Conversation
Fahim Farook
f
"Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment. (arXiv:2302.00902v1 [cs.LG])" — A modification of VQ-VAE that learns to align text-image data in an unsupervised manner by leveraging pretrained language models (e.g., BERT, RoBERTa).
Paper: http://arxiv.org/abs/2302.00902
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Language Quantization AutoEnco…
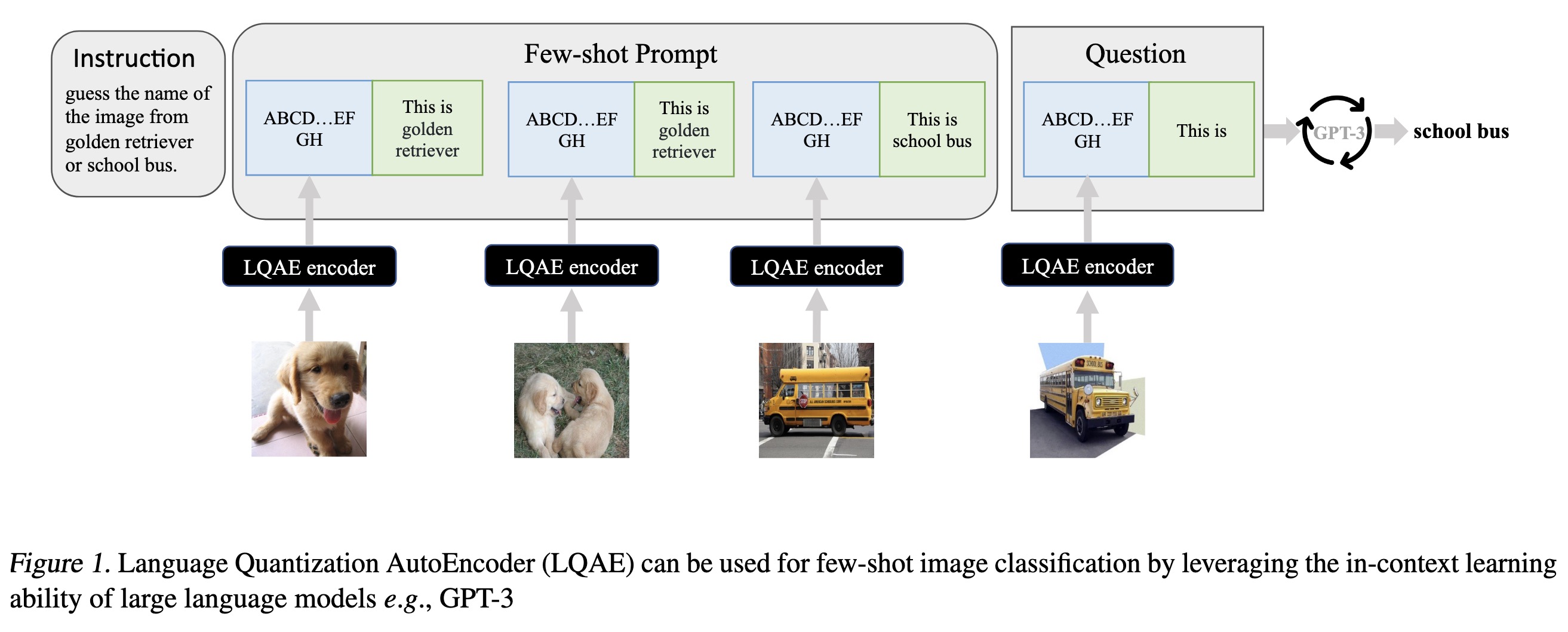
Paper: http://arxiv.org/abs/2302.00902
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Language Quantization AutoEnco…
 0
0
 2
2
 0
0