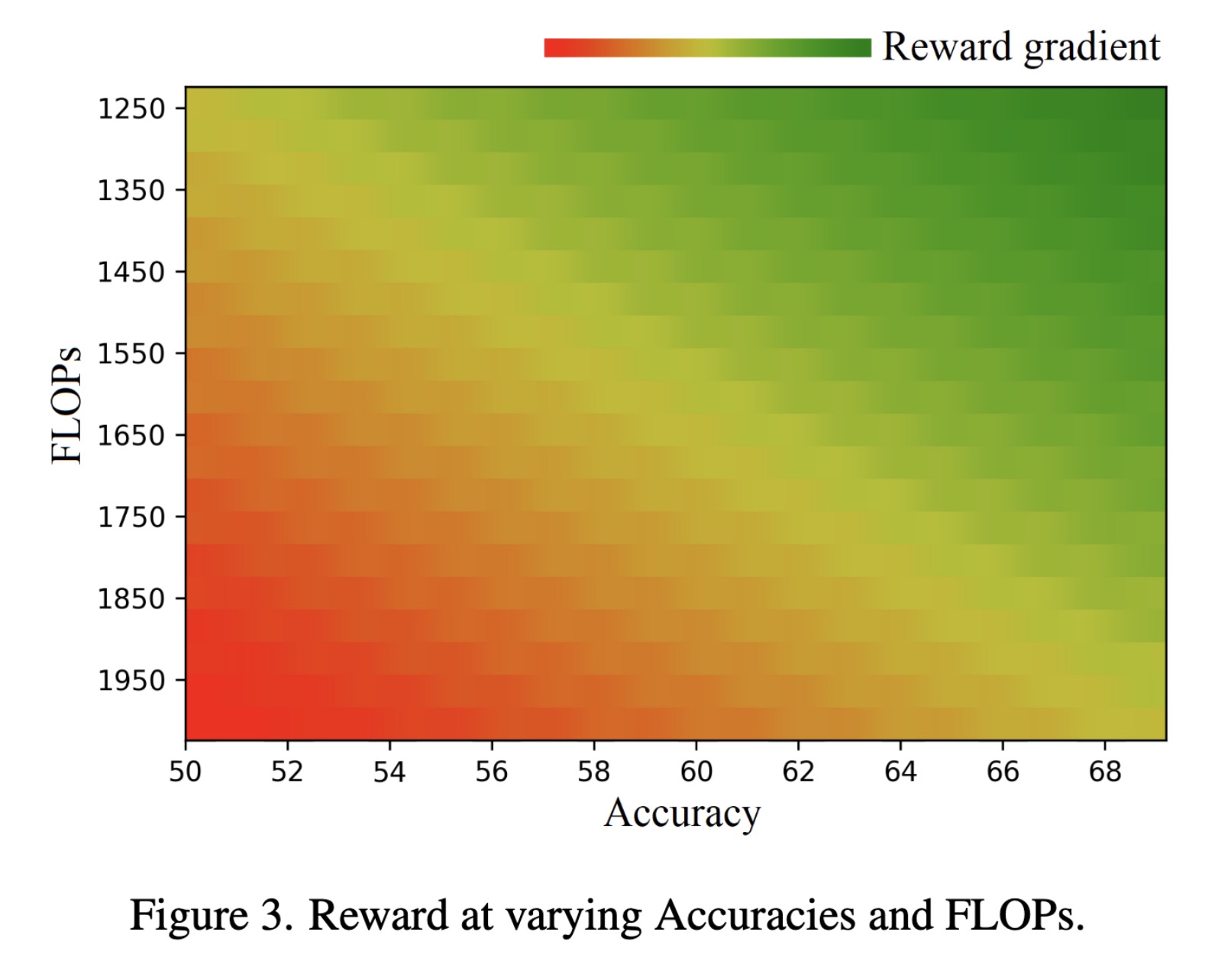
Paper: http://arxiv.org/abs/2301.11063
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reward at varying Accuracies an…
0
1
0
Fahim Farook
f
"Explore the Power of Dropout on Few-shot Learning. (arXiv:2301.11015v1 [cs.CV])" — An exploration of the power of the dropout regularization technique on few-shot learning and provide some insights about how to use it.
