Fahim Farook
Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"Extended Agriculture-Vision: An Extension of a Large Aerial Image Dataset for Agricultural Pattern Analysis. (arXiv:2303.02460v1 [cs.CV])" — What it says in the title, an improved dataset for agricultural pattern analysis.
Paper: http://arxiv.org/abs/2303.02460
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: Full-field imagery (RGB-o…

Paper: http://arxiv.org/abs/2303.02460
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: Full-field imagery (RGB-o…
 0
0
 2
2
 0
0
Fahim Farook
f
"Diffusion Models Generate Images Like Painters: an Analytical Theory of Outline First, Details Later. (arXiv:2303.02490v1 [cs.CV])" — An exploration of the the theory that diffusion models generate images like painters creating a painting: that it involves first committing to an outline, and then adding in finer details.
Paper: http://arxiv.org/abs/2303.02490
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Characteristics of image genera…

Paper: http://arxiv.org/abs/2303.02490
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Characteristics of image genera…
0
3
2
Fahim Farook
f
"All are Worth Words: A ViT Backbone for Diffusion Models. (arXiv:2209.12152v3 [cs.CV] UPDATED)" — A simple and general ViT-based architecture for image generation with diffusion models which is capable of unconditional and class-conditional image generation, as well as text-to-image generation tasks.
Paper: http://arxiv.org/abs/2209.12152
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Text-to-image generation on MS-…

