Fahim Farook
Posts
1635Following
138Followers
881I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
Edited 3 years ago
Added a couple of extra filtering options to the home timeline in Tusker and suddenly the timeline is that much more manageable 😃
#Tusker #FediClient #iOS #macOS
A screenshot showing a set of f…
#Tusker #FediClient #iOS #macOS
A screenshot showing a set of f…
 1
1
 2
2
 5
5
Fahim Farook
f
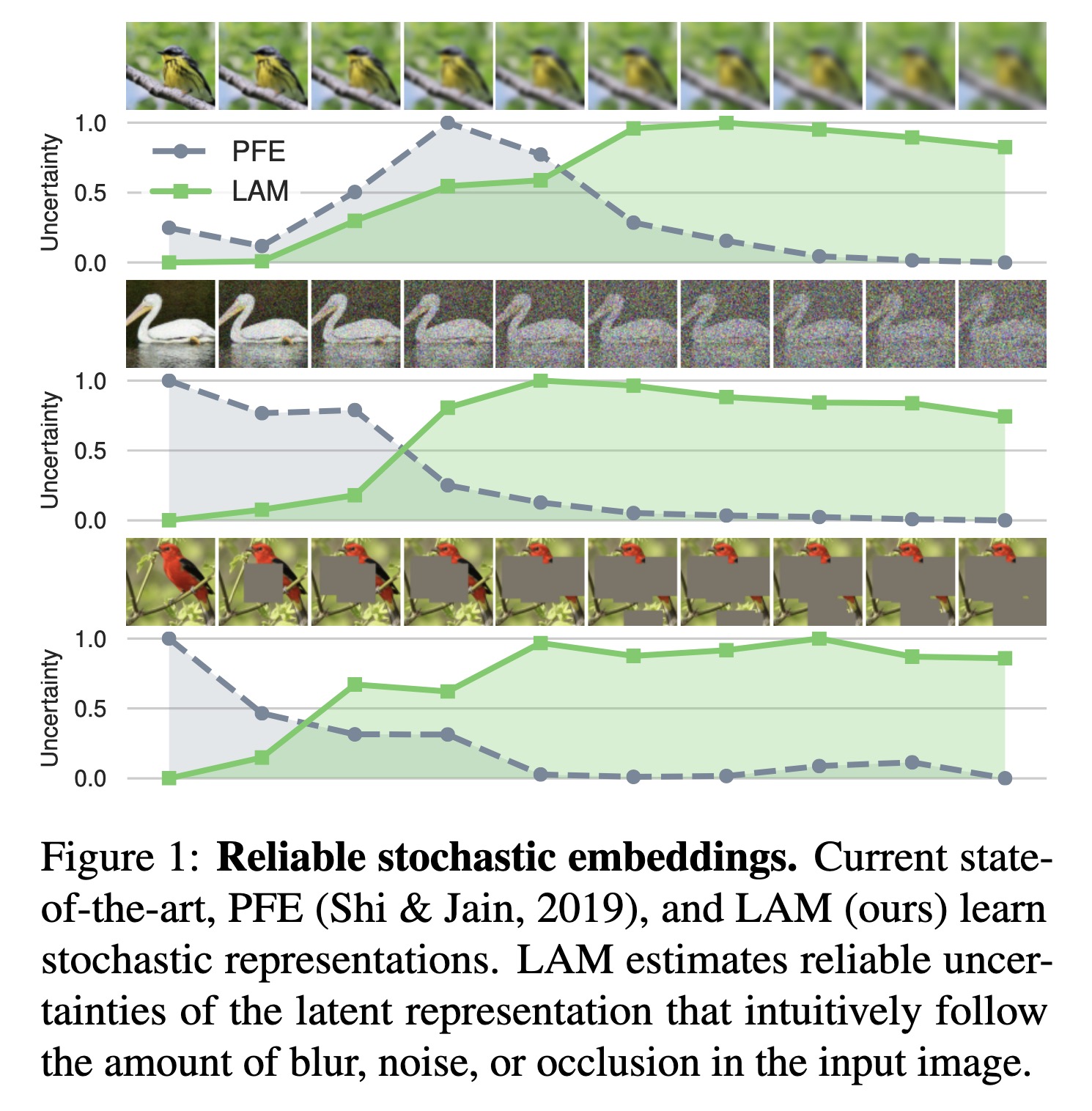
"Bayesian Metric Learning for Uncertainty Quantification in Image Retrieval. (arXiv:2302.01332v1 [cs.LG])" — A Bayesian encoder for metric learning which, rather than relying on neural amortization as done in prior works, learns a distribution over the network weights with the Laplace Approximation.
Paper: http://arxiv.org/abs/2302.01332
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reliable stochastic embeddings.…
Paper: http://arxiv.org/abs/2302.01332
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reliable stochastic embeddings.…
0
1
0
Fahim Farook
f
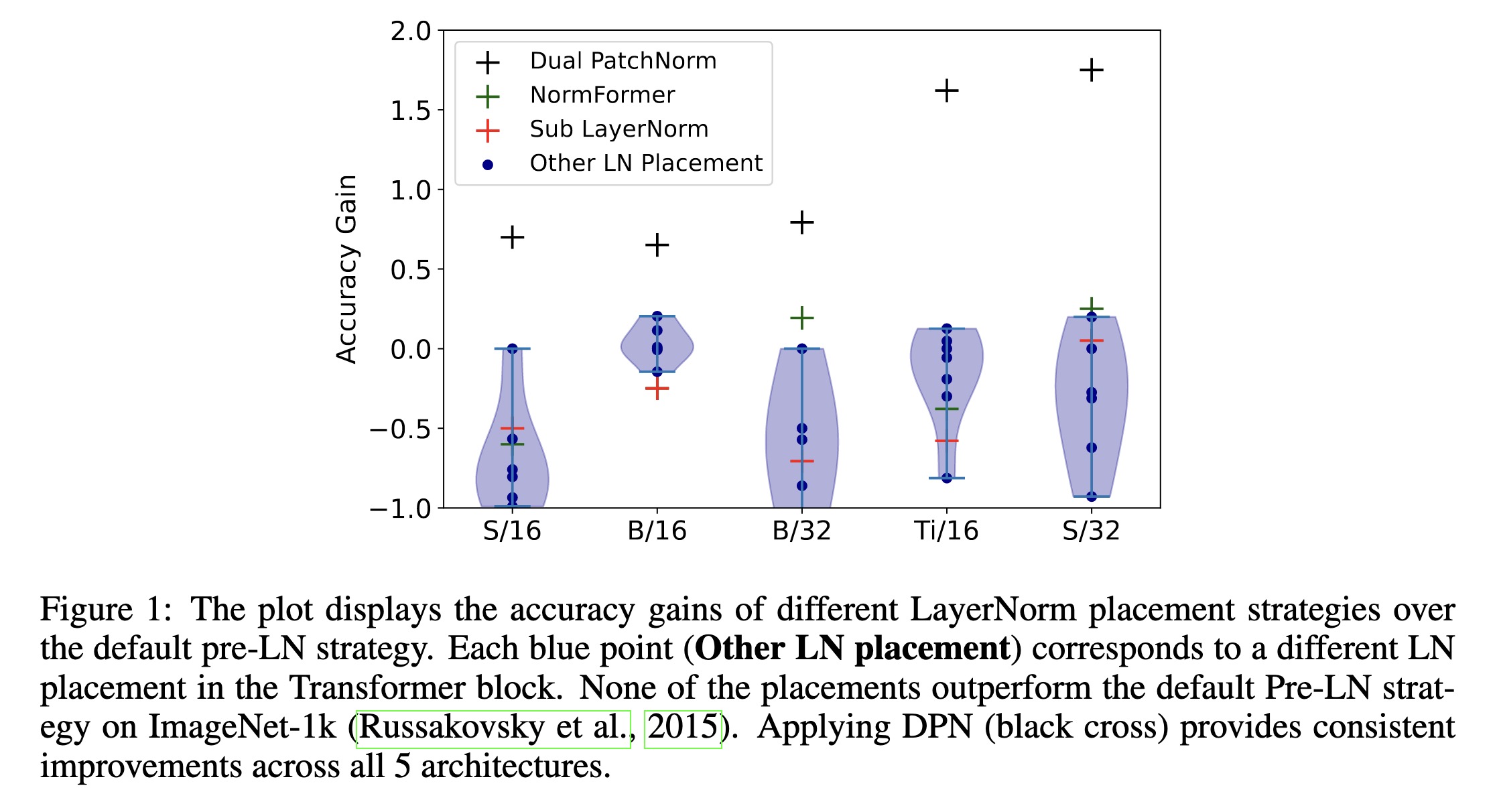
"Dual PatchNorm. (arXiv:2302.01327v1 [cs.CV])" — Experiments with adding two Layer Normalization layers (LayerNorms), before and after the patch embedding layer in Vision Transformers, to see how it affects accuracy.