Paper: http://arxiv.org/abs/2301.11015
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The generalization power of tra…
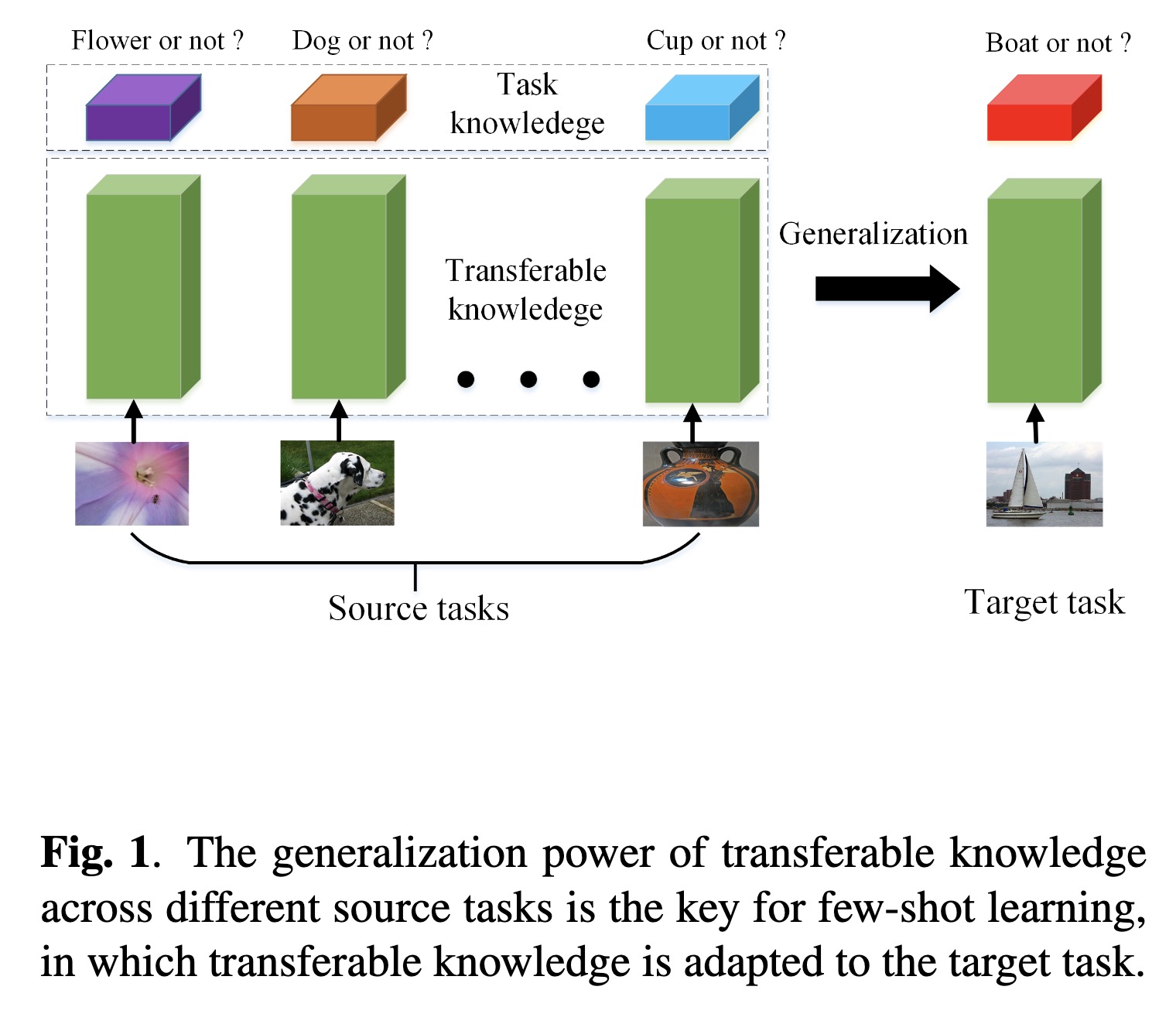
Paper: http://arxiv.org/abs/2301.11015
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The generalization power of tra…
0
1
0
Fahim Farook
f
"On the Importance of Noise Scheduling for Diffusion Models. (arXiv:2301.10972v1 [cs.CV])" — A study of the effect of noise scheduling strategies for denoising diffusion generative models which finds that the noise scheduling is crucial for performance.