Paper: http://arxiv.org/abs/2209.12152
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Text-to-image generation on MS-…
0
0
0
Fahim Farook
f
A little bit more on the Edge browser and all the interesting activities it has built-in …
It has this little page of activities that you can try. One of them was to solve a tile puzzle — an image split into tiles and mixed up that you have to arrange corectly.
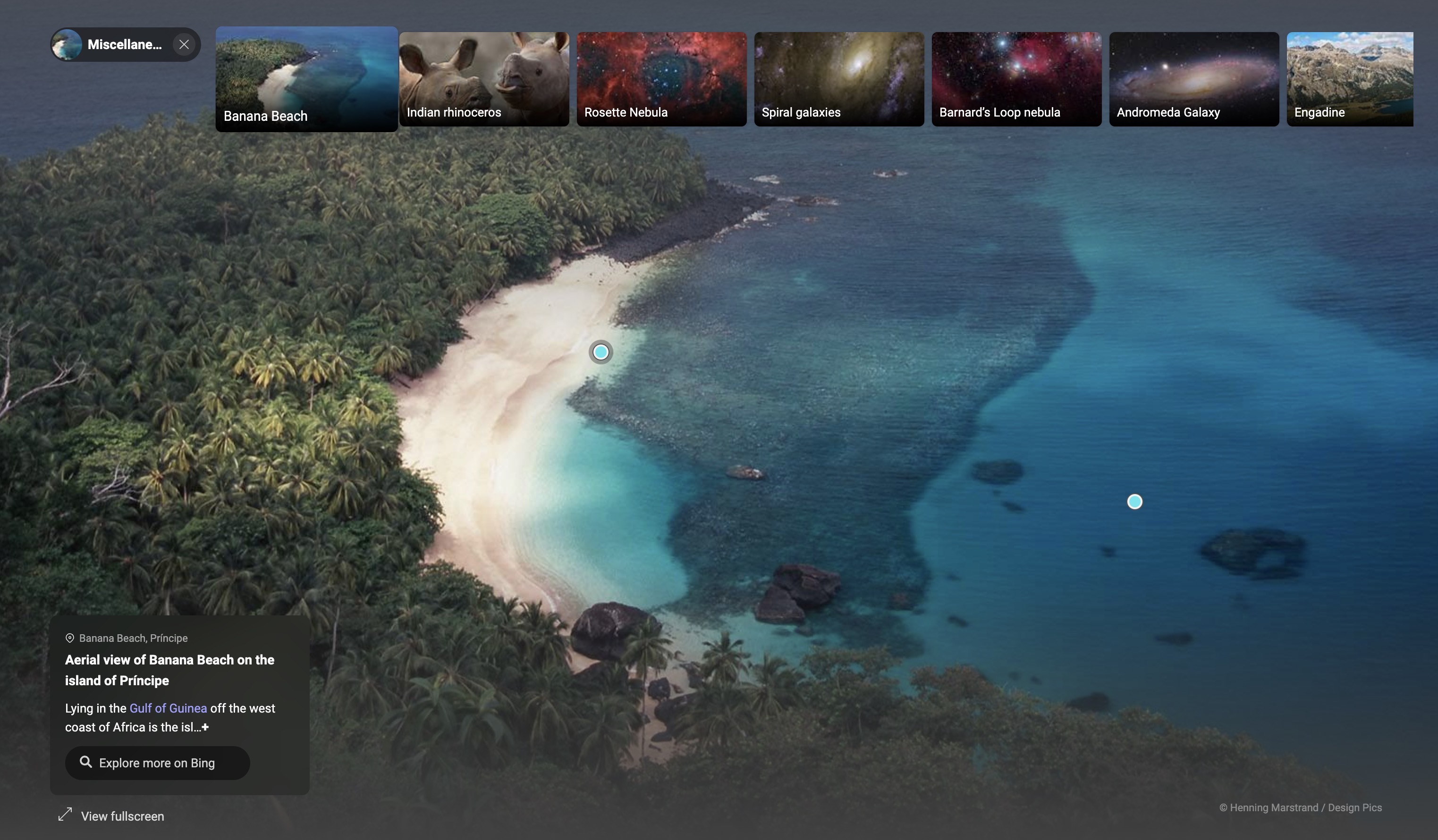
Once you complete the image, you get more information about the image and hotspots on the image you can click to get more information. If you click on a hotspot, you are taken to a Bing page with photos, relevant links, and a sidebar with additional links that you can explore.
As somebody who loves learning esoteric things, this just feels like the first time I discovered an encyclopaedia, but a lot more fun 🙂
#Edge #Browser #Gamification #Bing
An image of a tile/card which s…
A beautiful image of a bay with…
A Bing page with information ab…
It has this little page of activities that you can try. One of them was to solve a tile puzzle — an image split into tiles and mixed up that you have to arrange corectly.
Once you complete the image, you get more information about the image and hotspots on the image you can click to get more information. If you click on a hotspot, you are taken to a Bing page with photos, relevant links, and a sidebar with additional links that you can explore.
As somebody who loves learning esoteric things, this just feels like the first time I discovered an encyclopaedia, but a lot more fun 🙂
#Edge #Browser #Gamification #Bing
An image of a tile/card which s…
A beautiful image of a bay with…
A Bing page with information ab…
0
1
1
Fahim Farook
f
"Defending against Adversarial Audio via Diffusion Model" — Using diffusion models to purify/remove adversarial audio which can cause abnormal behaviour in acoustic systems.
Paper: https://arxiv.org/abs/2303.01507
Code: https://github.com/cychomatica/AudioPure
#AI #NewPaper #DeepLearning #MachineLearning #Sound #Security #Audio #Cryptograpy
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of the whole a…
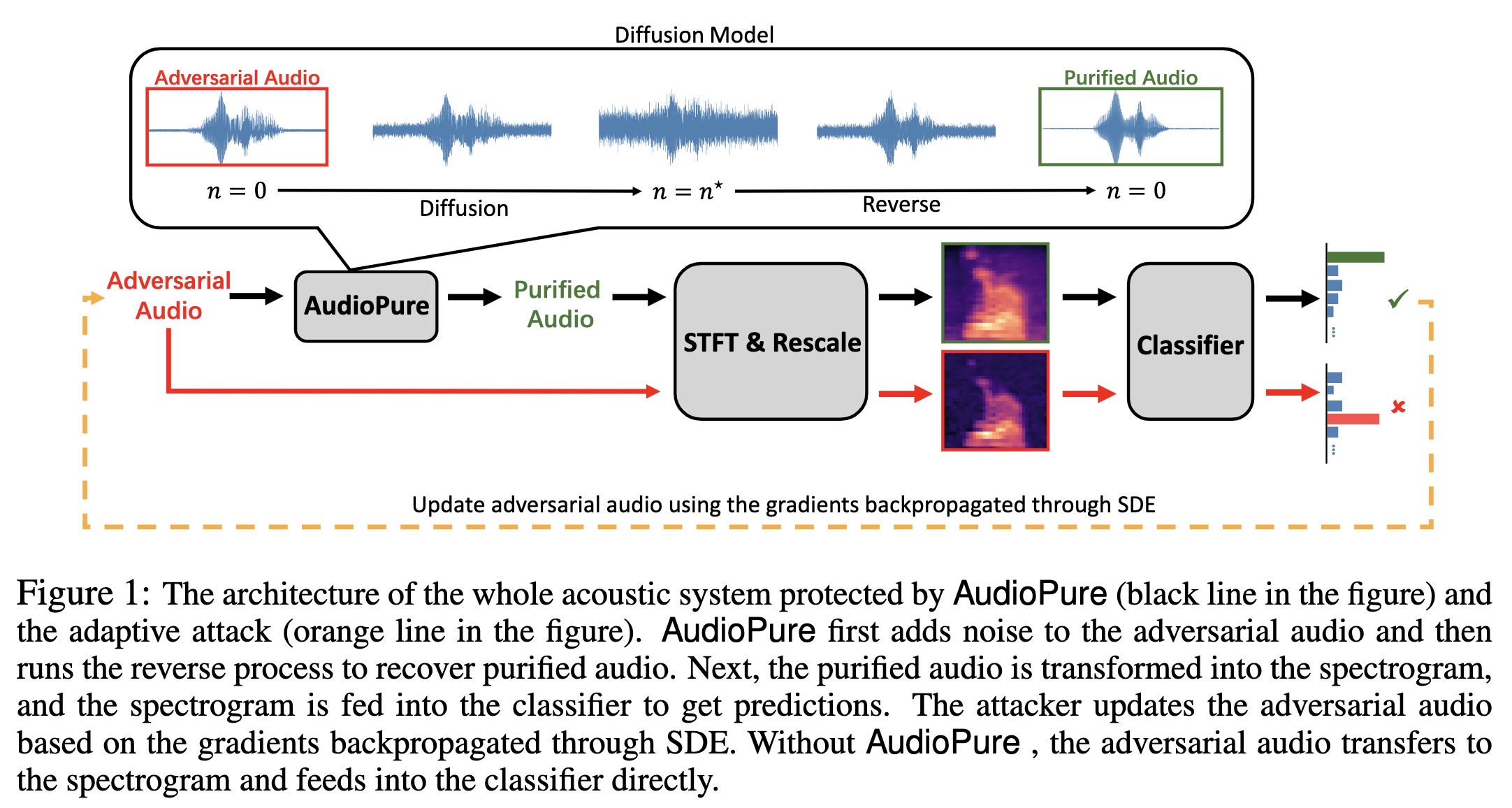
Paper: https://arxiv.org/abs/2303.01507
Code: https://github.com/cychomatica/AudioPure
#AI #NewPaper #DeepLearning #MachineLearning #Sound #Security #Audio #Cryptograpy
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of the whole a…
0
0
0
Fahim Farook
f
"Word-As-Image for Semantic Typography. (arXiv:2303.01818v1 [cs.CV])" — Automatically visualizing words by modifying the typography to depict the meaning/representation of the word.
Paper: http://arxiv.org/abs/2303.01818
Note: No code or demo available (yet) at the linked locations.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A few examples of our word-as-i…

