Fahim Farook
Posts
1576Following
139Followers
881I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"Rethinking 1x1 Convolutions: Can we train CNNs with Frozen Random Filters?. (arXiv:2301.11360v1 [cs.CV])" — An exploration into whether Convolutional Neural Networks (CNN) learning the weights of vast numbers of convolutional operators is really necessary.
Paper: http://arxiv.org/abs/2301.11360
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Validation accuracy of LCResNet…
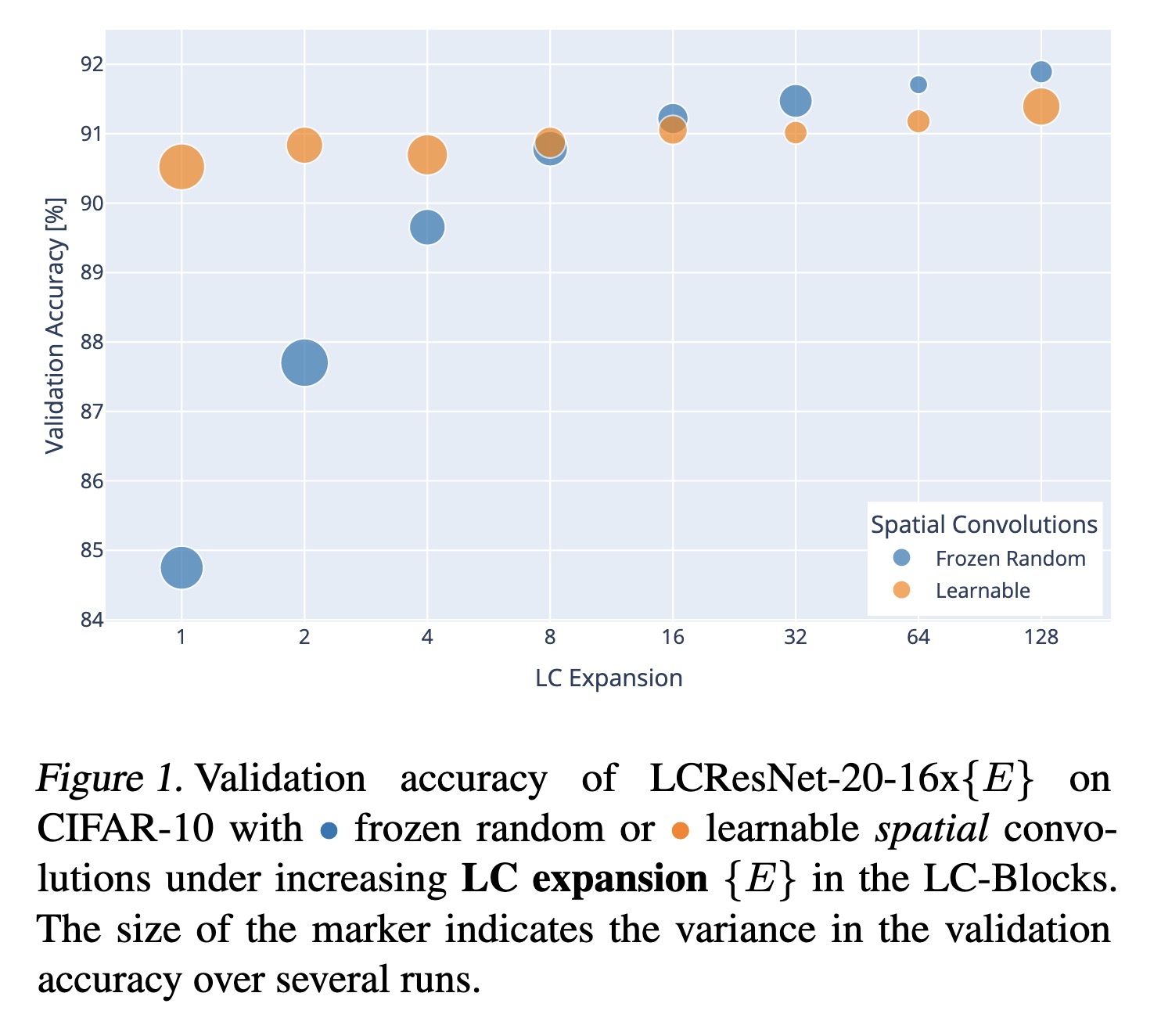
Paper: http://arxiv.org/abs/2301.11360
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Validation accuracy of LCResNet…
 0
0
 4
4
 4
4
Fahim Farook
f
"Multimodal Event Transformer for Image-guided Story Ending Generation. (arXiv:2301.11357v1 [cs.CV])" — A multimodal event transformer, an event-based reasoning framework for image-guided story ending generation which constructs visual and semantic event graphs from story plots and ending image, and leverages event-based reasoning to reason and mine implicit information in a single modality.
Paper: http://arxiv.org/abs/2301.11357
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given a multi-sentence story pl…

Paper: http://arxiv.org/abs/2301.11357
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given a multi-sentence story pl…
0
3
2
Fahim Farook
f
"Animating Still Images. (arXiv:2209.10497v2 [cs.CV] UPDATED)" — A method for imparting motion to a still 2D image which uses deep learning to segment part of the image as the subject, uses in-paining to complete the background, and then adds animation to the subject.
Paper: http://arxiv.org/abs/2209.10497
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Interactive segmentation: Green…

Paper: http://arxiv.org/abs/2209.10497
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Interactive segmentation: Green…
0
1
1
Fahim Farook
f
"VAuLT: Augmenting the Vision-and-Language Transformer for Sentiment Classification on Social Media. (arXiv:2208.09021v3 [cs.CV] UPDATED)" — An extension of the popular Vision-and-Language Transformer (ViLT) to improve performance on vision-and-language (VL) tasks that involve more complex text inputs than image captions while having minimal impact on training and inference efficiency.
