Conversation
Fahim Farook
f
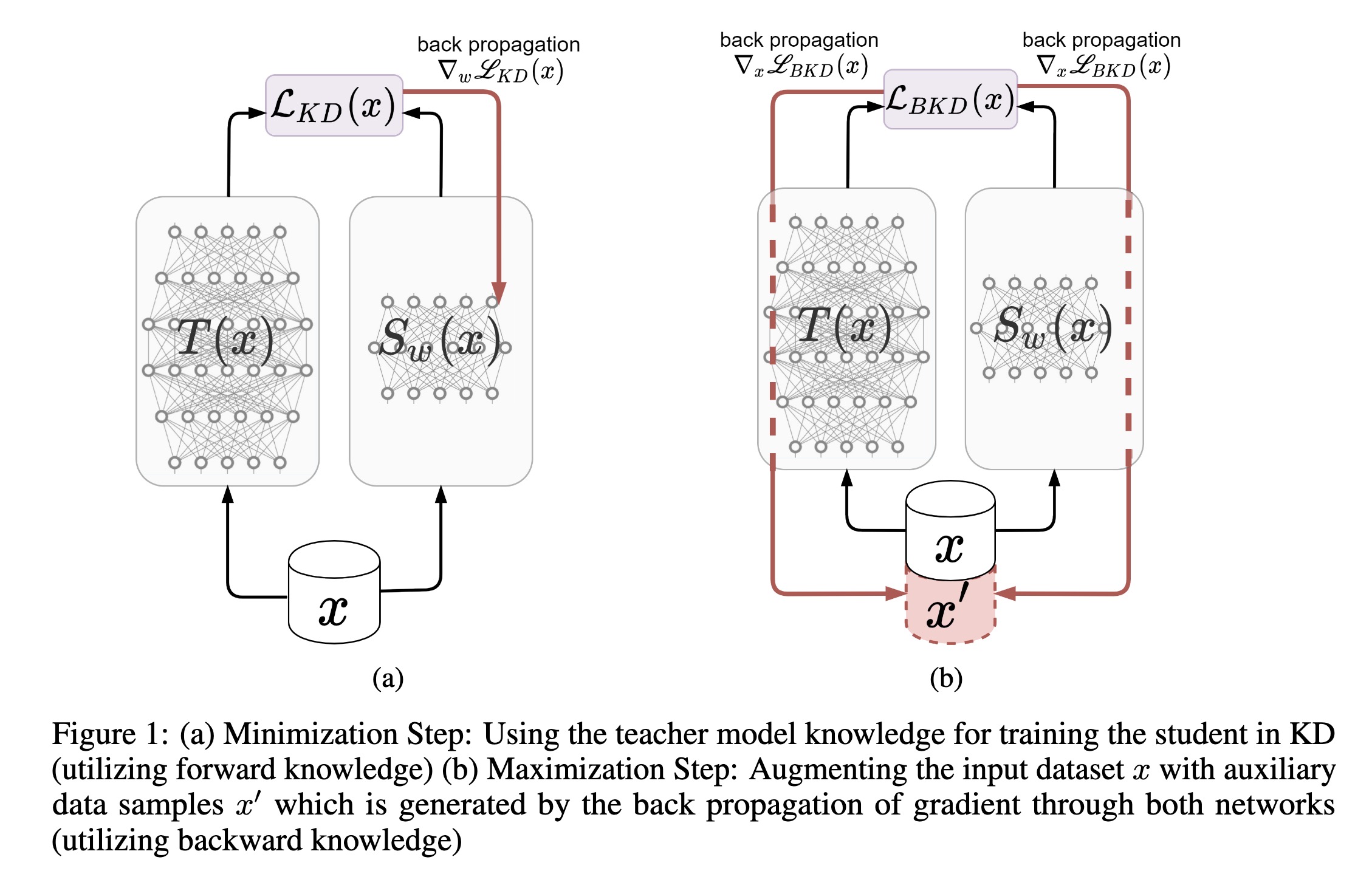
"Improved knowledge distillation by utilizing backward pass knowledge in neural networks. (arXiv:2301.12006v1 [cs.LG])" — Addressing the issue with Knowledge Distillation (KD) where there is no guarantee that the model would match in areas for which you do not have enough training samples, by generating new auxiliary training samples based on extracting knowledge from the backward pass of the teacher in the areas where the student diverges greatly from the teacher.
Paper: http://arxiv.org/abs/2301.12006
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
a) Minimization Step: Using the…
Paper: http://arxiv.org/abs/2301.12006
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
a) Minimization Step: Using the…
 0
0
 1
1
 0
0