Paper: http://arxiv.org/abs/2302.01327
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The plot displays the accuracy …
Paper: http://arxiv.org/abs/2302.01327
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The plot displays the accuracy …
0
1
1
Fahim Farook
f
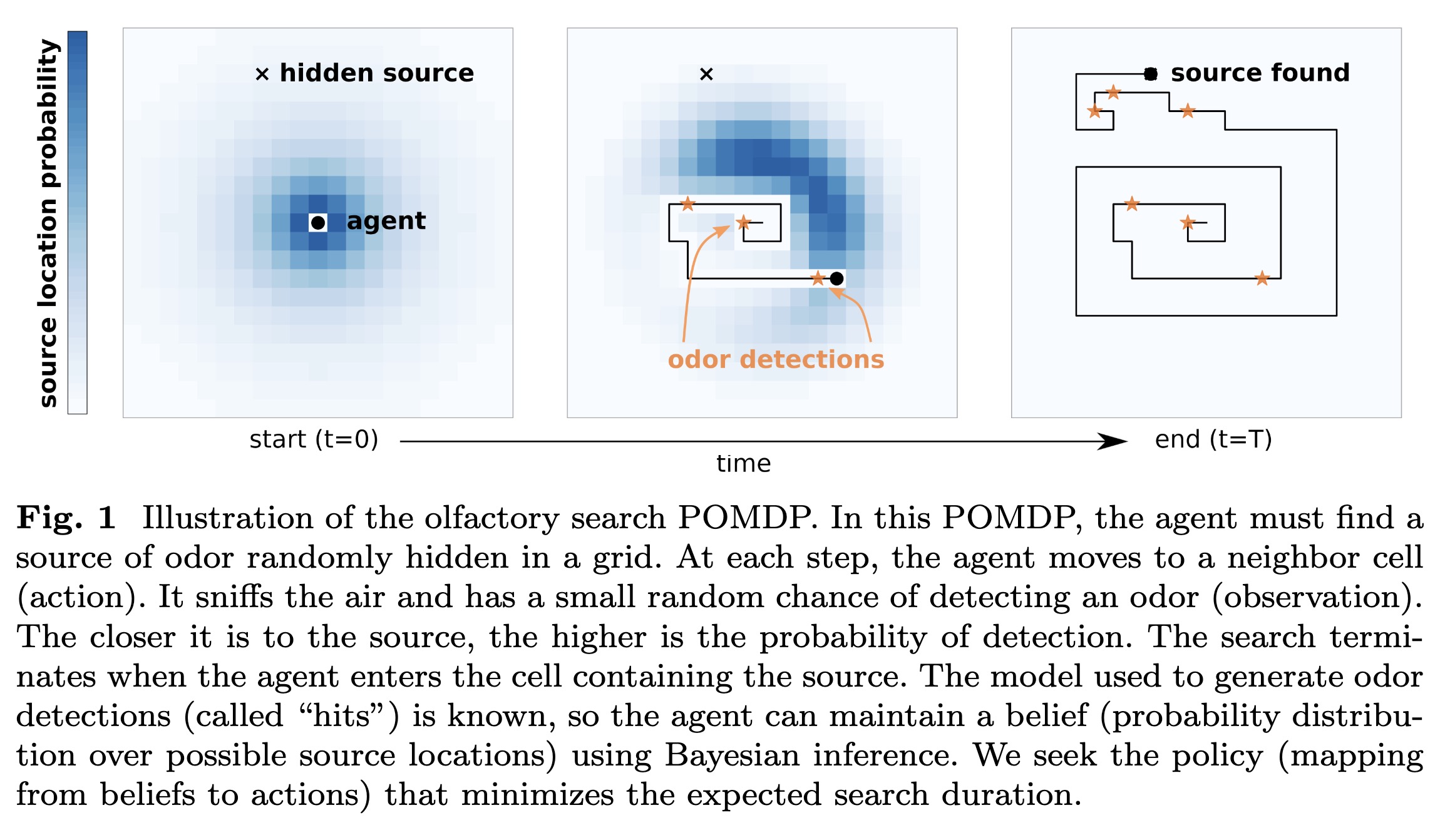
"Deep reinforcement learning for the olfactory search POMDP: a quantitative benchmark" — Using deep reinforcement learning to search for a source of odor in turbulence, as applicable to sniffer robots.
Paper: https://arxiv.org/abs/2302.00706
#NewPaper #Robotics #DeepLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the olfactory s…
Paper: https://arxiv.org/abs/2302.00706
#NewPaper #Robotics #DeepLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the olfactory s…
0
0
0
Fahim Farook
f
"Why Combining Text and Visualization Could Improve Bayesian Reasoning: A Cognitive Load Perspective" — An examination of the cognitive load elicited when solving Bayesian problems using icon arrays, text, and a juxtaposition of text and icon arrays.
Paper: https://arxiv.org/abs/2302.00707
#NewPaper #HumanComputerInteraction #HC
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustrative overview of our…
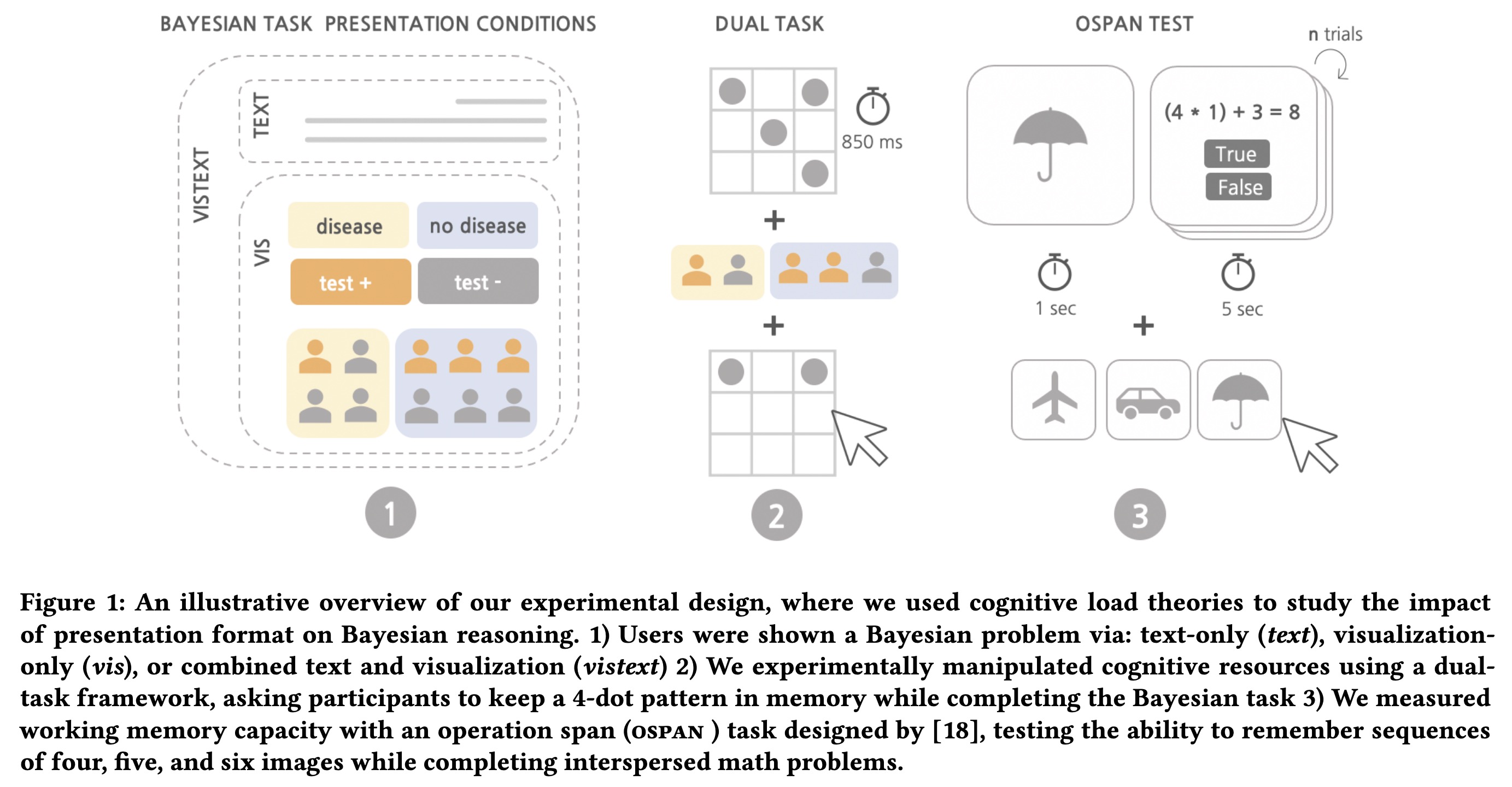
Paper: https://arxiv.org/abs/2302.00707
#NewPaper #HumanComputerInteraction #HC
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustrative overview of our…
0
1
0
Fahim Farook
f
"CrazyChoir: Flying Swarms of Crazyflie Quadrotors in ROS 2" — A modular Python framework based on the Robot Operating System (ROS) 2 which provides a comprehensive set of functionalities to simulate and run experiments on teams of cooperating Crazyflie nano-quadrotors.