Paper: http://arxiv.org/abs/2303.01818
Note: No code or demo available (yet) at the linked locations.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A few examples of our word-as-i…
0
3
1
Fahim Farook
f
"Unleashing Text-to-Image Diffusion Models for Visual Perception. (arXiv:2303.02153v1 [cs.CV])" — Using the pre-trained autoencoder in a diffusion model for visual perception tasks such as segmentation or depth estimation.
Paper: http://arxiv.org/abs/2303.02153
Code: https://github.com/wl-zhao/VPD
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The main idea of the proposed V…

Paper: http://arxiv.org/abs/2303.02153
Code: https://github.com/wl-zhao/VPD
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The main idea of the proposed V…
0
2
0
Fahim Farook
f
"Consistency Models. (arXiv:2303.01469v1 [cs.LG])" — A new family of generative models that achieve high sample quality without adversarial training that supports fast one-step generation by design.
Paper: http://arxiv.org/abs/2303.01469
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by EDM (top),…

Paper: http://arxiv.org/abs/2303.01469
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by EDM (top),…
0
1
0
Fahim Farook
f
"3D generation on ImageNet. (arXiv:2303.01416v1 [cs.CV])" — A more detailed/accurate method to generate 3D images based on 2D input images.
Paper: http://arxiv.org/abs/2303.01416
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Selected samples from EG3D (Cha…