Paper: http://arxiv.org/abs/2208.09021
Code: https://github.com/gchochla/vault
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VAuLT propagates representation…
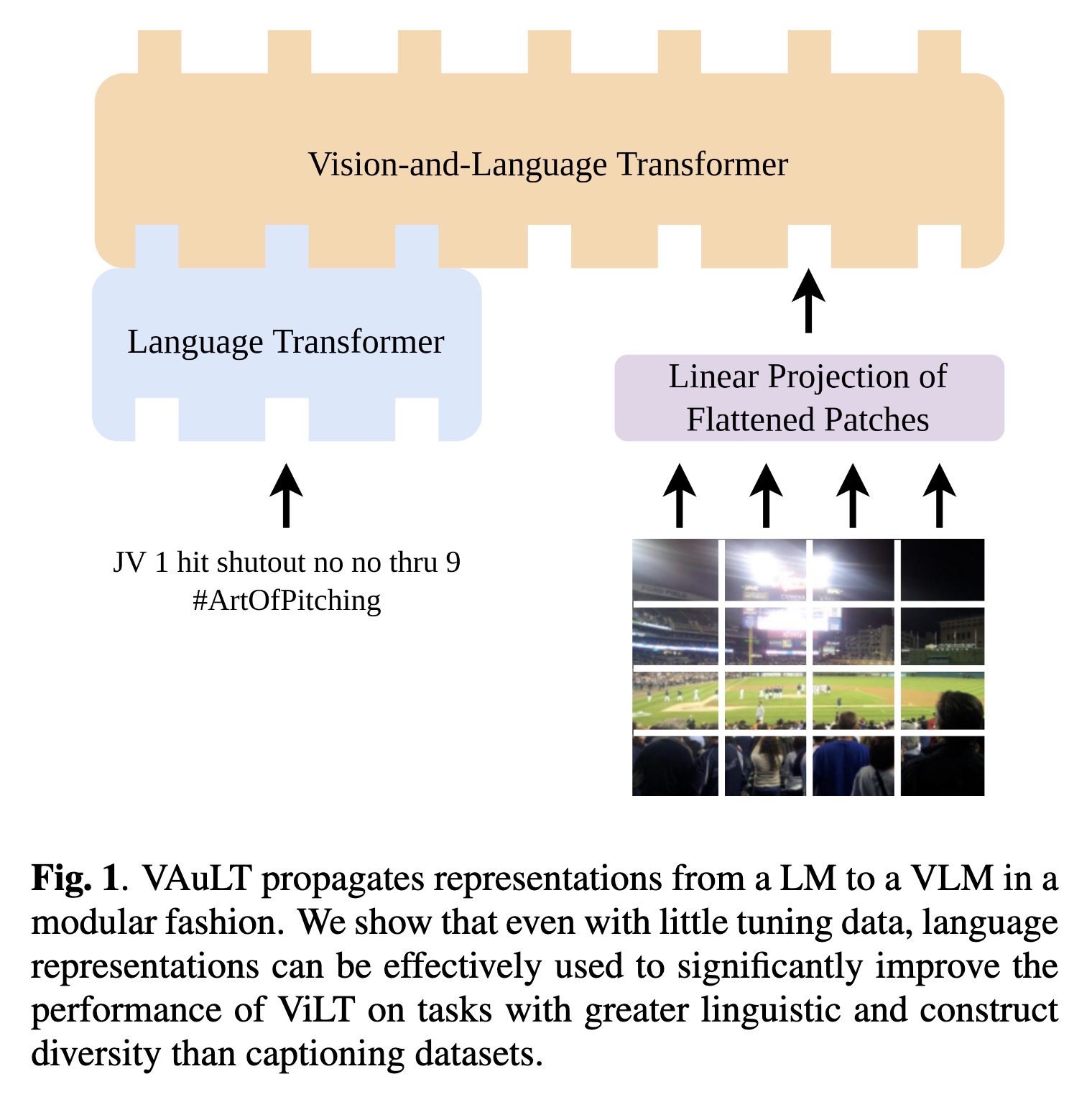
Paper: http://arxiv.org/abs/2208.09021
Code: https://github.com/gchochla/vault
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VAuLT propagates representation…
0
1
0
Fahim Farook
f
"SIViDet: Salient Image for Efficient Weaponized Violence Detection. (arXiv:2207.12850v4 [cs.CV] UPDATED)" — A new dataset that contains videos depicting weaponized violence, non-weaponized violence, and non-violent events; and a proposal for a novel data-centric method that arranges video frames into salient images while minimizing information loss for comfortable inference by SOTA image classifiers.
Paper: http://arxiv.org/abs/2207.12850
Code: https://github.com/Ti-Oluwanimi/Violence_Detection
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Salient Image: A sequence of vi…

Paper: http://arxiv.org/abs/2207.12850
Code: https://github.com/Ti-Oluwanimi/Violence_Detection
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Salient Image: A sequence of vi…
0
1
0
Fahim Farook
f
"BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning. (arXiv:2206.08657v3 [cs.CV] UPDATED)" — A proposal for multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder.
Paper: http://arxiv.org/abs/2206.08657
Code: https://github.com/microsoft/BridgeTower
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) – (d) are four categories o…
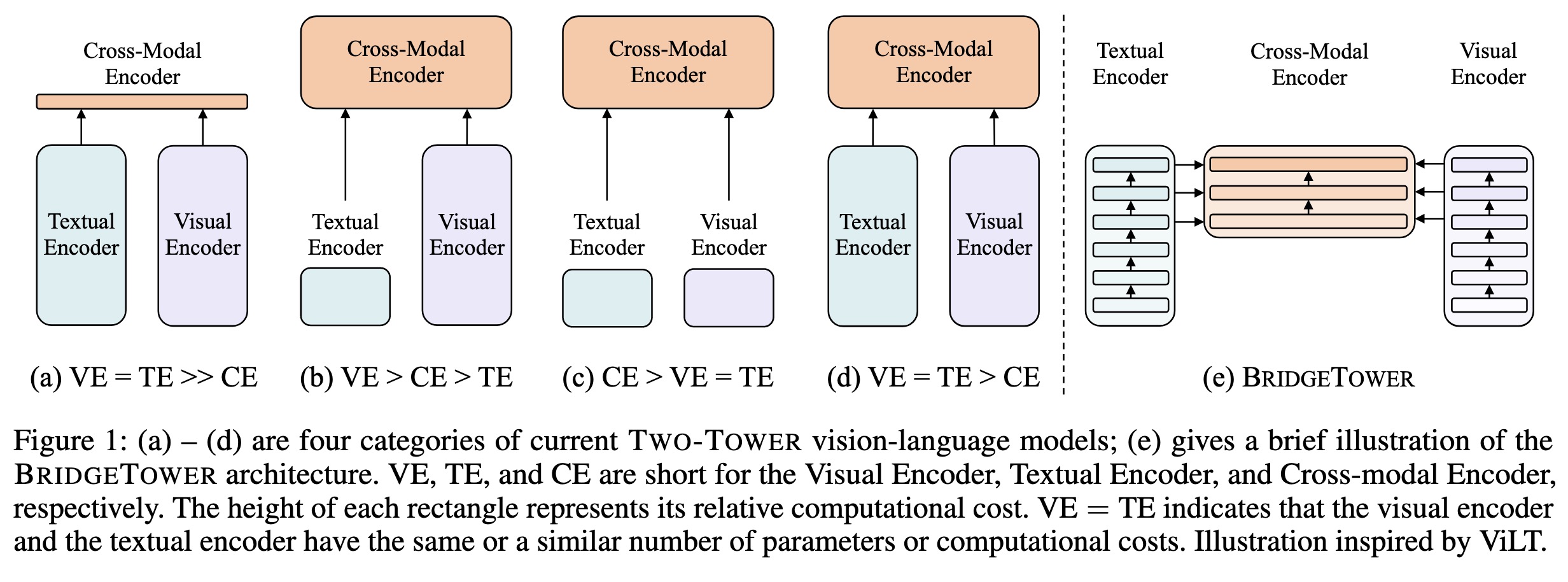
Paper: http://arxiv.org/abs/2206.08657
Code: https://github.com/microsoft/BridgeTower
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) – (d) are four categories o…
0
1
0
Fahim Farook
f
"Text-To-4D Dynamic Scene Generation. (arXiv:2301.11280v1 [cs.CV])" — A method for generating three-dimensional dynamic scenes from text descriptions which uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by querying a Text-to-Video (T2V) diffusion-based model.