Paper: https://arxiv.org/abs/2302.00716
#NewPaper #Robotics
<<Find this useful? Please boost so that others can benefit too 🙂>>
CRAZYCHOIR architecture. Crazyf…
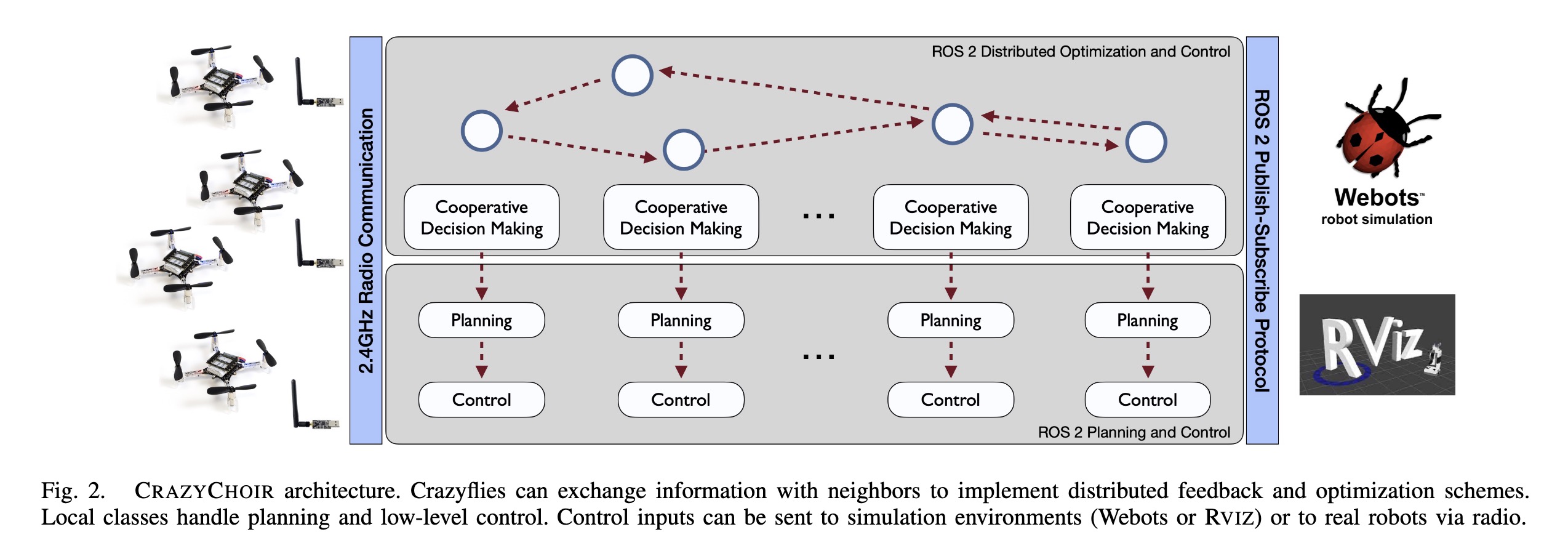
Paper: https://arxiv.org/abs/2302.00716
#NewPaper #Robotics
<<Find this useful? Please boost so that others can benefit too 🙂>>
CRAZYCHOIR architecture. Crazyf…
0
1
0
Fahim Farook
f
"Real-Time Evaluation in Online Continual Learning: A New Paradigm. (arXiv:2302.01047v1 [cs.LG])" — A practical real-time evaluation of continual learning, in which the stream does not wait for the model to complete training before revealing the next data for predictions.
Paper: http://arxiv.org/abs/2302.01047
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
OCL Real-Time Evaluation Exampl…
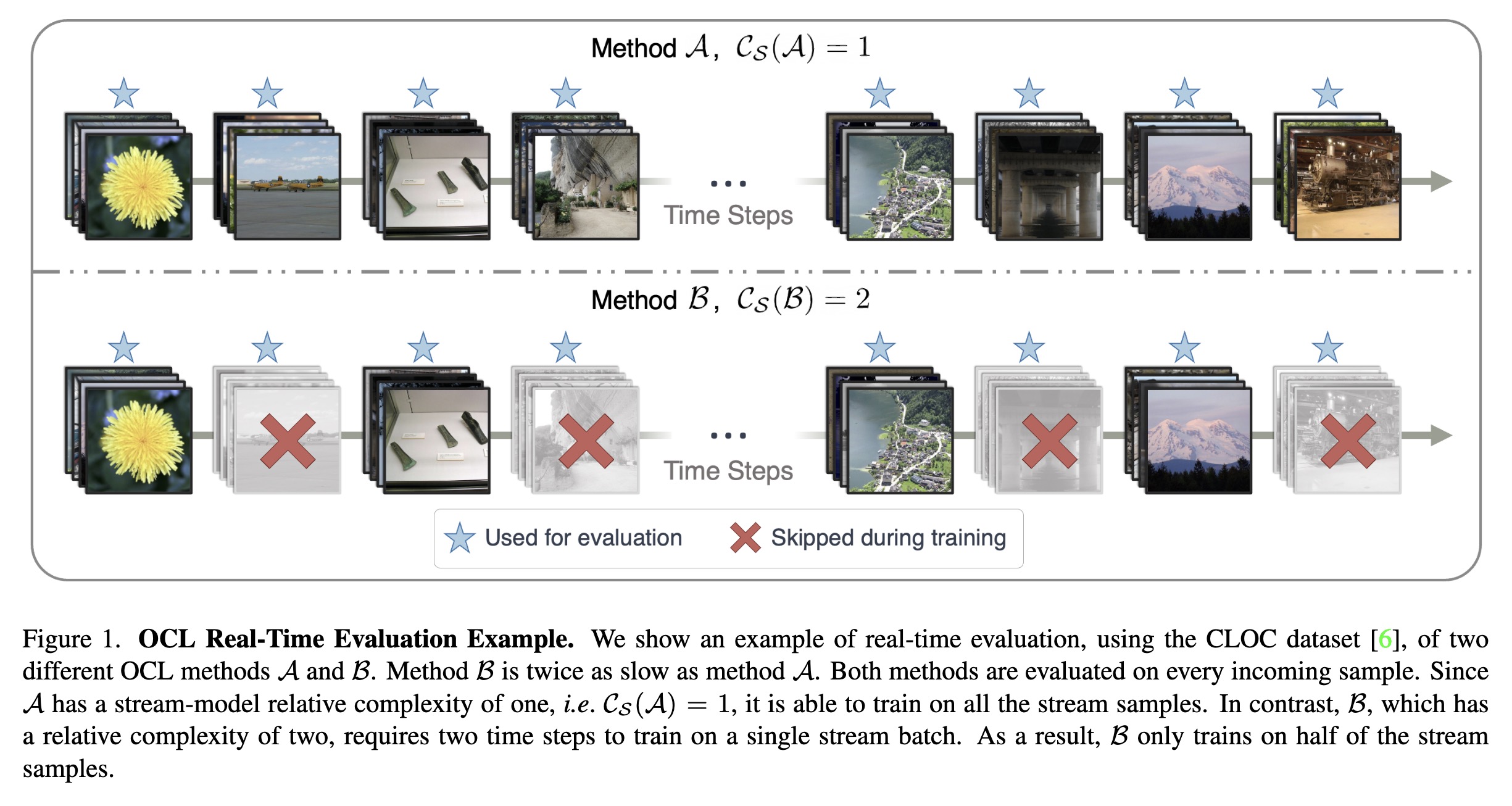
Paper: http://arxiv.org/abs/2302.01047
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
OCL Real-Time Evaluation Exampl…
0
1
0
Fahim Farook
f
"Multimodal Chain-of-Thought Reasoning in Language Models. (arXiv:2302.00923v1 [cs.CL])" — A Multimodal Chain-of-Thought that incorporates vision features in a decoupled training framework which separates the rationale generation and answer inference into two stages and incorporates vision features in both stages.