Paper: http://arxiv.org/abs/2303.01416
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Selected samples from EG3D (Cha…
0
0
0
Fahim Farook
f
"Zero-Shot Text-to-Parameter Translation for Game Character Auto-Creation. (arXiv:2303.01311v1 [cs.CV])" — Generating random game characters simply based on text input instead of customizing a pre-created character's visual attributes.
Paper: http://arxiv.org/abs/2303.01311
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Game characters created by the …

Paper: http://arxiv.org/abs/2303.01311
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Game characters created by the …
0
0
0
Fahim Farook
f
"Combining Generative Artificial Intelligence (AI) and the Internet: Heading towards Evolution or Degradation?. (arXiv:2303.01255v1 [cs.CV])" — Would the quality of generative AI tools be affected if the input images are generated by AI tools themselves? An initial (simulated) experiment to explore this question.
Paper: http://arxiv.org/abs/2303.01255
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two sets of sample images — the…

Paper: http://arxiv.org/abs/2303.01255
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two sets of sample images — the…
1
1
1
Fahim Farook
f
"X&Fuse: Fusing Visual Information in Text-to-Image Generation. (arXiv:2303.01000v1 [cs.CV])" — Multiple ways to condition images prior to text-to-image generation to achieve better output results.
Paper: http://arxiv.org/abs/2303.01000
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
X&Fuse conditions the model on …

Paper: http://arxiv.org/abs/2303.01000
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
X&Fuse conditions the model on …
0
1
1
Fahim Farook
f
"Scalable Diffusion Models with Transformers. (arXiv:2212.09748v2 [cs.CV] UPDATED)" — Creating diffusion models that use transformers instead UNets.
Paper: http://arxiv.org/abs/2212.09748
Code: https://github.com/facebookresearch/DiT
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion models with transform…

Paper: http://arxiv.org/abs/2212.09748
Code: https://github.com/facebookresearch/DiT
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion models with transform…
0
0
1
Fahim Farook
f
"Collage Diffusion. (arXiv:2303.00262v1 [cs.CV])" — Creating harmonious and cohesive output images based on a text prompt and a collection of images as input.
Paper: http://arxiv.org/abs/2303.00262
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Collage Diffusion creates globa…
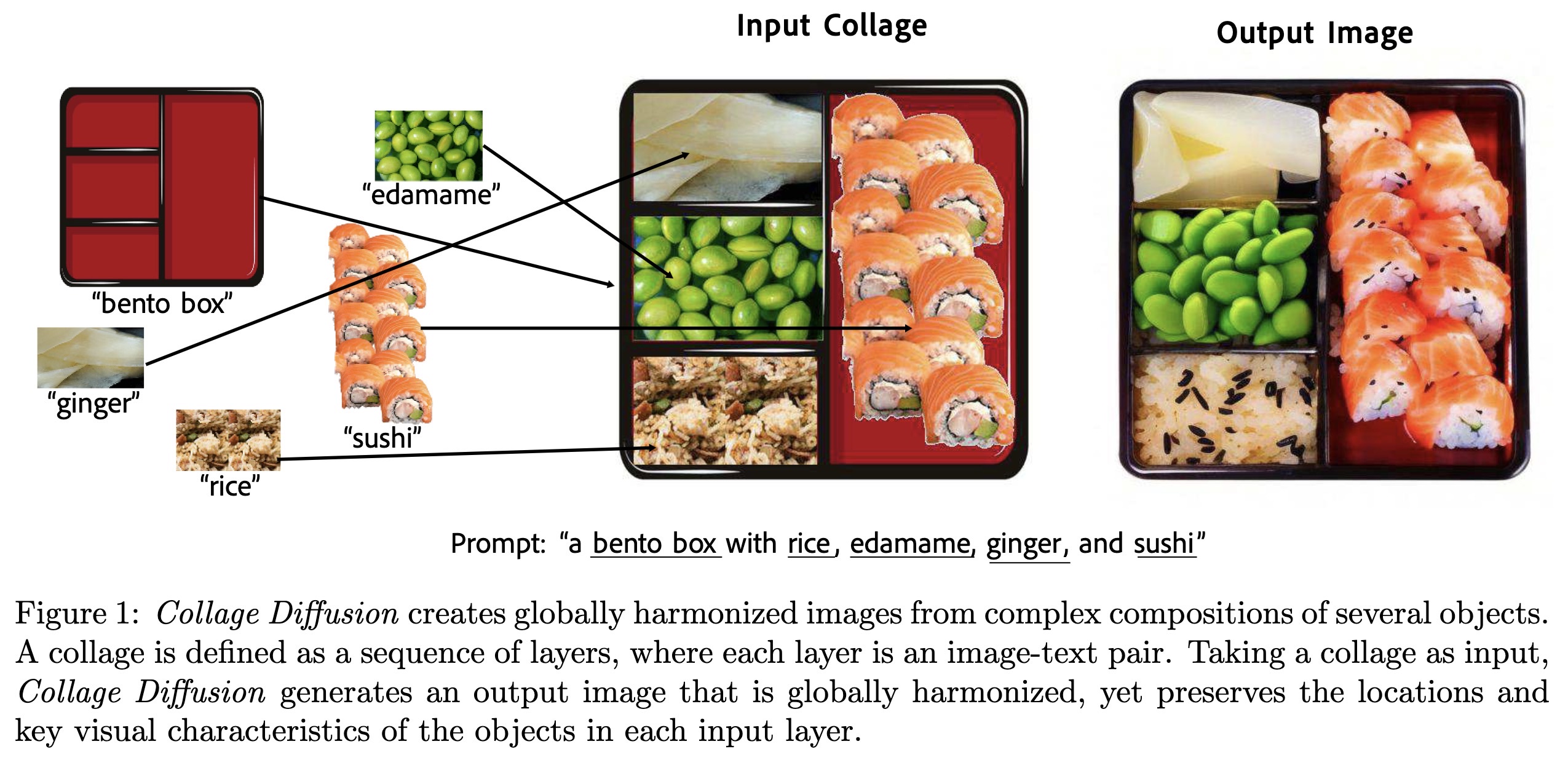
Paper: http://arxiv.org/abs/2303.00262
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Collage Diffusion creates globa…
0
0
1
Fahim Farook
f
"PixHt-Lab: Pixel Height Based Light Effect Generation for Image Compositing. (arXiv:2303.00137v1 [cs.CV])" — Generating realistic shadows and reflections using 2D images and deep learning techniques.
Paper: http://arxiv.org/abs/2303.00137
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
PixHt-Lab renders realistic ref…