Paper: http://arxiv.org/abs/2301.11280
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by MAV3D alon…
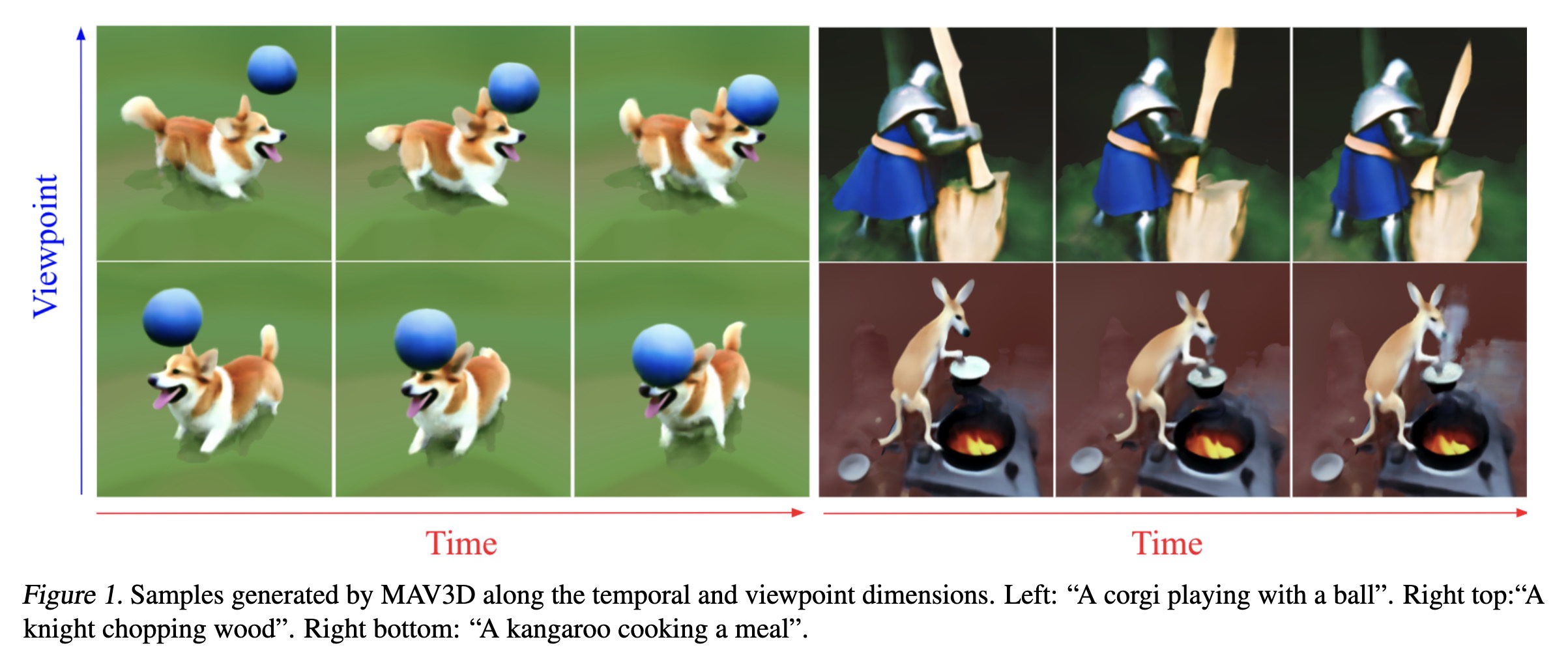
Paper: http://arxiv.org/abs/2301.11280
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by MAV3D alon…
0
1
1
Fahim Farook
f
"BiBench: Benchmarking and Analyzing Network Binarization. (arXiv:2301.11233v1 [cs.CV])" — A rigorously designed benchmark with in-depth analysis for network binarization where they scrutinize the requirements of binarization in the actual production and define evaluation tracks and metrics for a comprehensive investigation.
Paper: http://arxiv.org/abs/2301.11233
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Evaluation tracks of BiBench. O…
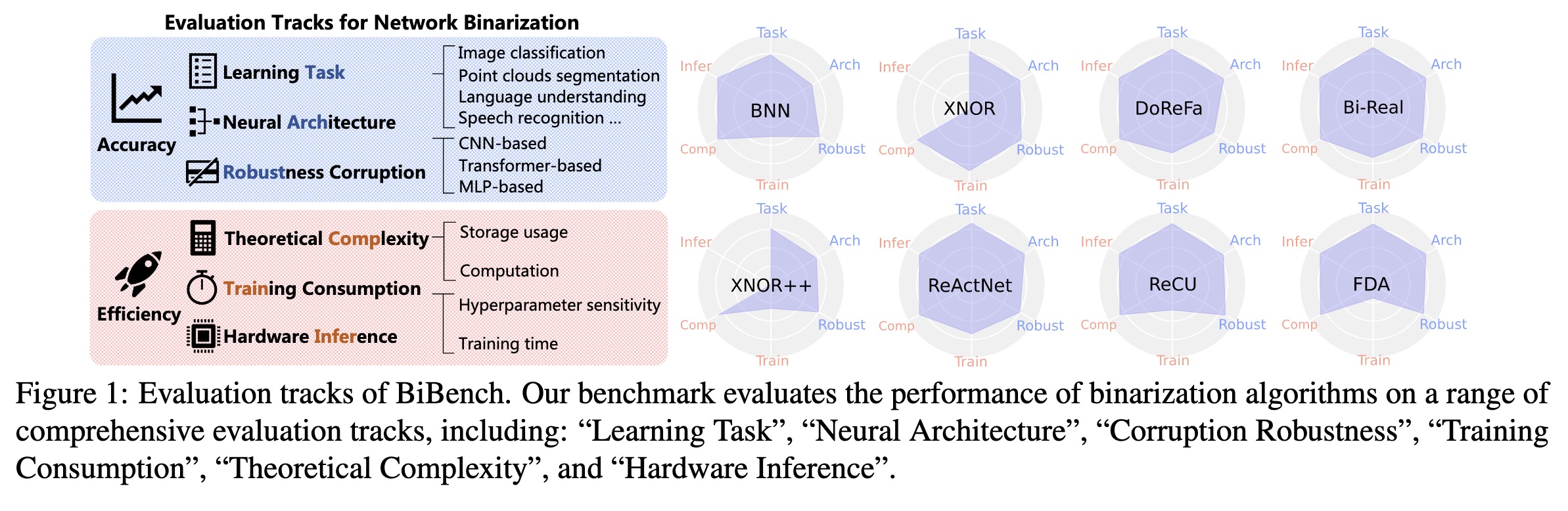
Paper: http://arxiv.org/abs/2301.11233
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Evaluation tracks of BiBench. O…
0
1
0
Fahim Farook
f
"Improving Statistical Fidelity for Neural Image Compression with Implicit Local Likelihood Models. (arXiv:2301.11189v1 [eess.IV])" — A non-binary discriminator that is conditioned on quantized local image representations obtained via VQ-VAE autoencoders, for lossy image compression.