Paper: http://arxiv.org/abs/2301.10972
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Random samples generated by our…

Paper: http://arxiv.org/abs/2301.10972
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Random samples generated by our…
0
1
0
Fahim Farook
f
"ITstyler: Image-optimized Text-based Style Transfer. (arXiv:2301.10916v1 [cs.CV])" — A data-efficient text-based style transfer method that does not require optimization at the inference stage where the text input is converted to the style space of the pre-trained VGG network to realize a more effective style swap.
Paper: http://arxiv.org/abs/2301.10916
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview stylization results of…

Paper: http://arxiv.org/abs/2301.10916
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview stylization results of…
0
1
0
Fahim Farook
f
"Distilling Cognitive Backdoor Patterns within an Image. (arXiv:2301.10908v1 [cs.LG])" — A simple method to distill and detect backdoor patterns within an image by extracting the "minimal essence" from an input image responsible for the model's prediction.
Paper: http://arxiv.org/abs/2301.10908
Code: https://github.com/HanxunH/CognitiveDistillation
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
On the left, First row: a clean…

Paper: http://arxiv.org/abs/2301.10908
Code: https://github.com/HanxunH/CognitiveDistillation
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
On the left, First row: a clean…
0
1
0
Fahim Farook
f
"Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners. (arXiv:2108.13161v7 [cs.CL] CROSS LISTED)" — A novel pluggable, extensible, and efficient large-scale pre-trained language model approach which can convert small language models into better few-shot learners without any prompt engineering.
Paper: http://arxiv.org/abs/2108.13161
Code: https://github.com/zjunlp/DART
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of DifferentiA…
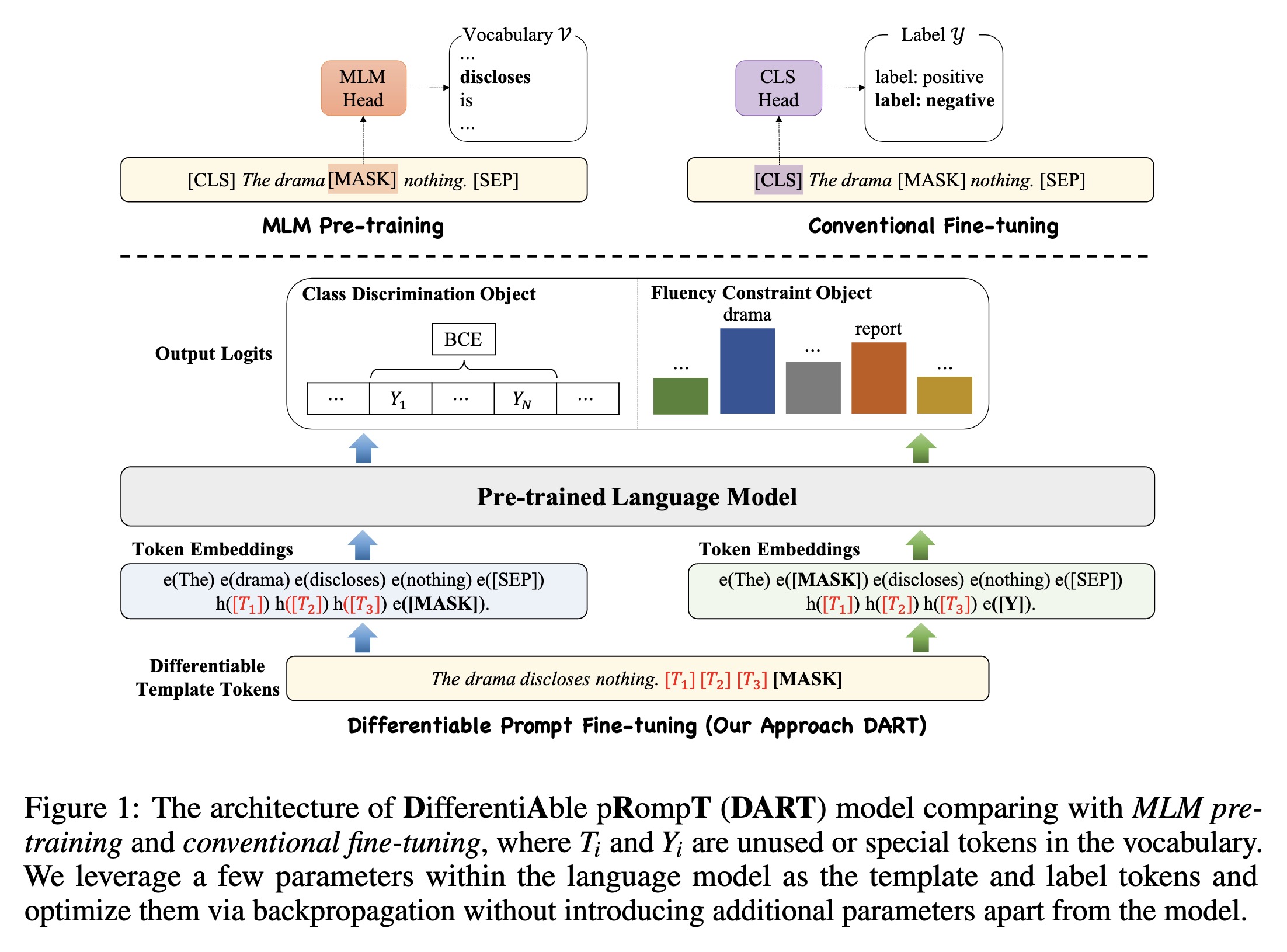
Paper: http://arxiv.org/abs/2108.13161
Code: https://github.com/zjunlp/DART
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of DifferentiA…
0
3
2
Fahim Farook
f
"VN-Transformer: Rotation-Equivariant Attention for Vector Neurons. (arXiv:2206.04176v3 [cs.CV] UPDATED)" — A novel "VN-Transformer" architecture to address several shortcomings of the current Vector Neuron (VN) models.
Paper: http://arxiv.org/abs/2206.04176
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VN-Transformer (“early fusion”)…