Paper: http://arxiv.org/abs/2303.00137
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
PixHt-Lab renders realistic ref…
0
0
0
Fahim Farook
f
"Magic: Multi Art Genre Intelligent Choreography Dataset and Network for 3D Dance Generation. (arXiv:2212.03741v3 [cs.CV] UPDATED)" — A choreography dataset and a network for generating 3D dance segments based on a music clip as input.
Paper: http://arxiv.org/abs/2212.03741
Note: v3 of the paper is currently not available in PDF form on arXiv.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A conceptual overview of Magic.…
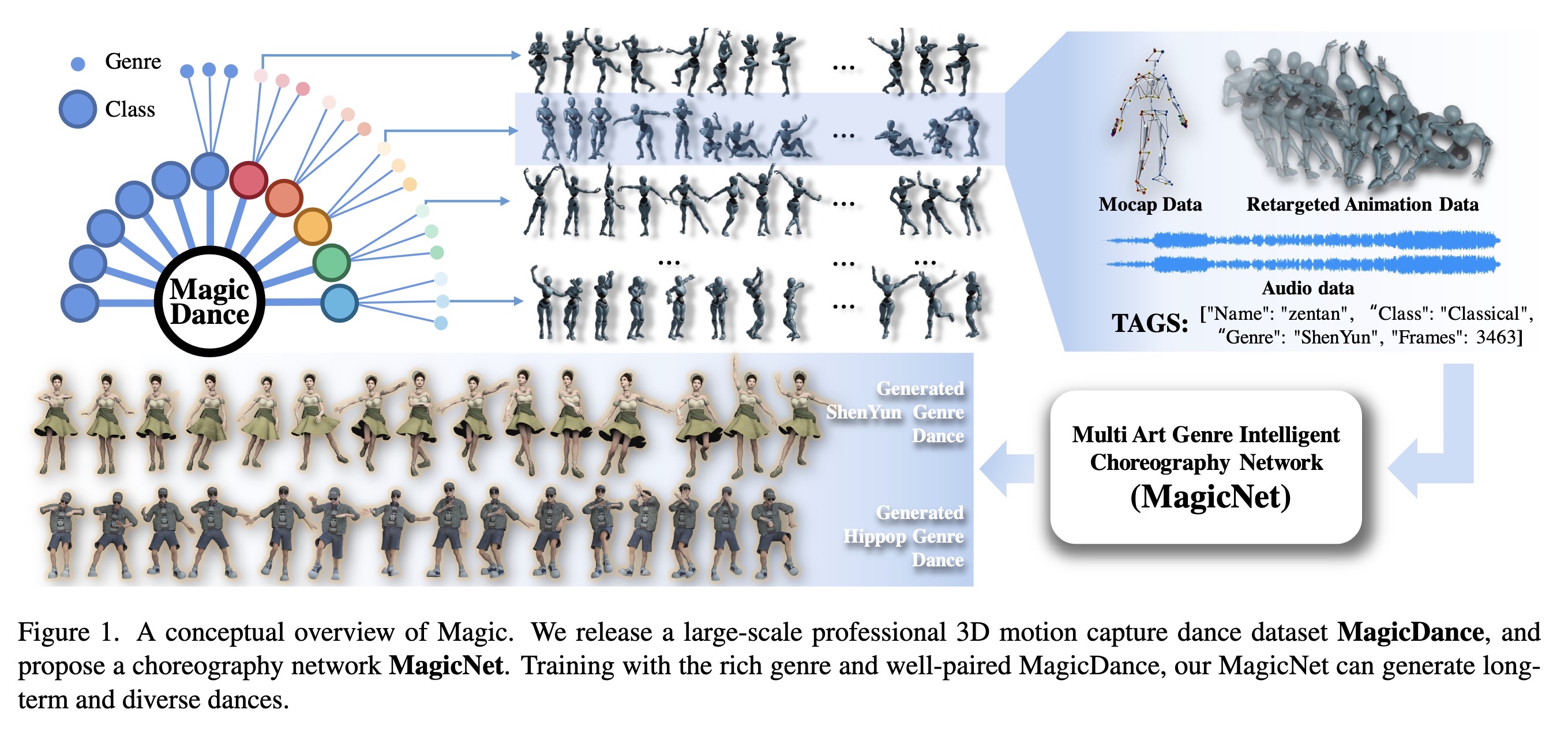
Paper: http://arxiv.org/abs/2212.03741
Note: v3 of the paper is currently not available in PDF form on arXiv.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A conceptual overview of Magic.…
0
1
0
Fahim Farook
f
"Meta Learning to Bridge Vision and Language Models for Multimodal Few-Shot Learning. (arXiv:2302.14794v1 [cs.CV])" — Rather than using a frozen language model to communicate visual concepts, this method uses a meta -mapper to act as a bridge between large-scale visiona and language models.
Paper: http://arxiv.org/abs/2302.14794
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multimodal few-shot meta-learni…