Paper: http://arxiv.org/abs/2301.11189
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of distortion vs. st…
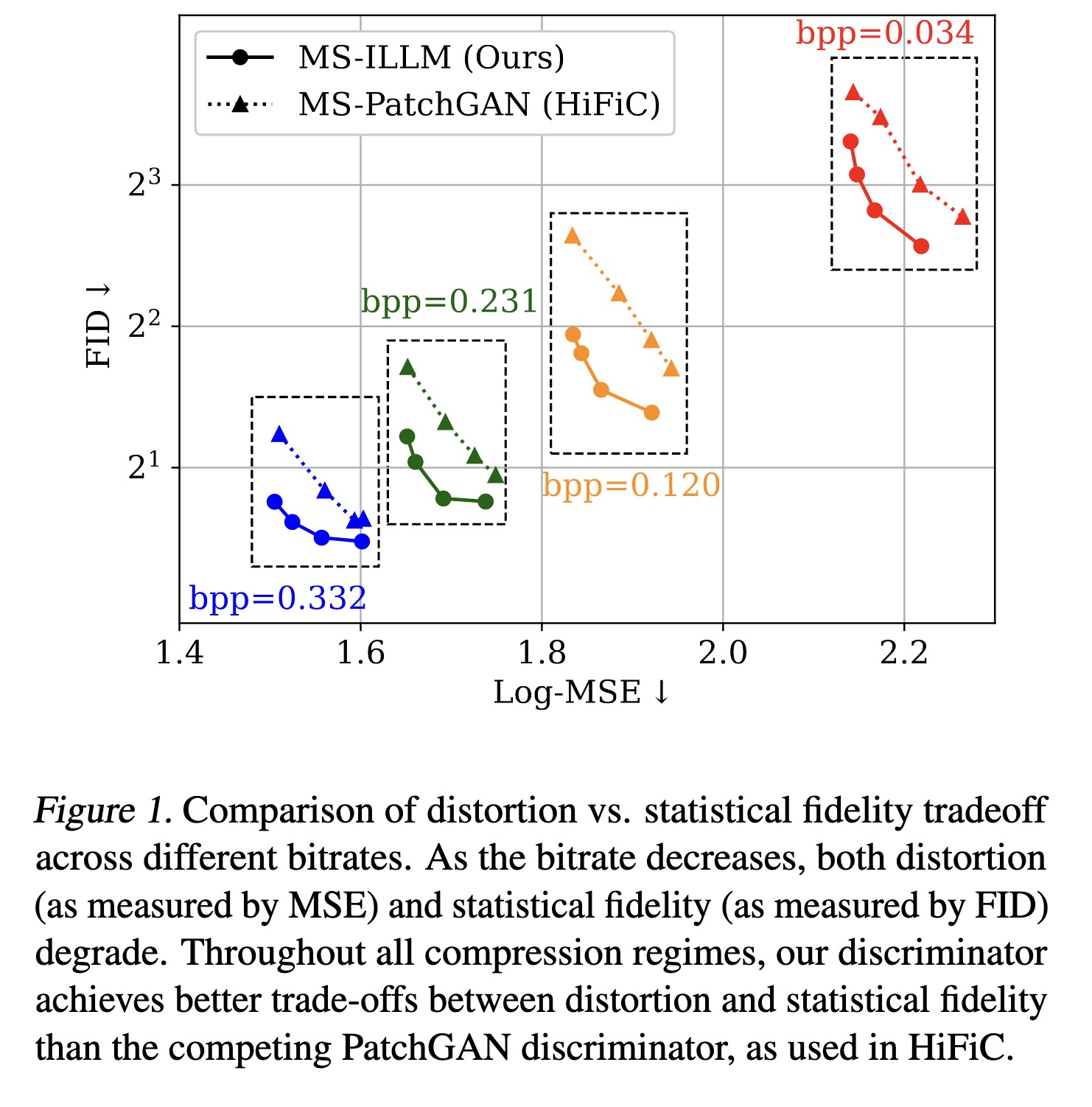
Paper: http://arxiv.org/abs/2301.11189
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of distortion vs. st…
0
0
0
Fahim Farook
f
"Revisiting Temporal Modeling for CLIP-based Image-to-Video Knowledge Transferring. (arXiv:2301.11116v1 [cs.CV])" — A look at temporal modeling in the context of image-to-video knowledge transferring, which is the key point for extending image-text pretrained models to the video domain.
