Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
 repeated
repeated
MicheleV_AK
MicheleV_AK@sfba.social
Sunset over Kodiak this evening. #Alaska
📸 by Kris Luckenbach

 0
4
0
4
 1
repeated
1
repeated
Jodene Lea 🦋
Jodene_Lea@universeodon.comSpace on an #AtomicScale.
This is the most accurate photo of an #atom.
Learn more about this photo:
https://www.thespaceacademy.org/2023/01/this-is-most-accurate-image-of-atom.html?m=1
 1
3
1
repeated
1
3
1
repeated
Jonathan Rollans
jrollans@pixelfed.social#Colorado #Sunflower #Garden
 0
3
1
repeated
0
3
1
repeated
MicheleV_AK
MicheleV_AK@sfba.socialStephen Dunn took this incredible photograph with his flash illuminating a spider and revealing its wet web with a rainbow effect. 😲 💗
 3
3
1
repeated
3
3
1
repeated
Just Past the Ice Cream Truck is the name of this Matt Beard painting.
I super wanted one of his poppy pieces but had missed out the year before.
I put in my request and waited patiently and was eventually rewarded with this piece.
Love, love the colors.
I am guessing by the name that he wasn't the only one there to see the poppy bloom.
Nowhere near Humboldt for sure.
#MattBeard
 1
2
1
repeated
1
2
1
repeated
 repeated
repeated