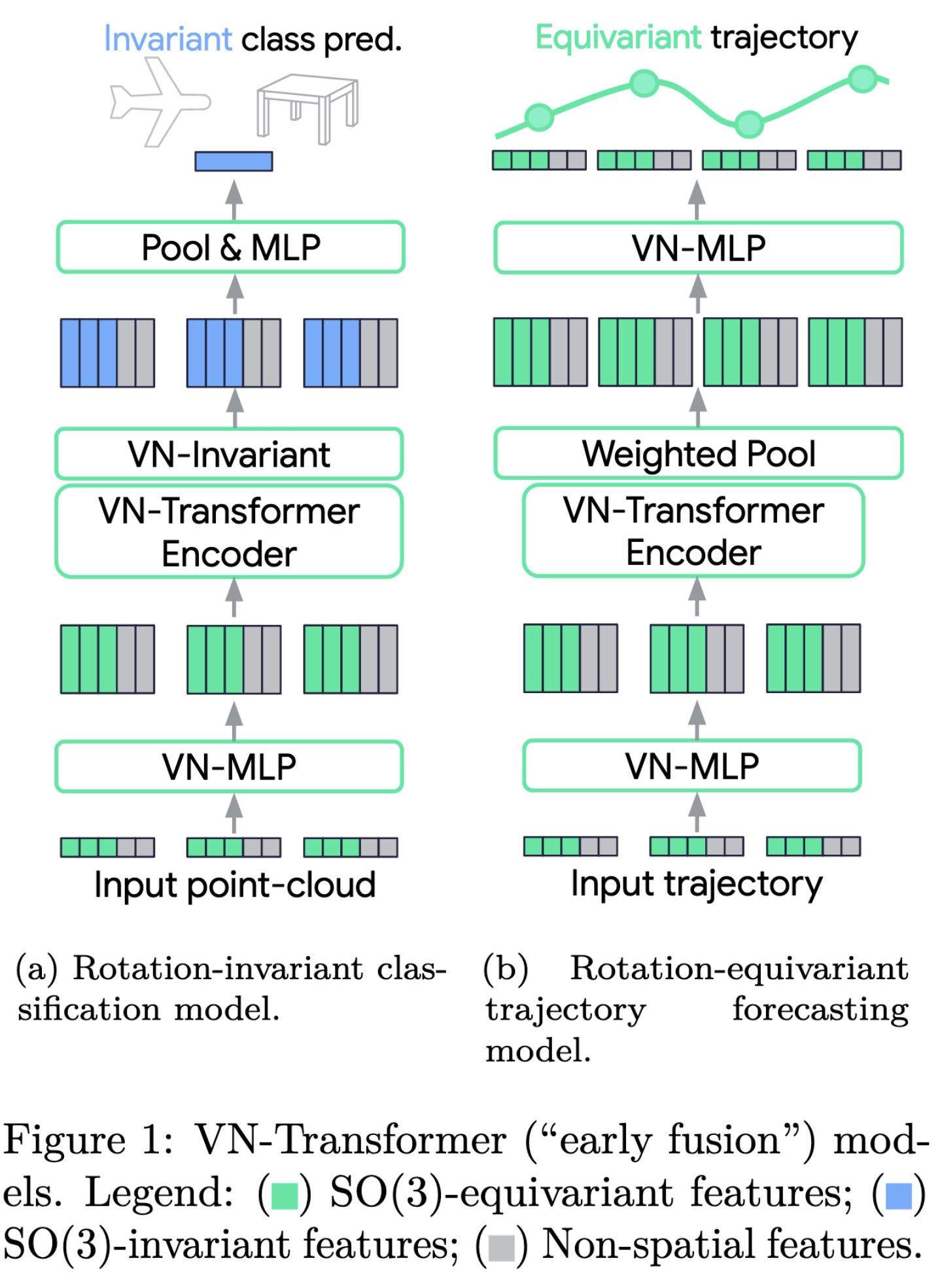
Paper: http://arxiv.org/abs/2206.04176
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VN-Transformer (“early fusion”)…
0
1
0
Fahim Farook
f
"Towards Arbitrary Text-driven Image Manipulation via Space Alignment. (arXiv:2301.10670v1 [cs.CV])" — A new Text-driven image Manipulation framework via Space Alignment (TMSA) which aims to align the same semantic regions in CLIP and StyleGAN spaces so that the text input can be directly accessed into the StyleGAN space and be used to find the semantic shift according to the text description.
Paper: http://arxiv.org/abs/2301.10670
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of image manipulation …

Paper: http://arxiv.org/abs/2301.10670
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of image manipulation …
0
1
0
Fahim Farook
f
"Toward Realistic Evaluation of Deep Active Learning Algorithms in Image Classification. (arXiv:2301.10625v1 [cs.CV])" — An Active Learning (AL) benchmarking suite and a set of extensive experiments on five datasets shedding light on the questions: when and how to apply AL.
Paper: http://arxiv.org/abs/2301.10625
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The Active Learning loop featur…