Paper: http://arxiv.org/abs/2301.11116
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) Illustration of temporal mo…
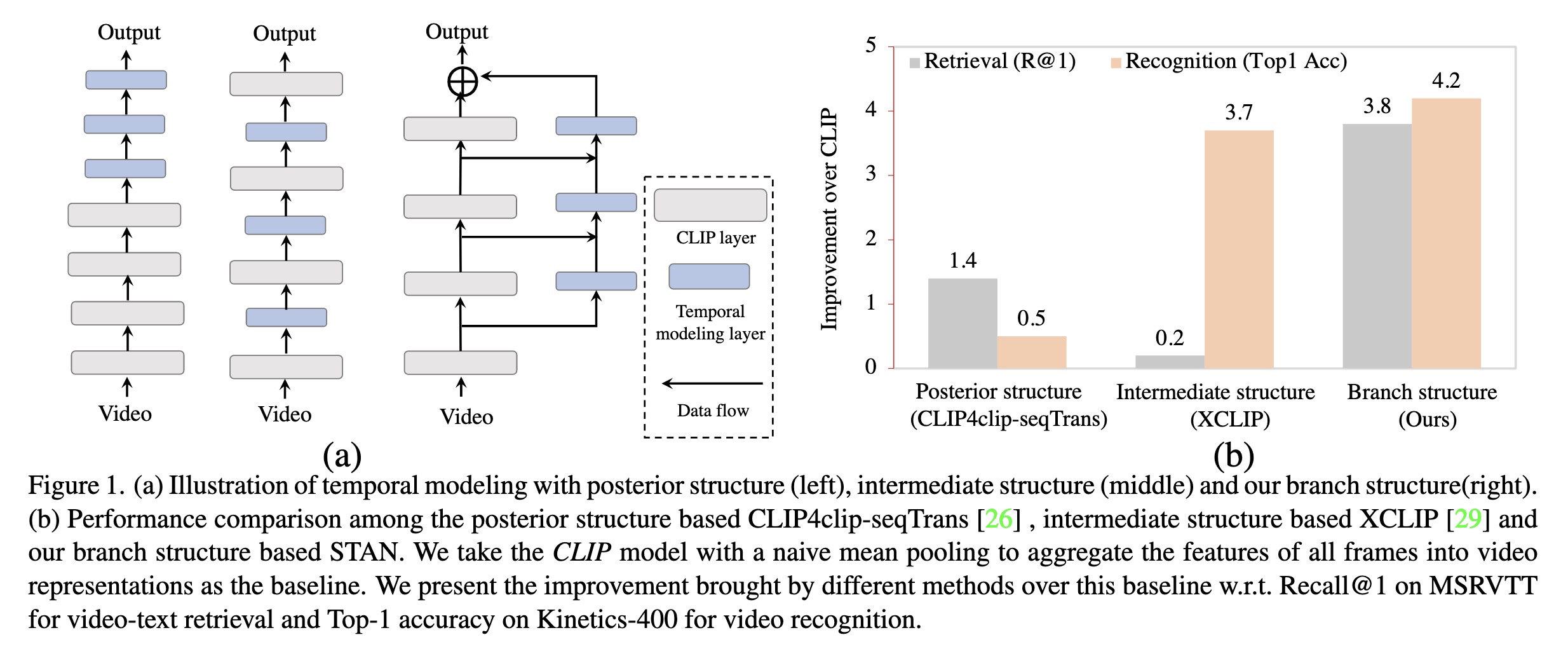
Paper: http://arxiv.org/abs/2301.11116
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) Illustration of temporal mo…
0
1
0
Fahim Farook
f
"Explaining Visual Biases as Words by Generating Captions. (arXiv:2301.11104v1 [cs.LG])" — Diagnosing the potential biases in image classifiers by leveraging two types (generative and discriminative) of pre-trained vision-language models to describe the visual bias as a word.
Paper: http://arxiv.org/abs/2301.11104
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of the proposed bias-to…

Paper: http://arxiv.org/abs/2301.11104
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of the proposed bias-to…
0
1
0
Fahim Farook
f
"Vision-Language Models Performing Zero-Shot Tasks Exhibit Gender-based Disparities. (arXiv:2301.11100v1 [cs.CV])" — An exploration of the extent to which zero-shot vision-language models exhibit gender bias for different vision tasks.
Paper: http://arxiv.org/abs/2301.11100
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) The average precision (AP) …
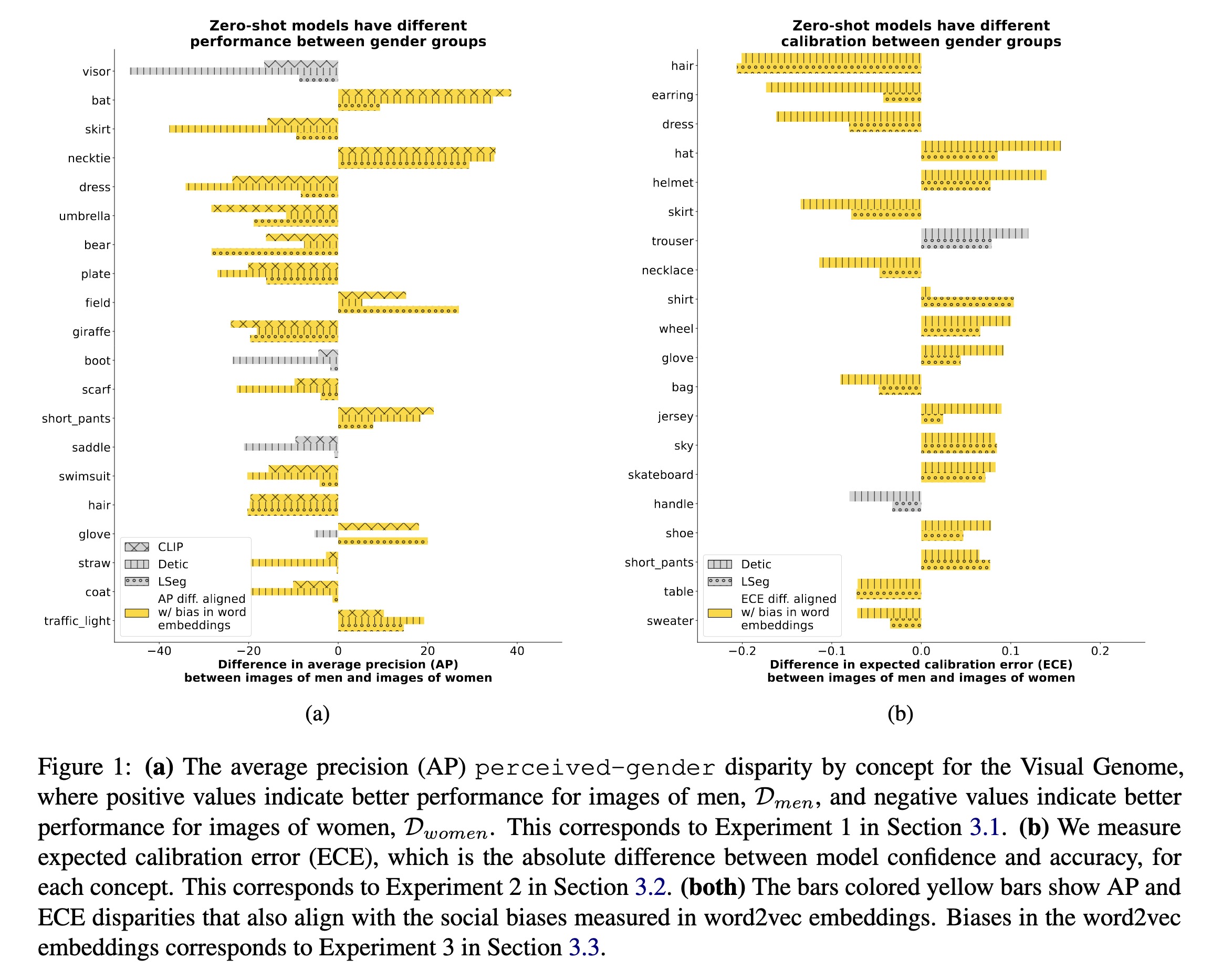
Paper: http://arxiv.org/abs/2301.11100
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) The average precision (AP) …
0
0
0
Fahim Farook
f
"simple diffusion: End-to-end diffusion for high resolution images. (arXiv:2301.11093v1 [cs.CV])" — Improve denoising diffusion for high resolution images while keeping the model as simple as possible and obtaining performance comparable to the latent diffusion-based approaches?