Andrey Kurenkov
andrey@sigmoid.socialMusicLM is pretty dang cool! Even with it being kind of only a matter of time.
The fact it can create music for painting is pretty crazy. Some curveballs in there, but the model seemed to have handled it well. Wonder how cherrypicked these were.
https://google-research.github.io/seanet/musiclm/examples/

 0
1
0
0
1
0
Fahim Farook
fBut I didn’t like the summaries since they didn’t really tell me much 😛 So, I modified the system to download the PDF papers and to give me an overview of the papers each day. From that, I went to adding a form to the paper view so that I can post a summary and a page screen grab to Mastodon.
The posting system kind of fell by the wayside (I post manually now) due to various issues, but I also added a system which tracks the papers I skip and the ones I post about so that I can track things. That’s where it stands since I now post daily about new papers in the cs.CV category since some people seem to find that useful 🙂
1
1
1
Fahim Farook
fSee y'all next week 🙂
#AI #CV #NewPapers #DeepLearning #MachineLearning
1
0
1
Fahim Farook
fPaper: http://arxiv.org/abs/2209.10497
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Interactive segmentation: Green…
 0
1
1
0
1
1
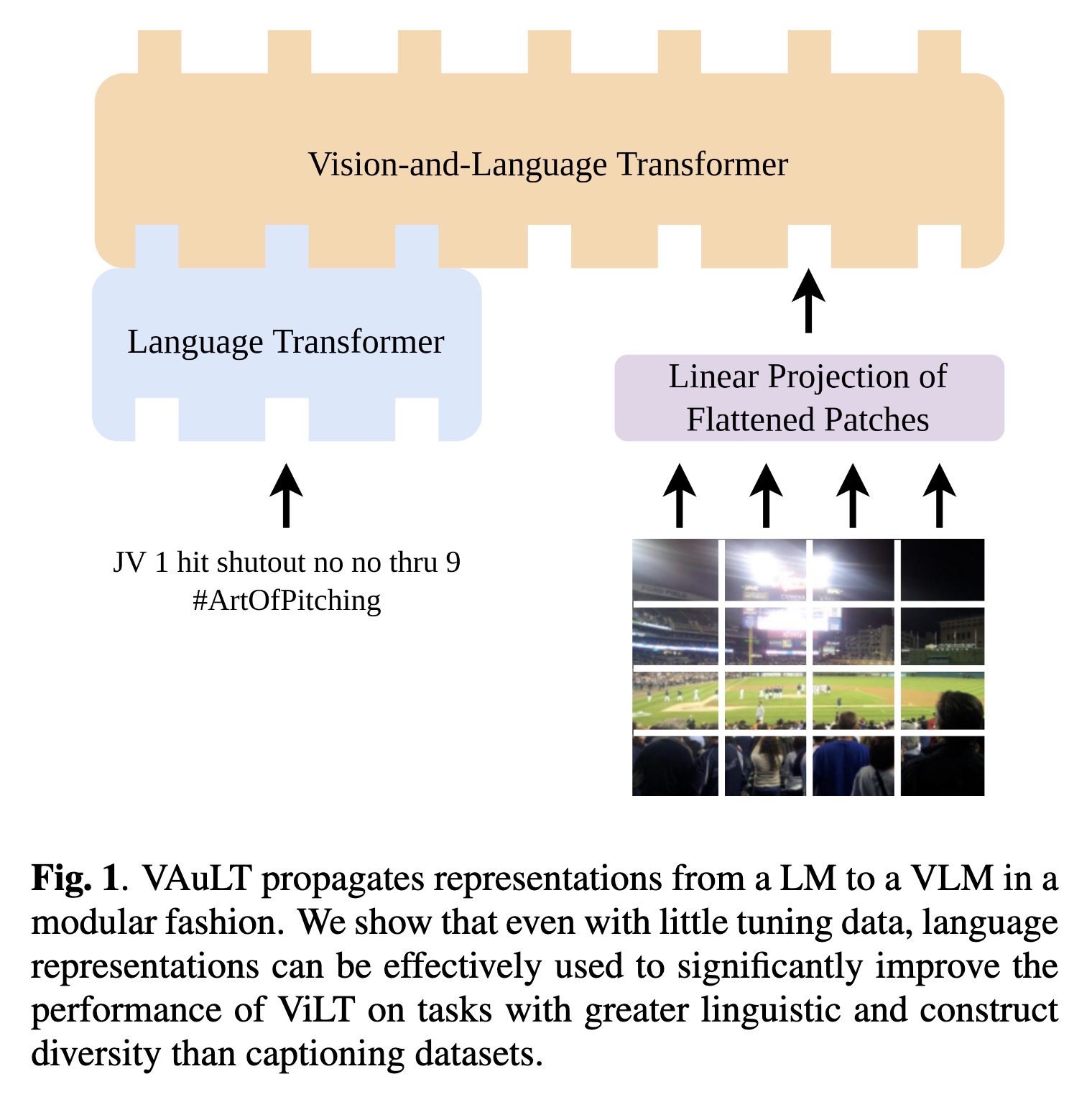
Fahim Farook
fPaper: http://arxiv.org/abs/2208.09021
Code: https://github.com/gchochla/vault
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
VAuLT propagates representation…
 0
1
0
0
1
0
Fahim Farook
fPaper: http://arxiv.org/abs/2207.12850
Code: https://github.com/Ti-Oluwanimi/Violence_Detection
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Salient Image: A sequence of vi…
 0
1
0
0
1
0
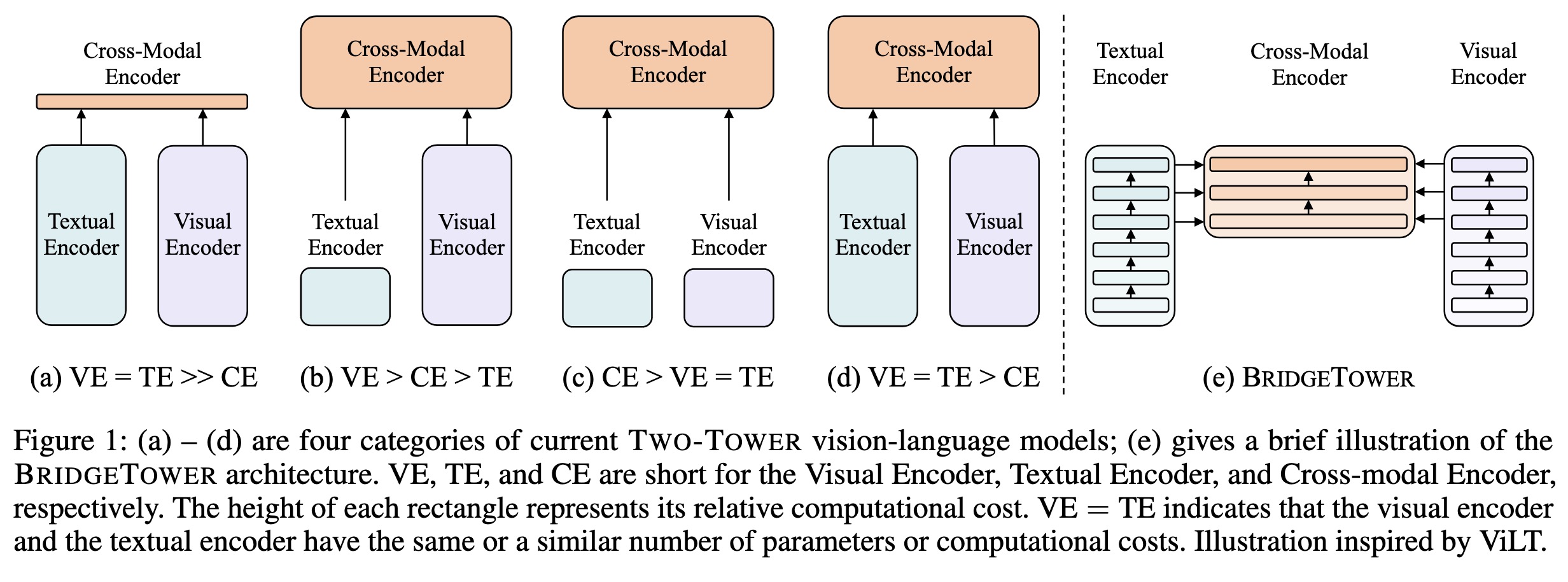
Fahim Farook
fPaper: http://arxiv.org/abs/2206.08657