Paper: http://arxiv.org/abs/2302.00923
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of the multimodal CoT t…
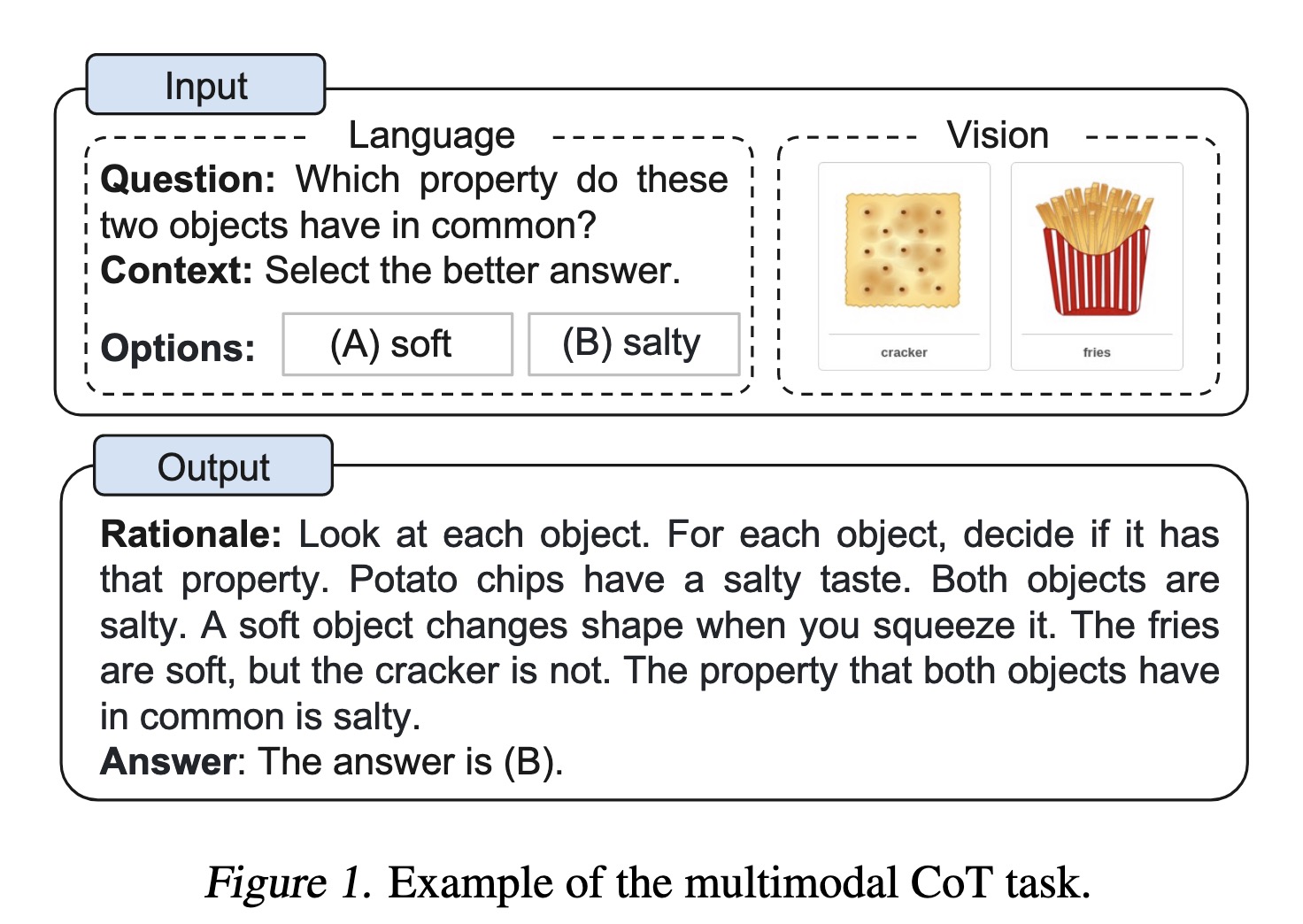
Paper: http://arxiv.org/abs/2302.00923
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of the multimodal CoT t…
0
2
0
Fahim Farook
f
"Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment. (arXiv:2302.00902v1 [cs.LG])" — A modification of VQ-VAE that learns to align text-image data in an unsupervised manner by leveraging pretrained language models (e.g., BERT, RoBERTa).
Paper: http://arxiv.org/abs/2302.00902
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Language Quantization AutoEnco…
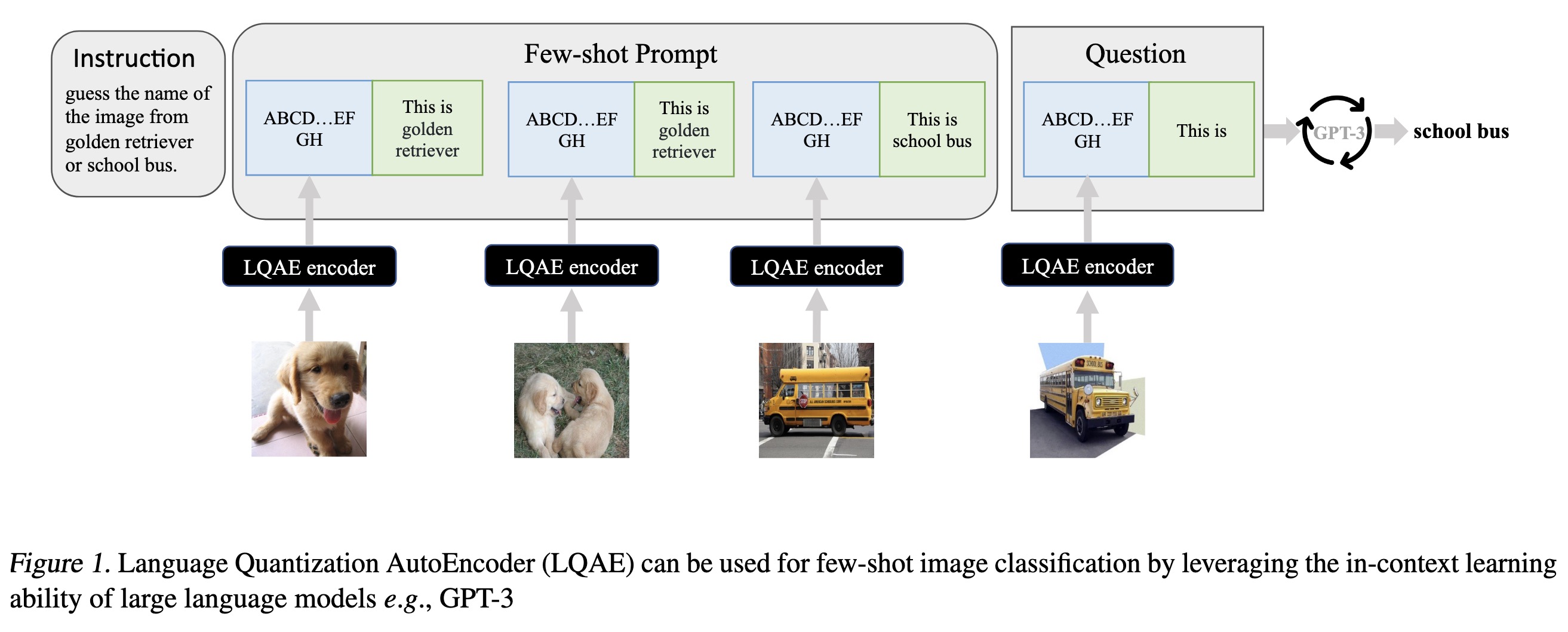
Paper: http://arxiv.org/abs/2302.00902
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Language Quantization AutoEnco…
0
2
0
Fahim Farook
f
"Disentanglement of Latent Representations via Sparse Causal Interventions. (arXiv:2302.00869v1 [cs.LG])" — A new method for disentanglement inspired by causal dynamics that combines causality theory with vector-quantized variational autoencoders where the model considers the quantized vectors as causal variables and links them in a causal graph.