Paper: http://arxiv.org/abs/2301.11093
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A dslr photo of a frog wearing…

Paper: http://arxiv.org/abs/2301.11093
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A dslr photo of a frog wearing…
0
1
1
Fahim Farook
f
"Rewarded meta-pruning: Meta Learning with Rewards for Channel Pruning. (arXiv:2301.11063v1 [cs.CV])" — A method to reduce the parameters and FLOPs for computational efficiency in deep learning models by introducing accuracy and efficiency coefficients to control the trade-off between the accuracy of the network and its computing efficiency.
Paper: http://arxiv.org/abs/2301.11063
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reward at varying Accuracies an…
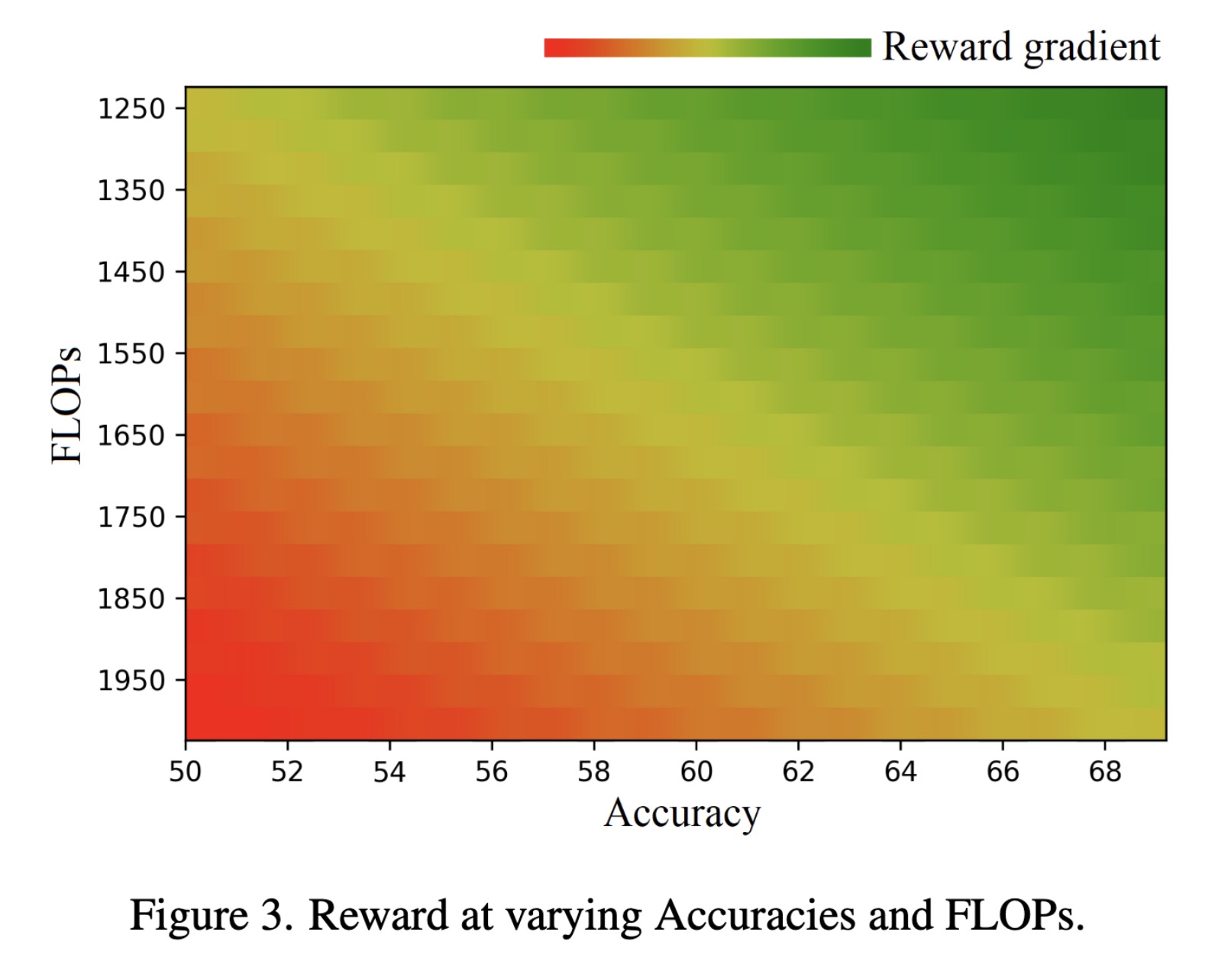
Paper: http://arxiv.org/abs/2301.11063
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Reward at varying Accuracies an…
0
1
0
Fahim Farook
f
"Explore the Power of Dropout on Few-shot Learning. (arXiv:2301.11015v1 [cs.CV])" — An exploration of the power of the dropout regularization technique on few-shot learning and provide some insights about how to use it.