Code: https://github.com/microsoft/BridgeTower
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) – (d) are four categories o…
 0
1
0
0
1
0
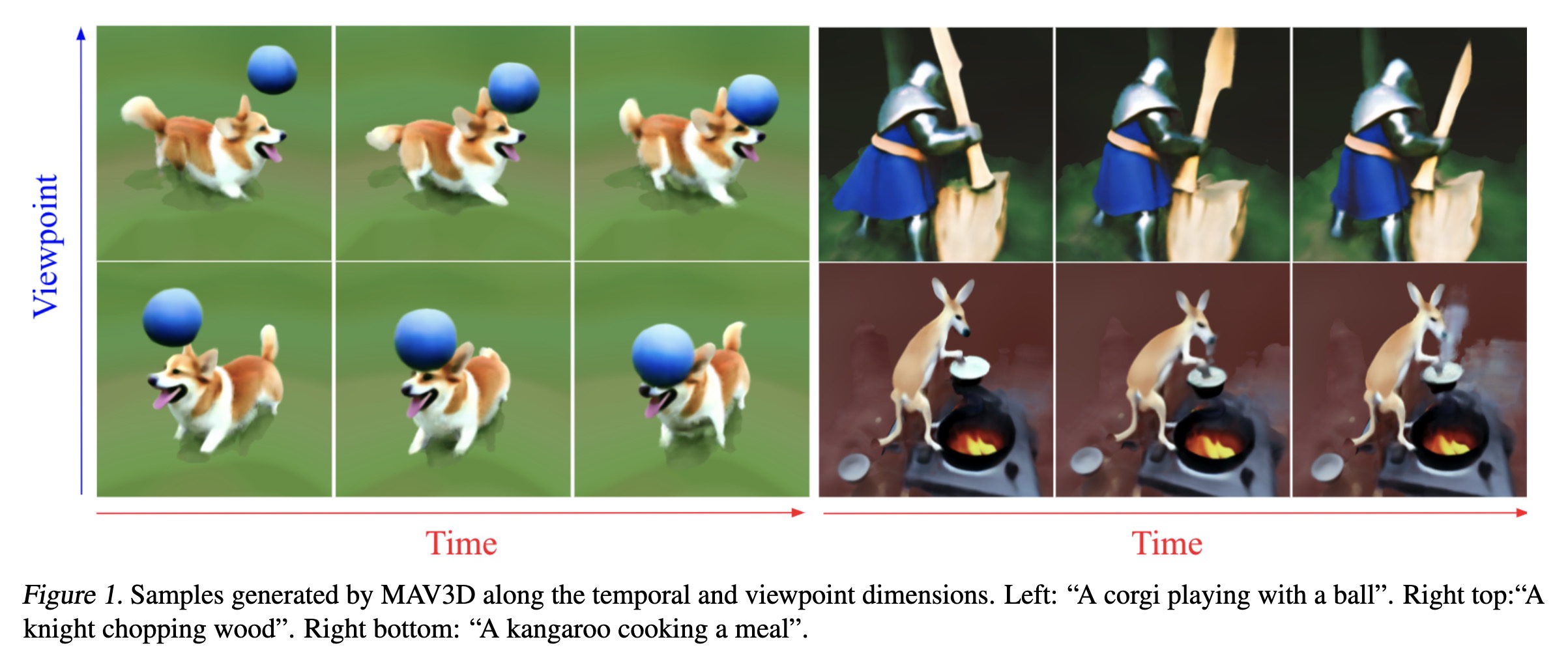
Fahim Farook
fPaper: http://arxiv.org/abs/2301.11280
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by MAV3D alon…
 0
1
1
0
1
1
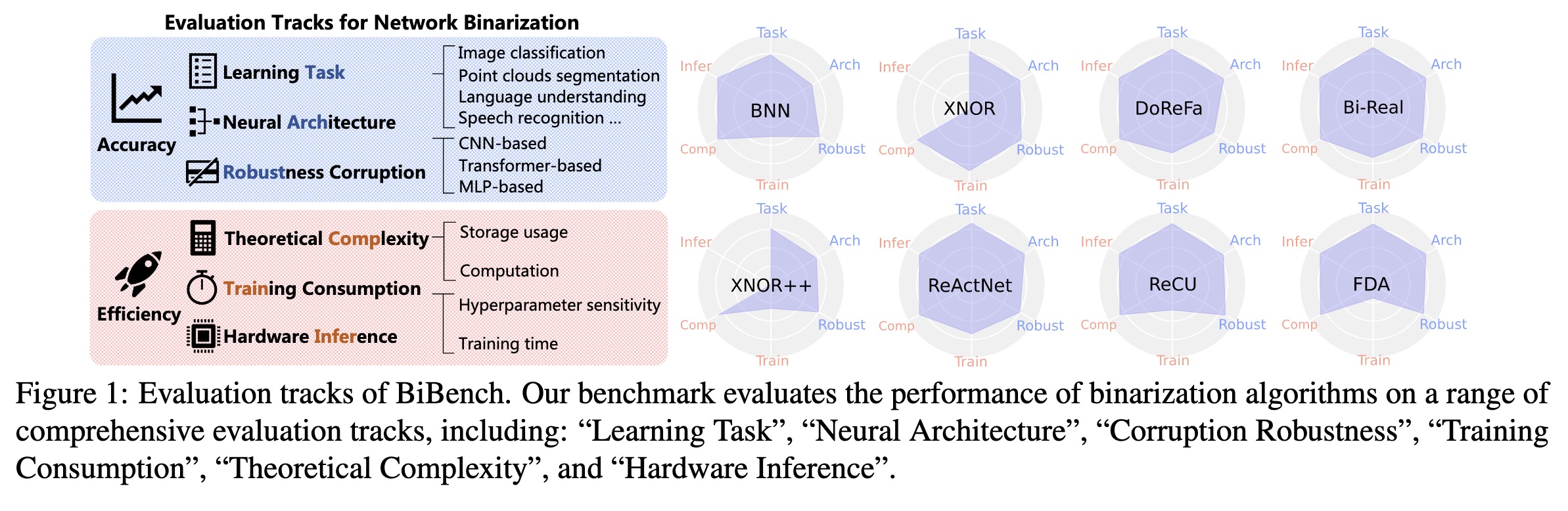
Fahim Farook
fPaper: http://arxiv.org/abs/2301.11233
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Evaluation tracks of BiBench. O…
 0
1
0
0
1
0
Fahim Farook
fPaper: http://arxiv.org/abs/2301.11189
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of distortion vs. st…