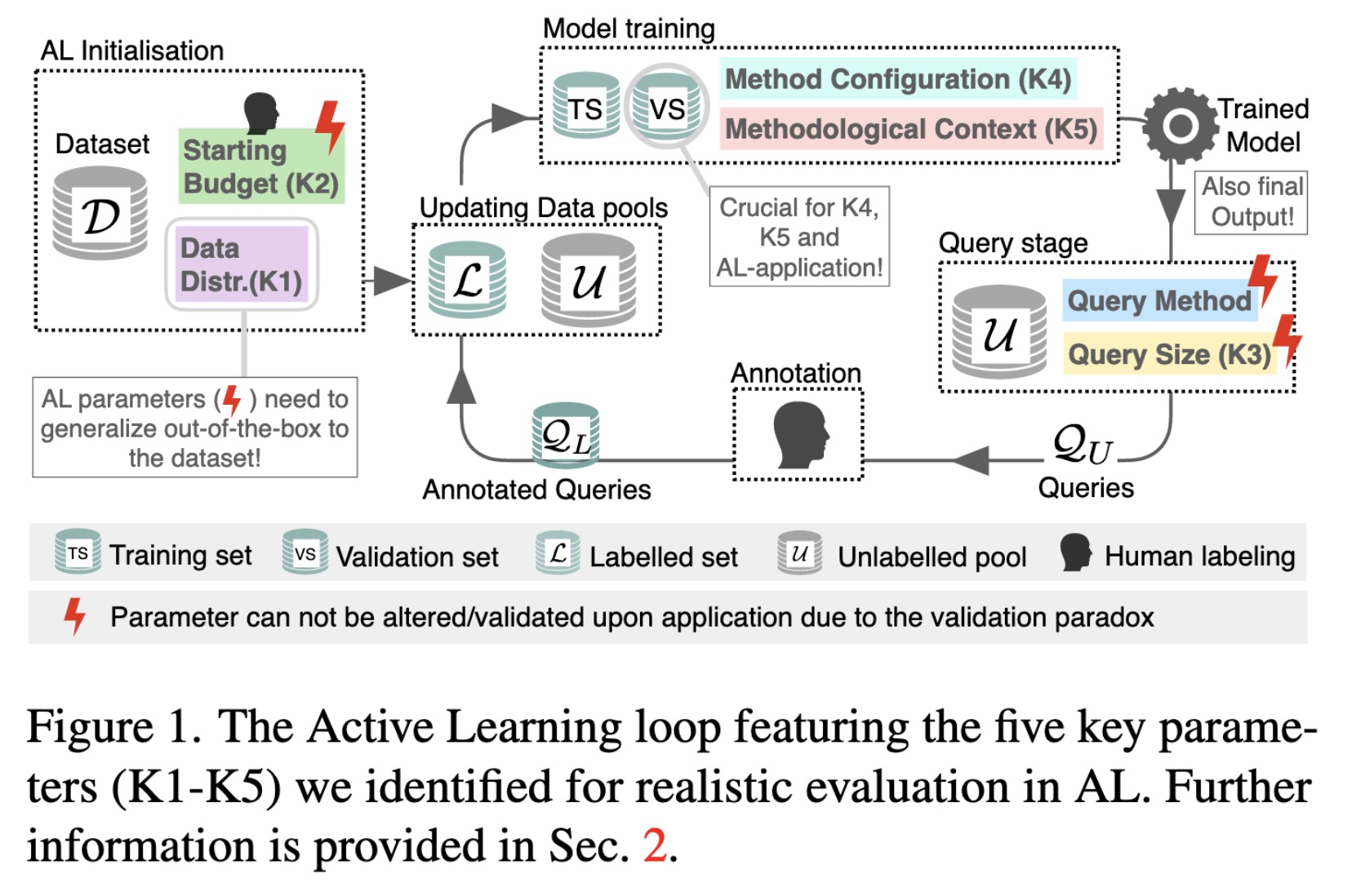
Paper: http://arxiv.org/abs/2301.10625
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The Active Learning loop featur…
0
2
0
Fahim Farook
f
"Variation-Aware Semantic Image Synthesis. (arXiv:2301.10551v1 [cs.CV])" — A new requirement for semantic image synthesis (SIS) to achieve more photorealistic images, variation-aware, which consists of inter- and intra-class variation.
Paper: http://arxiv.org/abs/2301.10551
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of class-level mode co…

Paper: http://arxiv.org/abs/2301.10551
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of class-level mode co…
0
1
0
Fahim Farook
f
"DEJA VU: Continual Model Generalization For Unseen Domains. (arXiv:2301.10418v1 [cs.LG])" — A framework that focuses on improving models' target domain generalization (TDG) capability, while also achieving effective target domain adaptation (TDA) capability right after training on certain domains and forgetting alleviation (FA) capability on past domains.
Paper: http://arxiv.org/abs/2301.10418
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of applying our framew…
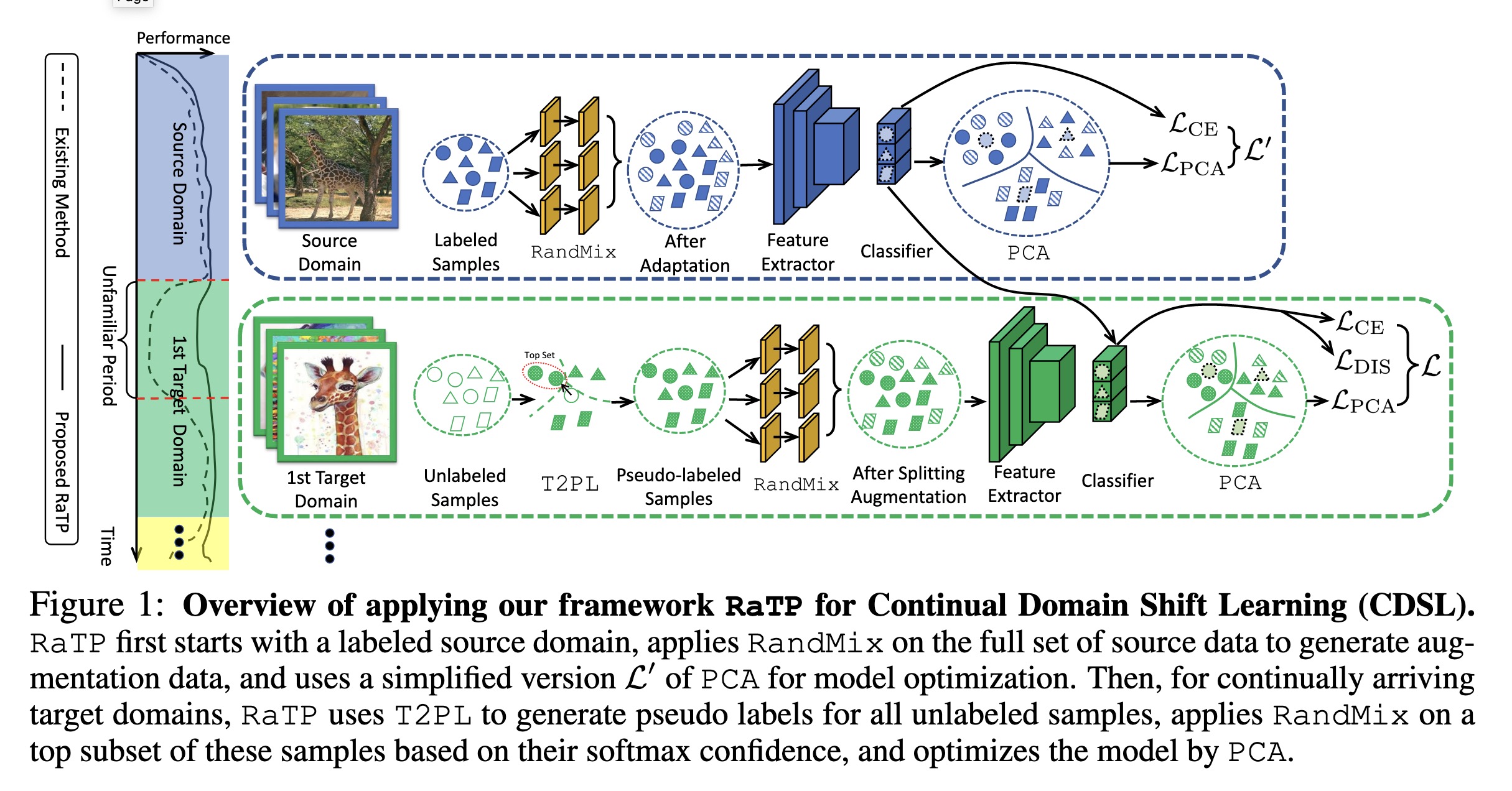
Paper: http://arxiv.org/abs/2301.10418
