Conversation
Fahim Farook
f
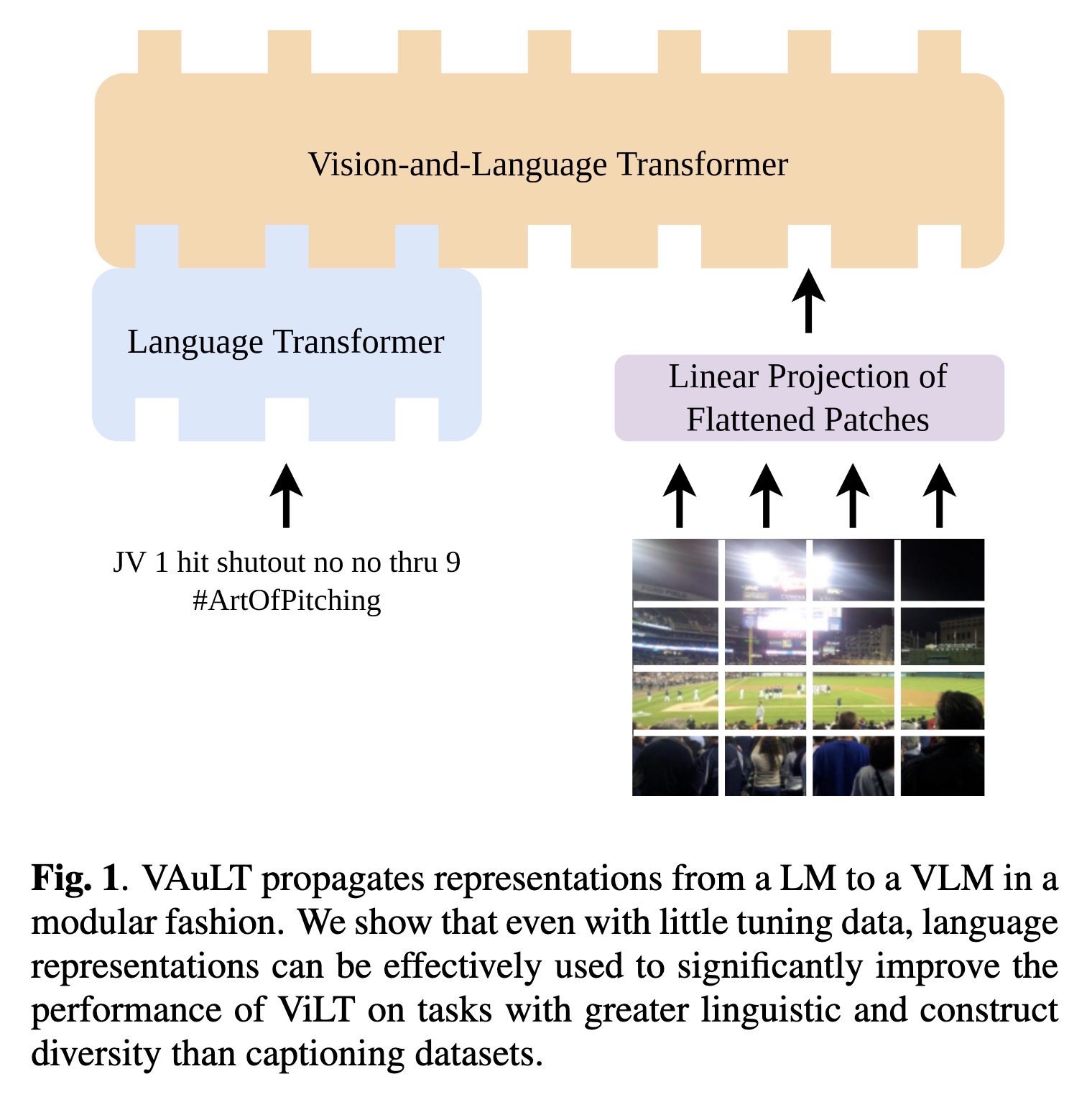
"VAuLT: Augmenting the Vision-and-Language Transformer for Sentiment Classification on Social Media. (arXiv:2208.09021v3 [cs.CV] UPDATED)" — An extension of the popular Vision-and-Language Transformer (ViLT) to improve performance on vision-and-language (VL) tasks that involve more complex text inputs than image captions while having minimal impact on training and inference efficiency.
Paper: http://arxiv.org/abs/2208.09021
Code: https://github.com/gchochla/vault
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VAuLT propagates representation…
Paper: http://arxiv.org/abs/2208.09021
Code: https://github.com/gchochla/vault
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VAuLT propagates representation…
 0
0
 1
1
 0
0