Paper: http://arxiv.org/abs/2301.11015
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The generalization power of tra…
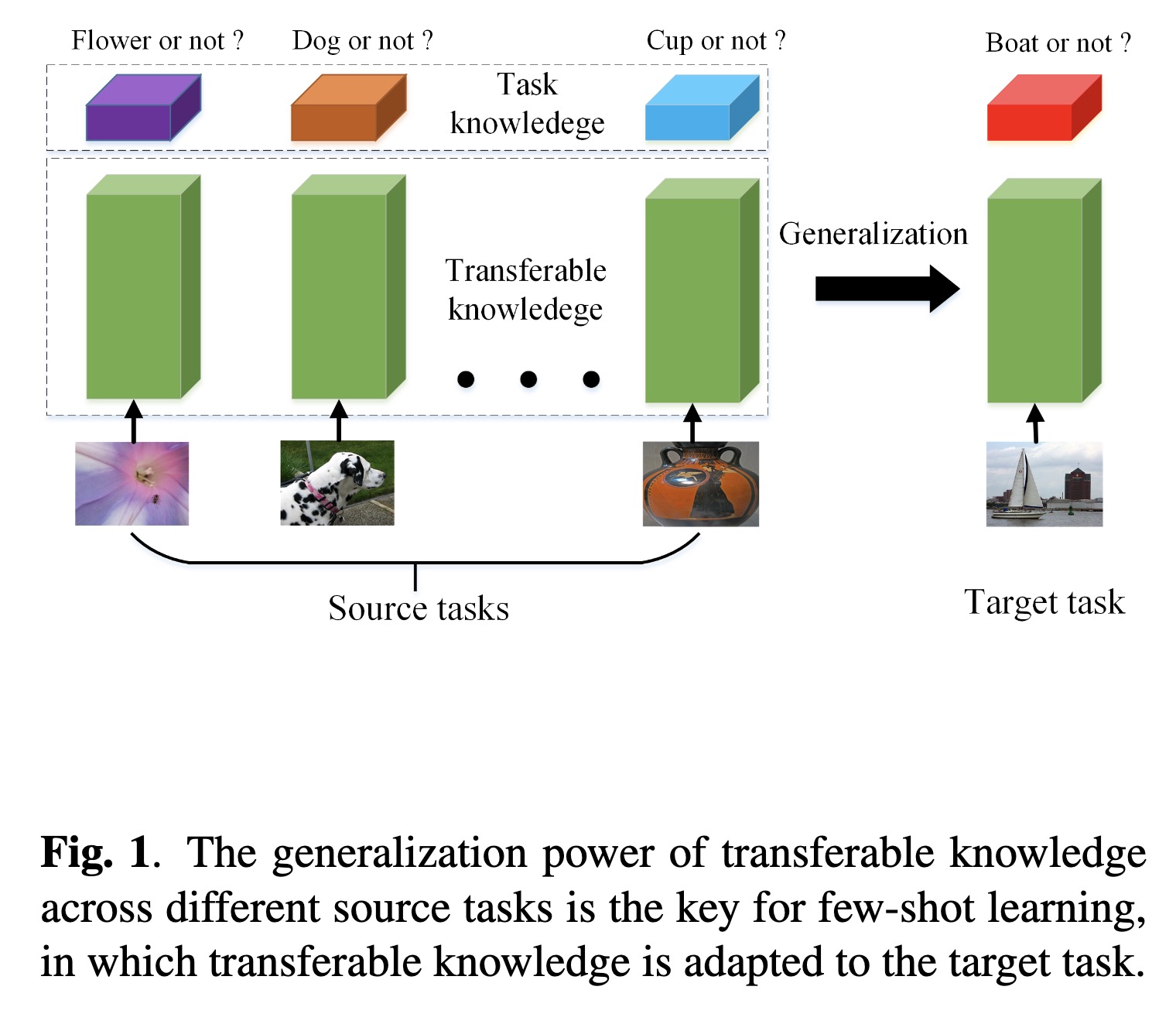
Paper: http://arxiv.org/abs/2301.11015
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The generalization power of tra…
0
1
0
Fahim Farook
f
"On the Importance of Noise Scheduling for Diffusion Models. (arXiv:2301.10972v1 [cs.CV])" — A study of the effect of noise scheduling strategies for denoising diffusion generative models which finds that the noise scheduling is crucial for performance.
Paper: http://arxiv.org/abs/2301.10972
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Random samples generated by our…

Paper: http://arxiv.org/abs/2301.10972
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Random samples generated by our…
0
1
0
Fahim Farook
f
"ITstyler: Image-optimized Text-based Style Transfer. (arXiv:2301.10916v1 [cs.CV])" — A data-efficient text-based style transfer method that does not require optimization at the inference stage where the text input is converted to the style space of the pre-trained VGG network to realize a more effective style swap.
Paper: http://arxiv.org/abs/2301.10916
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview stylization results of…

Paper: http://arxiv.org/abs/2301.10916
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview stylization results of…
0
1
0
Fahim Farook
f
"Distilling Cognitive Backdoor Patterns within an Image. (arXiv:2301.10908v1 [cs.LG])" — A simple method to distill and detect backdoor patterns within an image by extracting the "minimal essence" from an input image responsible for the model's prediction.
Paper: http://arxiv.org/abs/2301.10908
Code: https://github.com/HanxunH/CognitiveDistillation
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
On the left, First row: a clean…

Paper: http://arxiv.org/abs/2301.10908
Code: https://github.com/HanxunH/CognitiveDistillation
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
On the left, First row: a clean…
0
1
0
Fahim Farook
f
"Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners. (arXiv:2108.13161v7 [cs.CL] CROSS LISTED)" — A novel pluggable, extensible, and efficient large-scale pre-trained language model approach which can convert small language models into better few-shot learners without any prompt engineering.