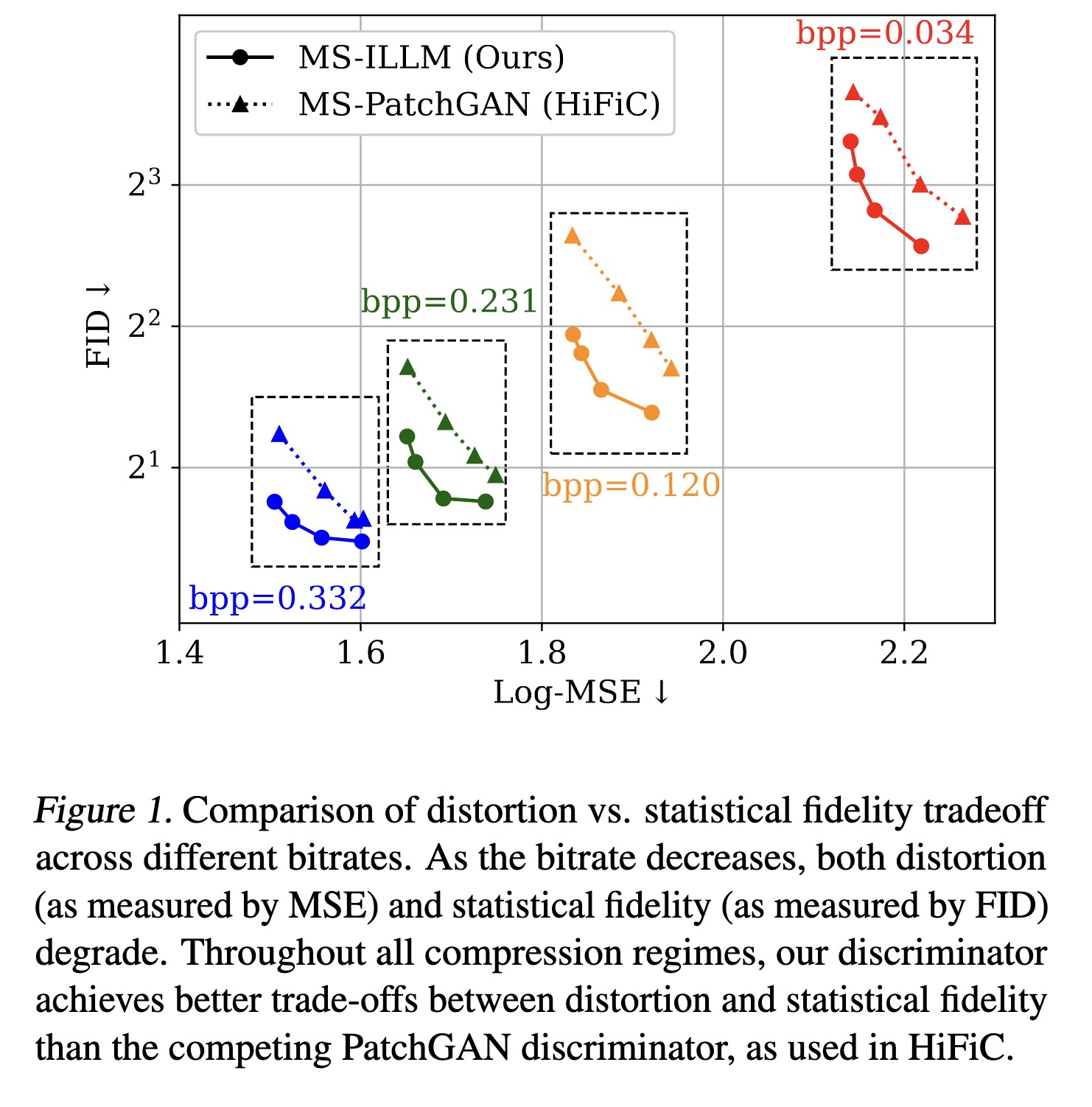 0
0
0
0
0
0
Fahim Farook
fPaper: http://arxiv.org/abs/2301.11116
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) Illustration of temporal mo…
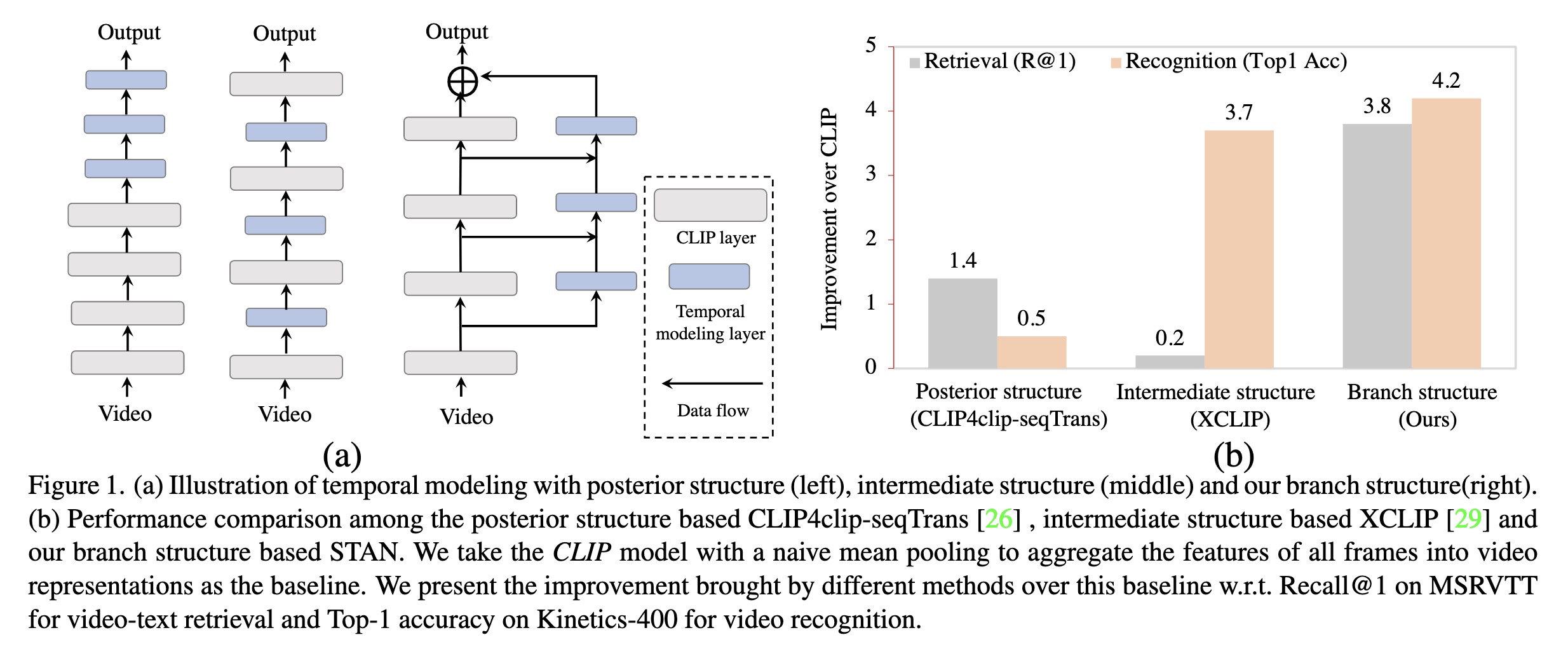 0
1
0
0
1
0
Fahim Farook
fPaper: http://arxiv.org/abs/2301.11104
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of the proposed bias-to…
 0
1
0
0
1
0
Fahim Farook
fPaper: http://arxiv.org/abs/2301.11100
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a) The average precision (AP) …
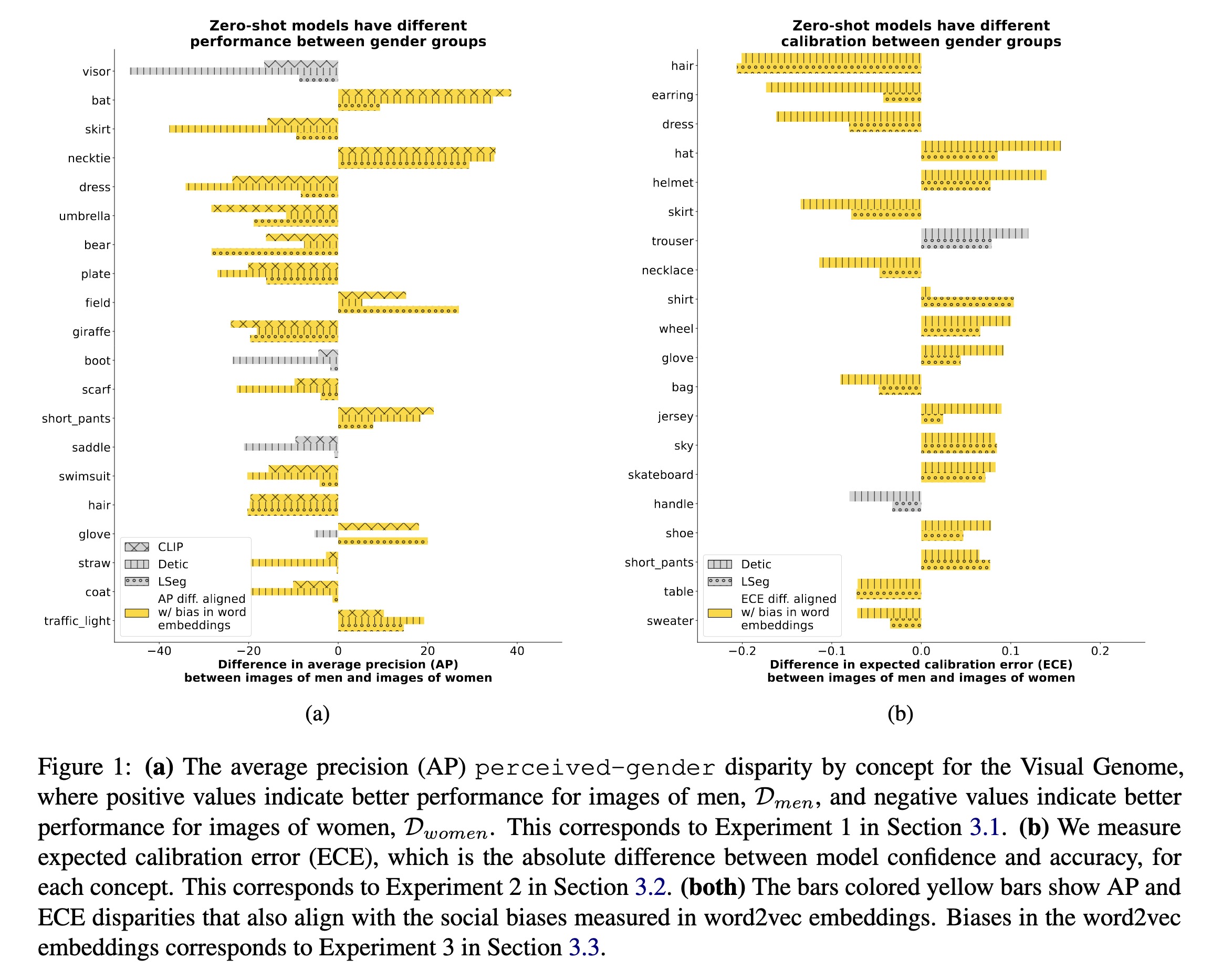 0
0
0
0
0
0