Paper: http://arxiv.org/abs/2302.00869
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Atomic interventions on one fac…

Paper: http://arxiv.org/abs/2302.00869
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Atomic interventions on one fac…
0
3
0
Fahim Farook
f
"SHINE: Deep Learning-Based Accessible Parking Management System. (arXiv:2302.00837v1 [cs.CV])" — A system which uses deep learning object detection algorithms to detect the vehicle, license plate, and disability badges and then authenticates the rights to use the accessible parking spaces by coordinating with a central server.
Paper: http://arxiv.org/abs/2302.00837
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An overview of the methodology
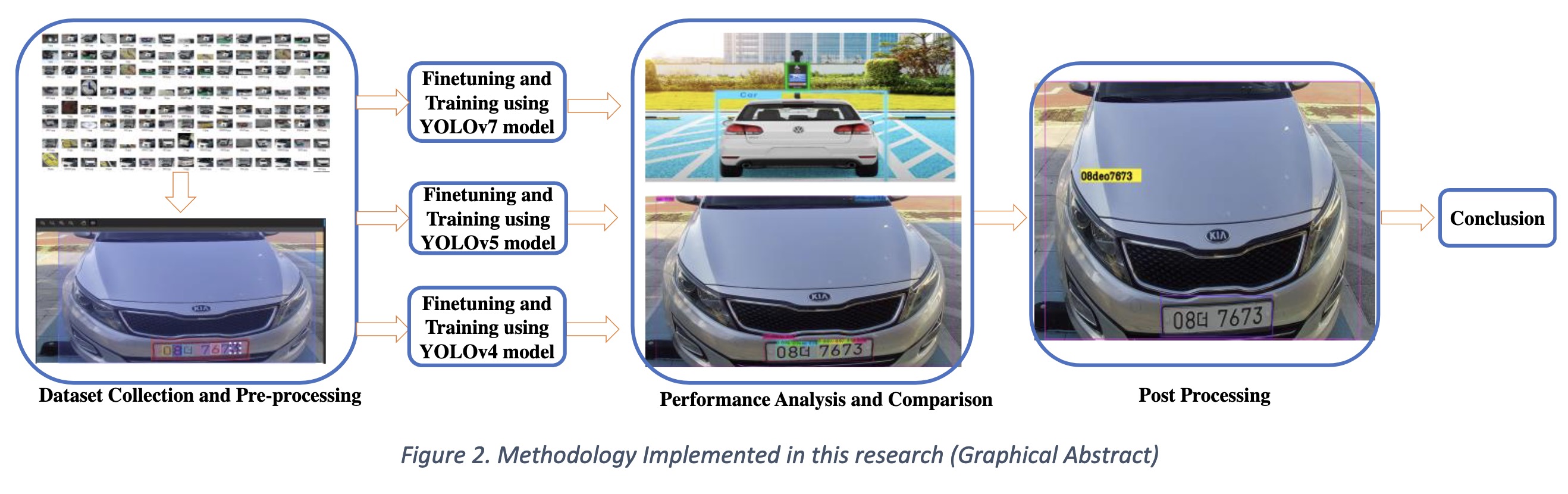
Paper: http://arxiv.org/abs/2302.00837
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An overview of the methodology
0
1
0
Fahim Farook
f
"Fast Sampling of Diffusion Models via Operator Learning. (arXiv:2211.13449v2 [cs.LG] UPDATED)" — Accelerating the sampling process of diffusion models using neural operators, an efficient method to solve the probability flow differential equations.
Paper: http://arxiv.org/abs/2211.13449
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the architectur…
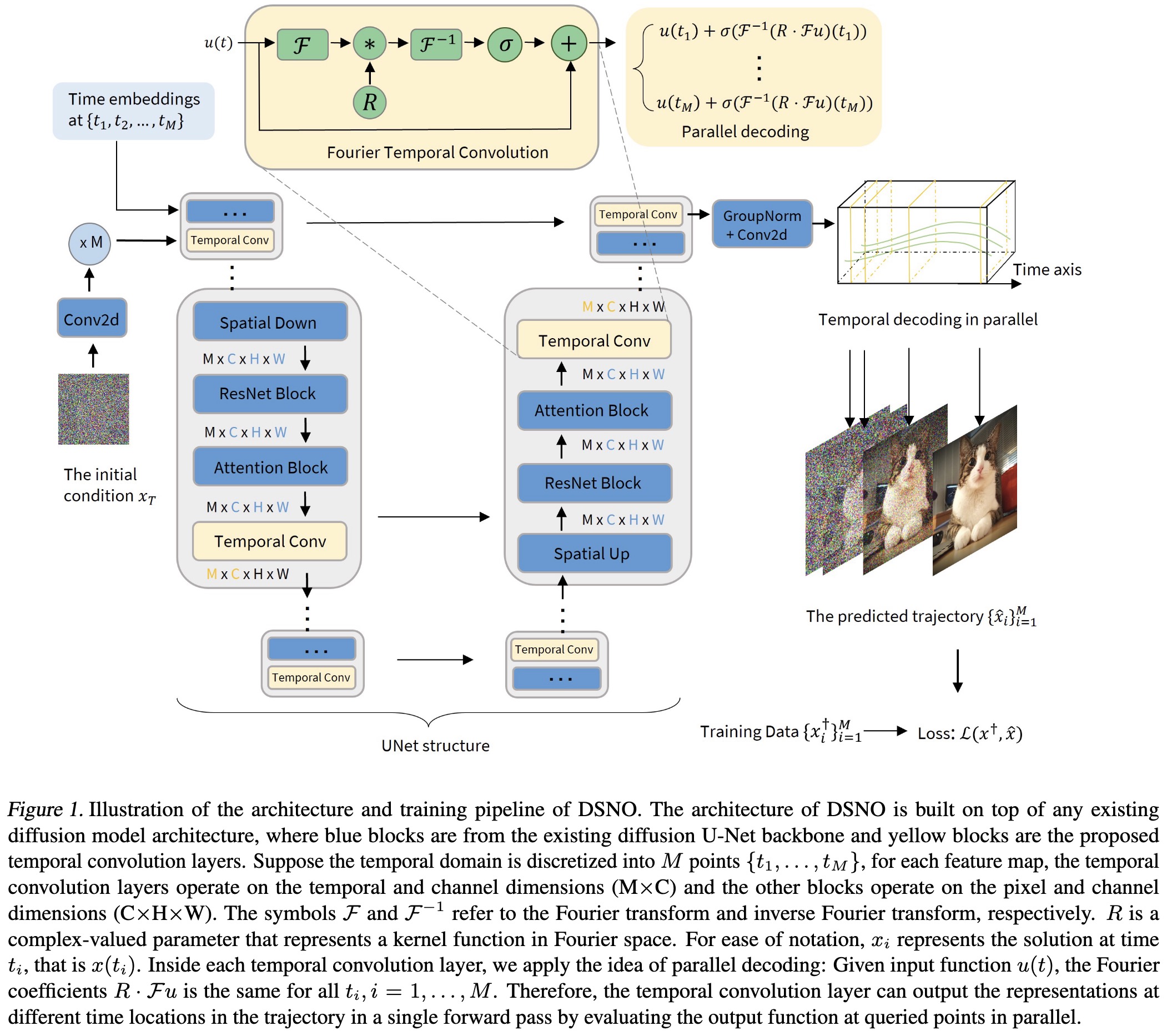
Paper: http://arxiv.org/abs/2211.13449
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the architectur…
0
1
0
Fahim Farook
f
"Diffusion-based Image Translation using Disentangled Style and Content Representation. (arXiv:2209.15264v2 [cs.CV] UPDATED)" — A novel diffusion-based unsupervised image translation method using disentangled style and content representation inspired by the splicing Vision Transformer.