Paper: http://arxiv.org/abs/2108.13161
Code: https://github.com/zjunlp/DART
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of DifferentiA…
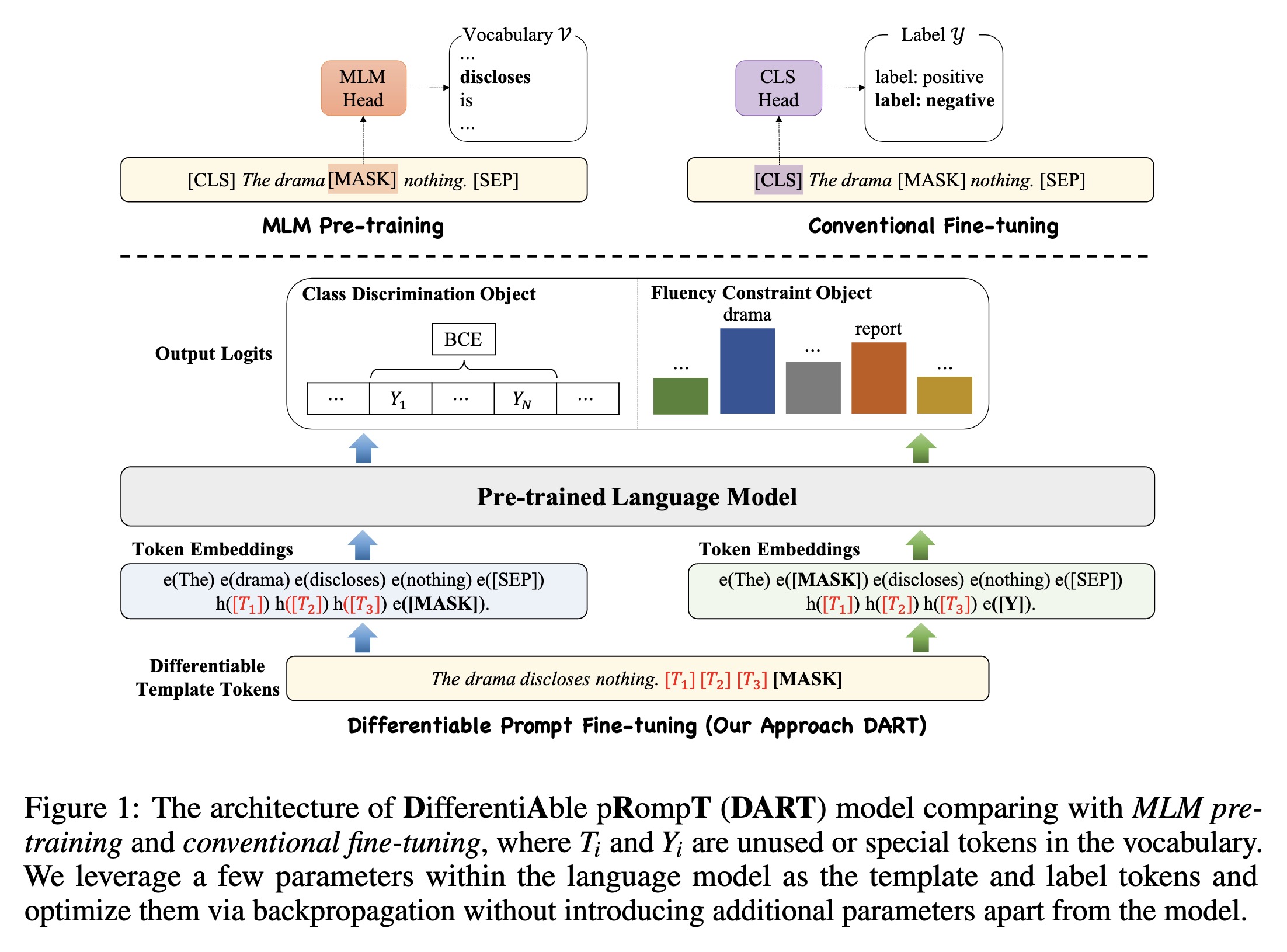
Paper: http://arxiv.org/abs/2108.13161
Code: https://github.com/zjunlp/DART
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of DifferentiA…
0
3
2
Fahim Farook
f
"VN-Transformer: Rotation-Equivariant Attention for Vector Neurons. (arXiv:2206.04176v3 [cs.CV] UPDATED)" — A novel "VN-Transformer" architecture to address several shortcomings of the current Vector Neuron (VN) models.
Paper: http://arxiv.org/abs/2206.04176
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VN-Transformer (“early fusion”)…
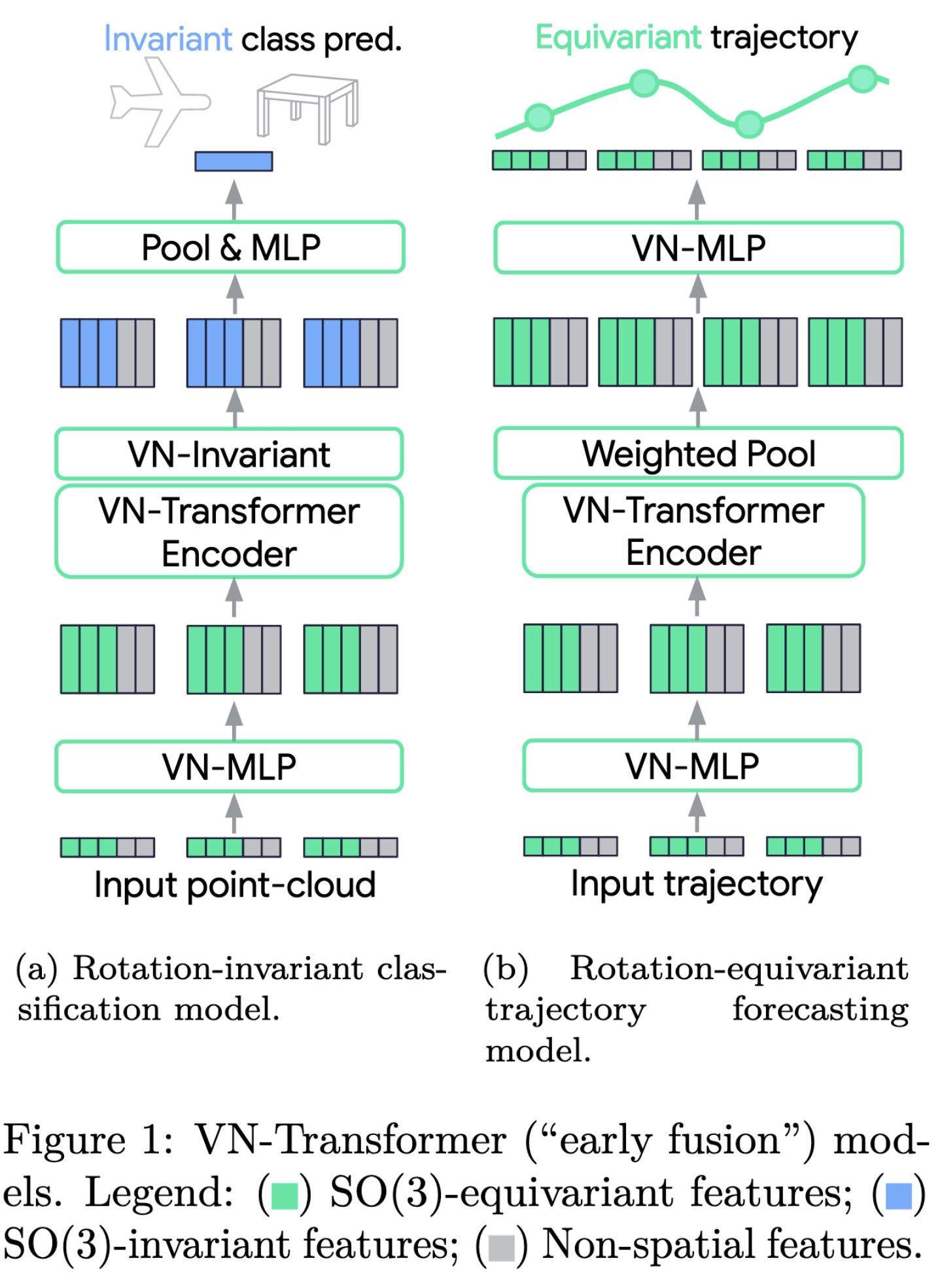
Paper: http://arxiv.org/abs/2206.04176
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VN-Transformer (“early fusion”)…
0
1
0