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of applying our framew…
0
3
1
Fahim Farook
f
"Local Feature Extraction from Salient Regions by Feature Map Transformation. (arXiv:2301.10413v1 [cs.CV])" — A framework that robustly extracts and describes salient local features regardless of changing light and viewpoints by suppressing illumination variations and encouraging structural information to ignore the noise from light and to focus on edges.
Paper: http://arxiv.org/abs/2301.10413
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Proposed framework. Network con…
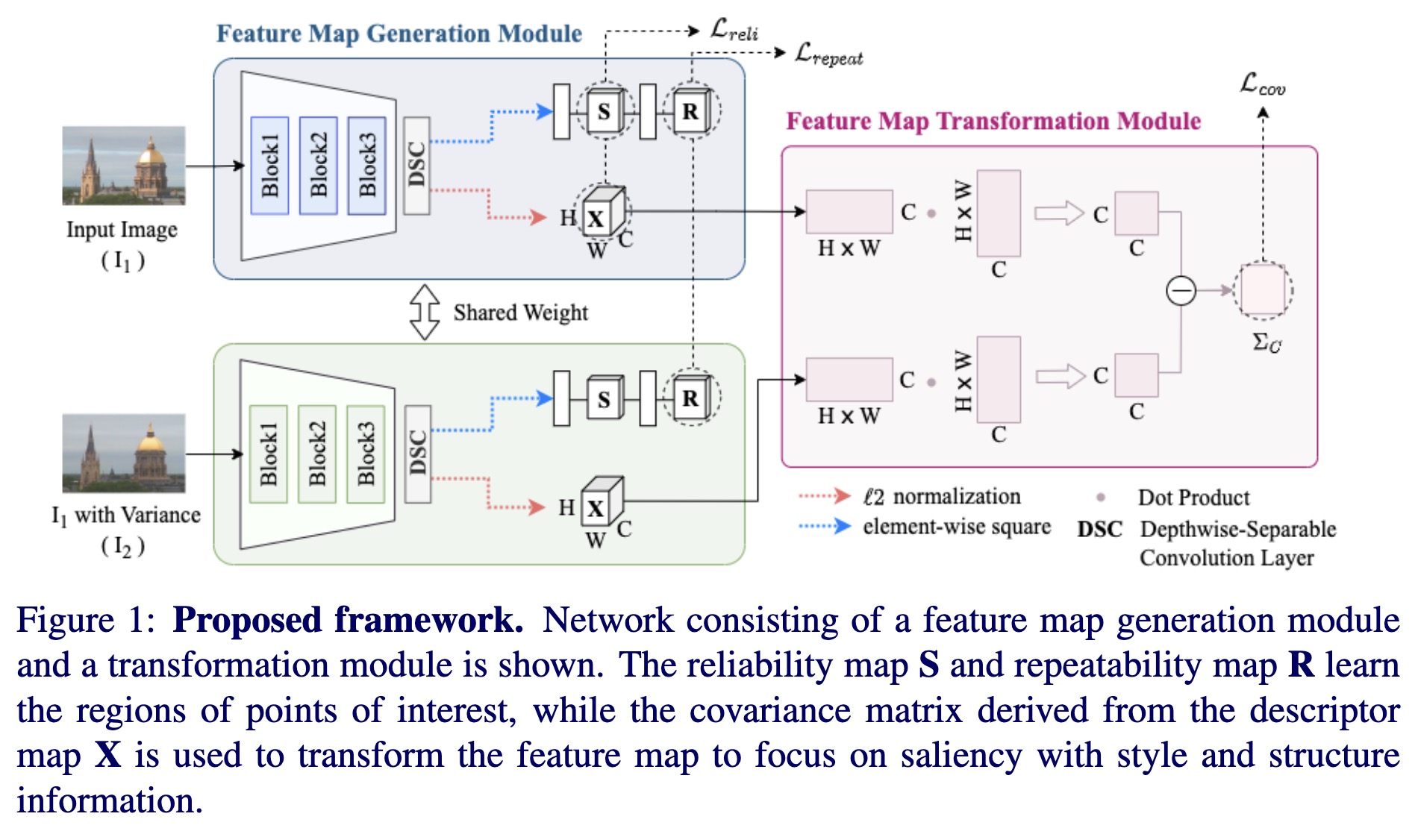
Paper: http://arxiv.org/abs/2301.10413
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Proposed framework. Network con…
0
1
0
Fahim Farook
f
"A Fast Feature Point Matching Algorithm Based on IMU Sensor. (arXiv:2301.10293v1 [cs.CV])" — An algorithm using the inertial measurement unit (IMU) to optimize the efficiency of image feature point matching, in order to reduce the time consumed when matching feature points in simultaneous localization and mapping (SLAM).
Paper: http://arxiv.org/abs/2301.10293
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two adjacent frames. The left i…

Paper: http://arxiv.org/abs/2301.10293
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two adjacent frames. The left i…
0
1
1
Fahim Farook
f
Yesterday's #StableDiffusion prompt was: "Unseen Academicals".
The results were the most diverse and furthest away from anything to do with the original #DiscWorld title that I've gotten so far 🙂 But on the other hand, the prompt is rather abstract ...
I am reaching the end of the DiscWorld title list and it might be time to take a break from DiscWorld and try something else for a few days?
#AIArt #DeepLearning #MachineLearning #CV #AI
Stable Diffusion prompt: "Unsee…
Stable Diffusion prompt: "Unsee…
Stable Diffusion prompt: "Unsee…
Stable Diffusion prompt: "Unsee…




The results were the most diverse and furthest away from anything to do with the original #DiscWorld title that I've gotten so far 🙂 But on the other hand, the prompt is rather abstract ...
I am reaching the end of the DiscWorld title list and it might be time to take a break from DiscWorld and try something else for a few days?
#AIArt #DeepLearning #MachineLearning #CV #AI
Stable Diffusion prompt: "Unsee…
Stable Diffusion prompt: "Unsee…
Stable Diffusion prompt: "Unsee…
Stable Diffusion prompt: "Unsee…
1
1
4