Paper: http://arxiv.org/abs/2209.15264
Code: https://github.com/cyclomon/DiffuseIT
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative comparison of text-…

Paper: http://arxiv.org/abs/2209.15264
Code: https://github.com/cyclomon/DiffuseIT
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative comparison of text-…
0
1
0
Fahim Farook
f
"Stable Target Field for Reduced Variance Score Estimation in Diffusion Models. (arXiv:2302.00670v1 [cs.LG])" — A method to improve diffusion models by by reducing the variance of the training targets in their denoising score-matching objective. This is achieved by incorporating a reference batch which is used to calculate weighted conditional scores as more stable training targets.
Paper: http://arxiv.org/abs/2302.00670
Code: https://github.com/Newbeeer/stf
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of differences bet…
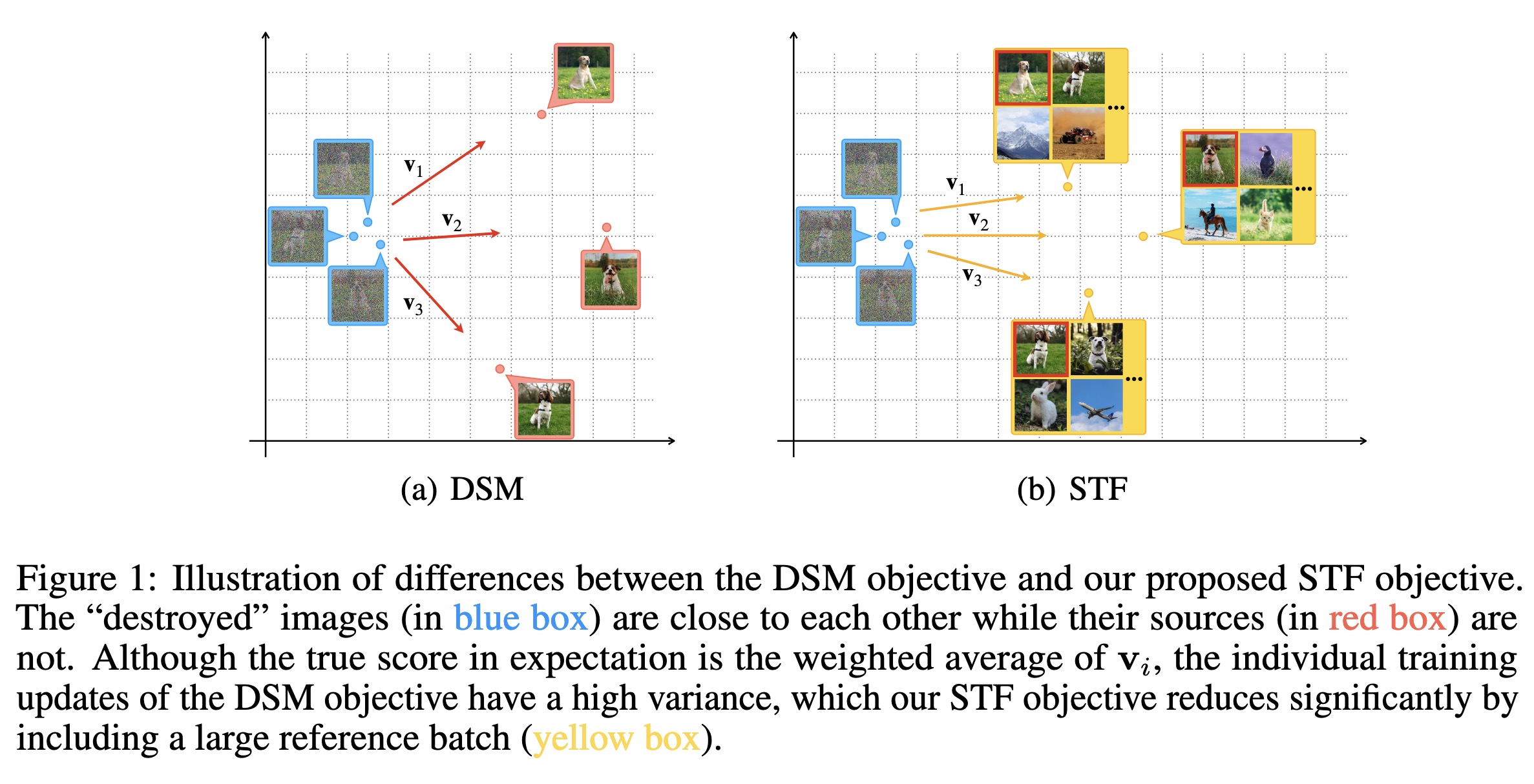
Paper: http://arxiv.org/abs/2302.00670
Code: https://github.com/Newbeeer/stf
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of differences bet…
0
1
0
Fahim Farook
f
"Continuous U-Net: Faster, Greater and Noiseless. (arXiv:2302.00626v1 [cs.CV])" — A novel family of networks for image segmentation which is a continuous deep neural network that introduces new dynamic blocks modelled by second order ordinary differential equations to overcome some of the limitations in current U-Net architectures.