Paper: http://arxiv.org/abs/2302.14794
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multimodal few-shot meta-learni…
0
0
1
Fahim Farook
f
"TextIR: A Simple Framework for Text-based Editable Image Restoration. (arXiv:2302.14736v1 [cs.CV])" — Using text input to restore damaged images by specifying how to fill in the damage areas by way of text descriptions.
Paper: http://arxiv.org/abs/2302.14736
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of image restoration r…

Paper: http://arxiv.org/abs/2302.14736
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of image restoration r…
0
0
0
Fahim Farook
f
"Towards Enhanced Controllability of Diffusion Models. (arXiv:2302.14368v1 [cs.CV])" — Creating a diffusion model that is easier to edit/style based on input images by conditioning the model on a spatial content mask and a flattened style embedding.
Paper: http://arxiv.org/abs/2302.14368
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of the proposed mode…

Paper: http://arxiv.org/abs/2302.14368
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of the proposed mode…
0
0
0
Fahim Farook
f
"One-Shot Video Inpainting. (arXiv:2302.14362v1 [cs.CV])" — A method to inpaint videos where instead of having to provide masks for each frame, you only need to provide the object mask for the initial frame in the video sequence.
Paper: http://arxiv.org/abs/2302.14362
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative comparison between …

Paper: http://arxiv.org/abs/2302.14362
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative comparison between …
0
1
1