Paper: http://arxiv.org/abs/2302.00626
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Visual comparison of our contin…
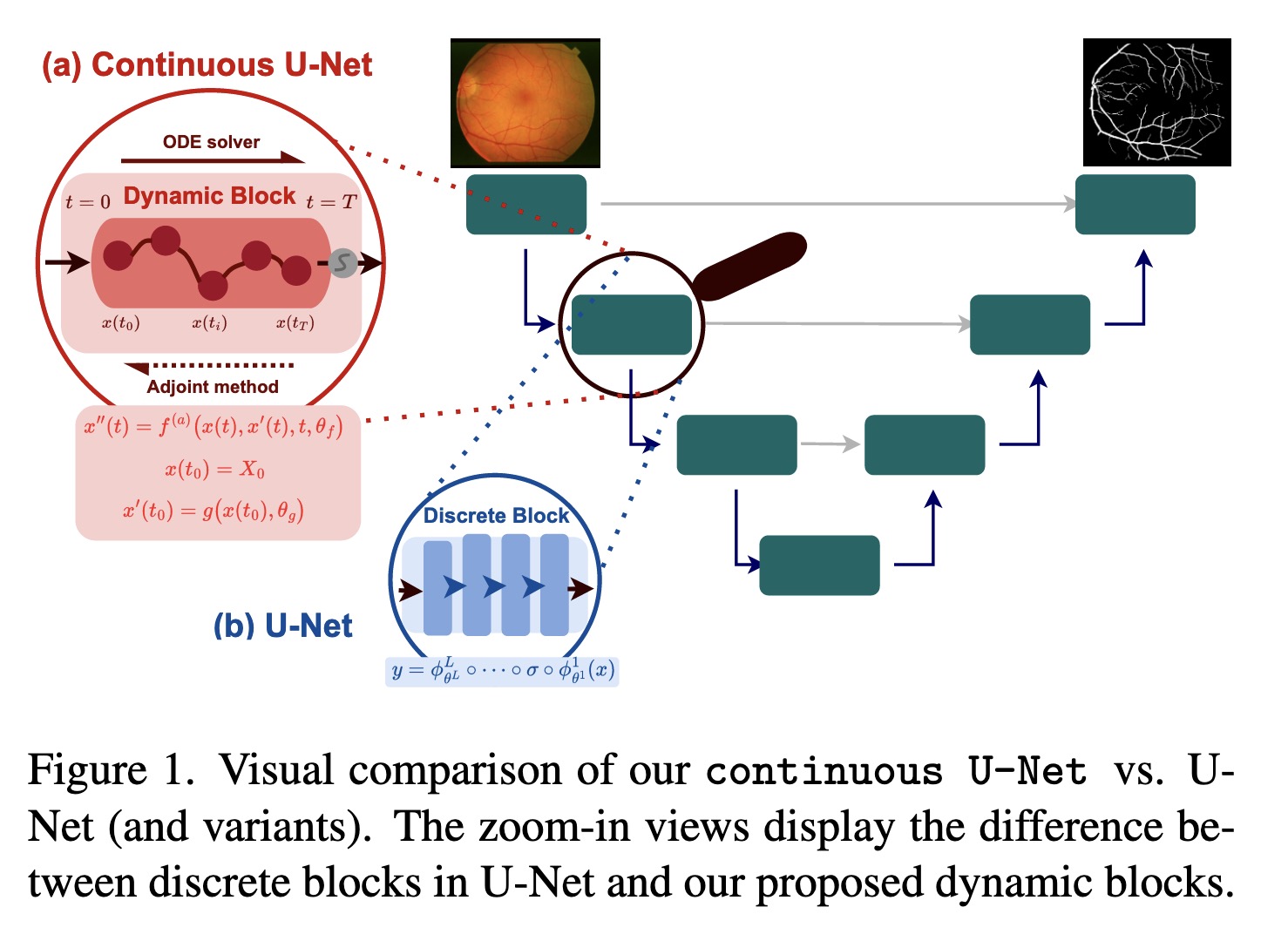
Paper: http://arxiv.org/abs/2302.00626
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Visual comparison of our contin…
0
2
1
Fahim Farook
f
"Inching Towards Automated Understanding of the Meaning of Art: An Application to Computational Analysis of Mondrian's Artwork. (arXiv:2302.00594v1 [cs.CV])" — An attempt to identify capabilities that are related to semantic processing, a current limitation of Deep Neural Networks (DNN), which identifies the missing capabilities by comparing the process of understanding Mondrian's paintings with the process of understanding electronic circuit designs, another creative problem solving instance.
Paper: http://arxiv.org/abs/2302.00594
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Possible cognitive architecture…
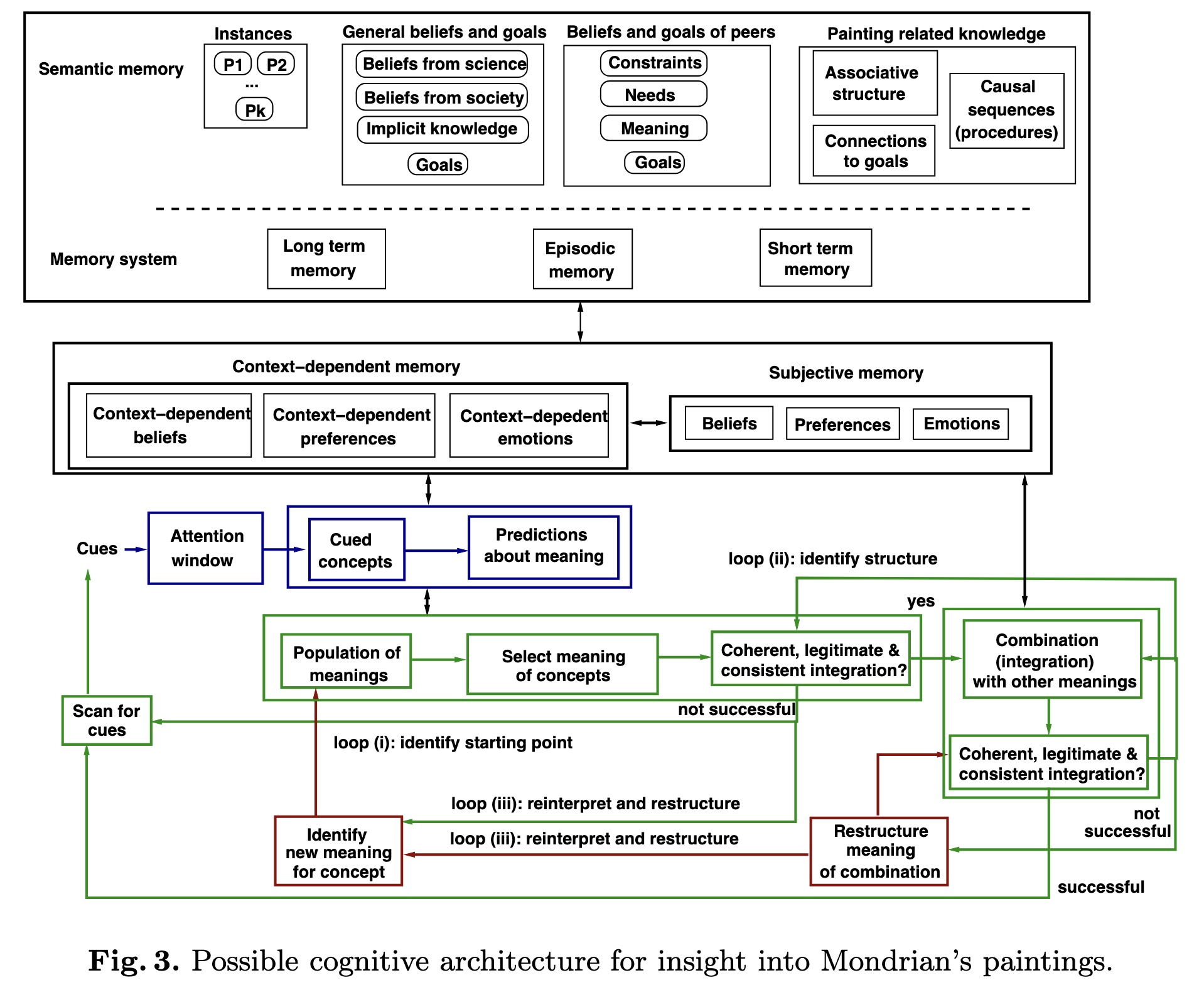
Paper: http://arxiv.org/abs/2302.00594
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Possible cognitive architecture…
0
1
1
Fahim Farook
f
"EfficientRep:An Efficient Repvgg-style ConvNets with Hardware-aware Neural Network Design. (arXiv:2302.00386v1 [cs.CV])" — A hardware-efficient architecture of convolutional neural network, which has a repvgg-like architecture which is high-computation hardware(e.g. GPU) friendly.
Paper: http://arxiv.org/abs/2302.00386
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Design of EfficientRep
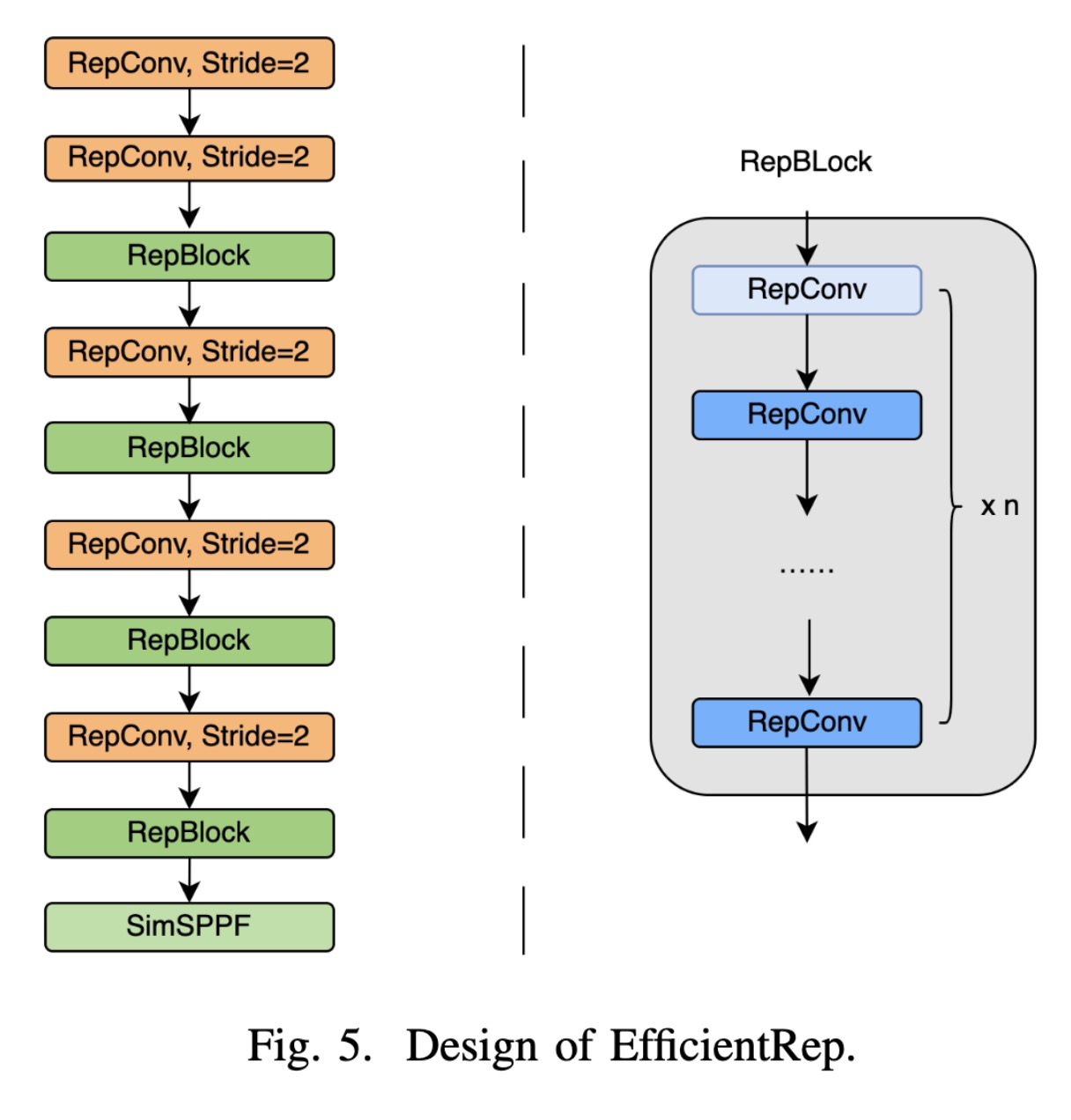
Paper: http://arxiv.org/abs/2302.00386
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Design of EfficientRep
0
1
0
Fahim Farook
f
"Alphazzle: Jigsaw Puzzle Solver with Deep Monte-Carlo Tree Search. (arXiv:2302.00384v1 [cs.CV])" — A reassembly algorithm based on single-player Monte Carlo Tree Search (MCTS) which shows the importance of MCTS and the neural networks working together.
Paper: http://arxiv.org/abs/2302.00384
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of a jigsaw puzzle task…
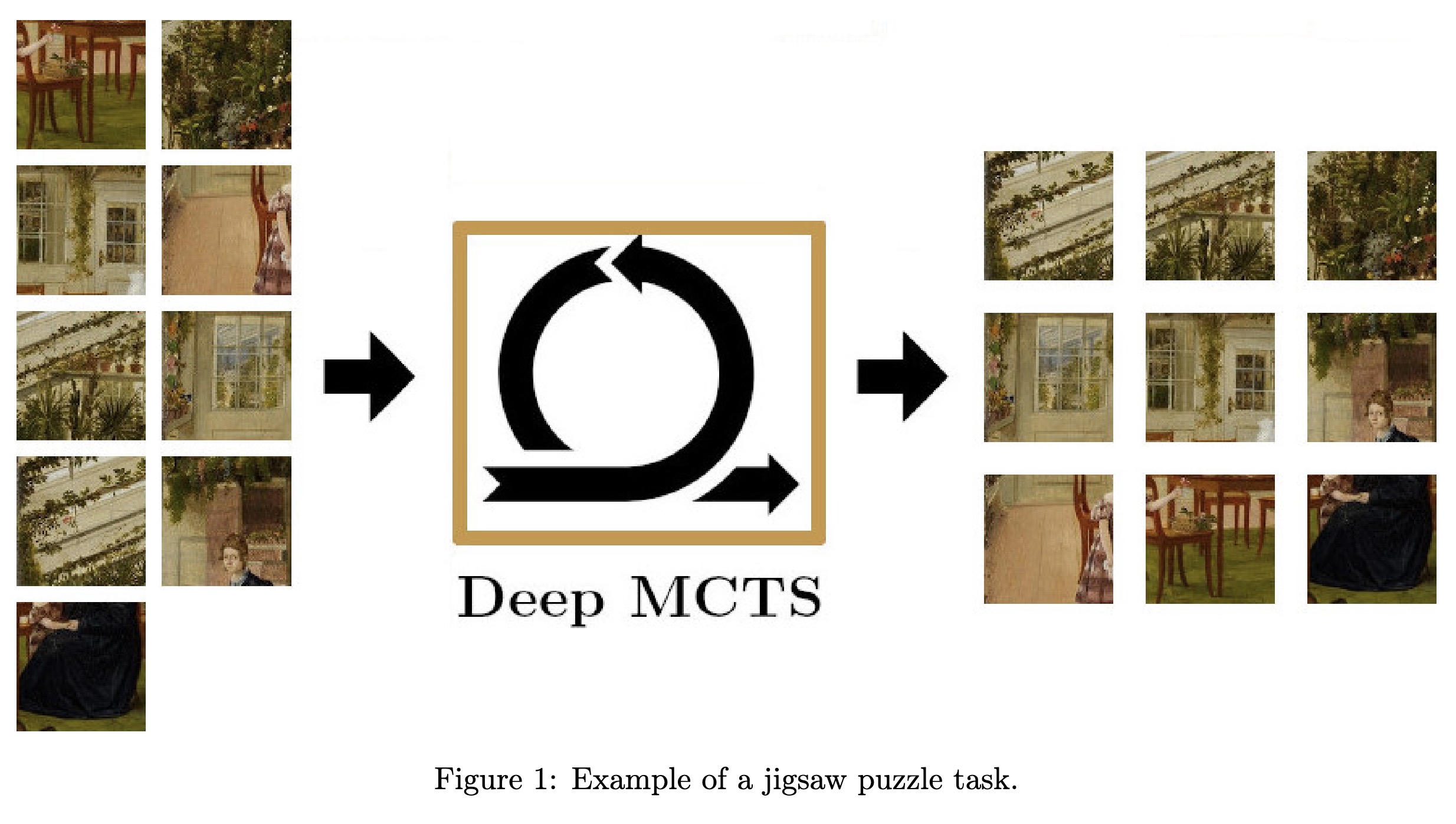
Paper: http://arxiv.org/abs/2302.00384
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of a jigsaw puzzle task…
0
1
0
Fahim Farook
f
"Detection of Tomato Ripening Stages using Yolov3-tiny. (arXiv:2302.00164v1 [cs.CV])" — A computer vision system to detect tomatoes at different ripening stages by using a neural network-based model for tomato classification and detection.
Paper: http://arxiv.org/abs/2302.00164
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Sample dataset images

Paper: http://arxiv.org/abs/2302.00164
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Sample dataset images
0
1
0
Fahim Farook
f
"Real Estate Property Valuation using Self-Supervised Vision Transformers. (arXiv:2302.00117v1 [cs.CV])" — A new method for property valuation that utilizes self-supervised vision transformers and hedonic pricing models trained on real estate data to estimate the value of a given property.
Paper: http://arxiv.org/abs/2302.00117
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Some sample images from a repre…

Paper: http://arxiv.org/abs/2302.00117
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Some sample images from a repre…
0
1
0