Fahim Farook
Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"Deep Learning for Identifying Iran's Cultural Heritage Buildings in Need of Conservation Using Image Classification and Grad-CAM. (arXiv:2302.14354v1 [cs.CV])" — Using machine learning to identify damage and defects to cultural heritage buildings using Convolutional Neural Networks (CNN).
Paper: http://arxiv.org/abs/2302.14354
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparing a picture with small-…

Paper: http://arxiv.org/abs/2302.14354
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparing a picture with small-…
 0
0
 0
0
 1
1
Fahim Farook
f
"Accuracy and Fidelity Comparison of Luna and DALL-E 2 Diffusion-Based Image Generation Systems. (arXiv:2301.01914v2 [cs.CV] UPDATED)" — Comparing the accuracy and fidelity of images generated by DALL-E 2 and Luna, which is Stable Diffusion-based.
Paper: http://arxiv.org/abs/2301.01914
Luna code: https://github.com/slowy07/luna
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Selected image samples from the…

Paper: http://arxiv.org/abs/2301.01914
Luna code: https://github.com/slowy07/luna
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Selected image samples from the…
0
0
1
Fahim Farook
f
"Diffusion Posterior Sampling for General Noisy Inverse Problems. (arXiv:2209.14687v3 [stat.ML] UPDATED)" — Extending diffusion solvers to efficiently handle general noisy (non)linear inverse problems via approximation of the posterior sampling.
Paper: http://arxiv.org/abs/2209.14687
Code: https://github.com/dps2022/diffusion-posterior-sampling
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Solving noisy linear, and nonli…

Paper: http://arxiv.org/abs/2209.14687
Code: https://github.com/dps2022/diffusion-posterior-sampling
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Solving noisy linear, and nonli…
0
0
1
Fahim Farook
f
"Subspace Diffusion Generative Models. (arXiv:2205.01490v2 [cs.LG] UPDATED)" — Restricting diffusion via projections onto subspaces to reduce computational time and cost without affecting the overall quality of the generated image.
Paper: http://arxiv.org/abs/2205.01490
Code: https://github.com/bjing2016/subspace-diffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Random high resolution samples …

Paper: http://arxiv.org/abs/2205.01490
Code: https://github.com/bjing2016/subspace-diffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Random high resolution samples …
0
0
0
Fahim Farook
f
"Large Scale Visual Food Recognition. (arXiv:2103.16107v3 [cs.CV] UPDATED)" — A food dataset with 2,000 categories and over 1 million images that can be used for food recognition.
Paper: http://arxiv.org/abs/2103.16107
Code: https://github.com/Liuyuxinict/prenet/
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The distributions over each cat…
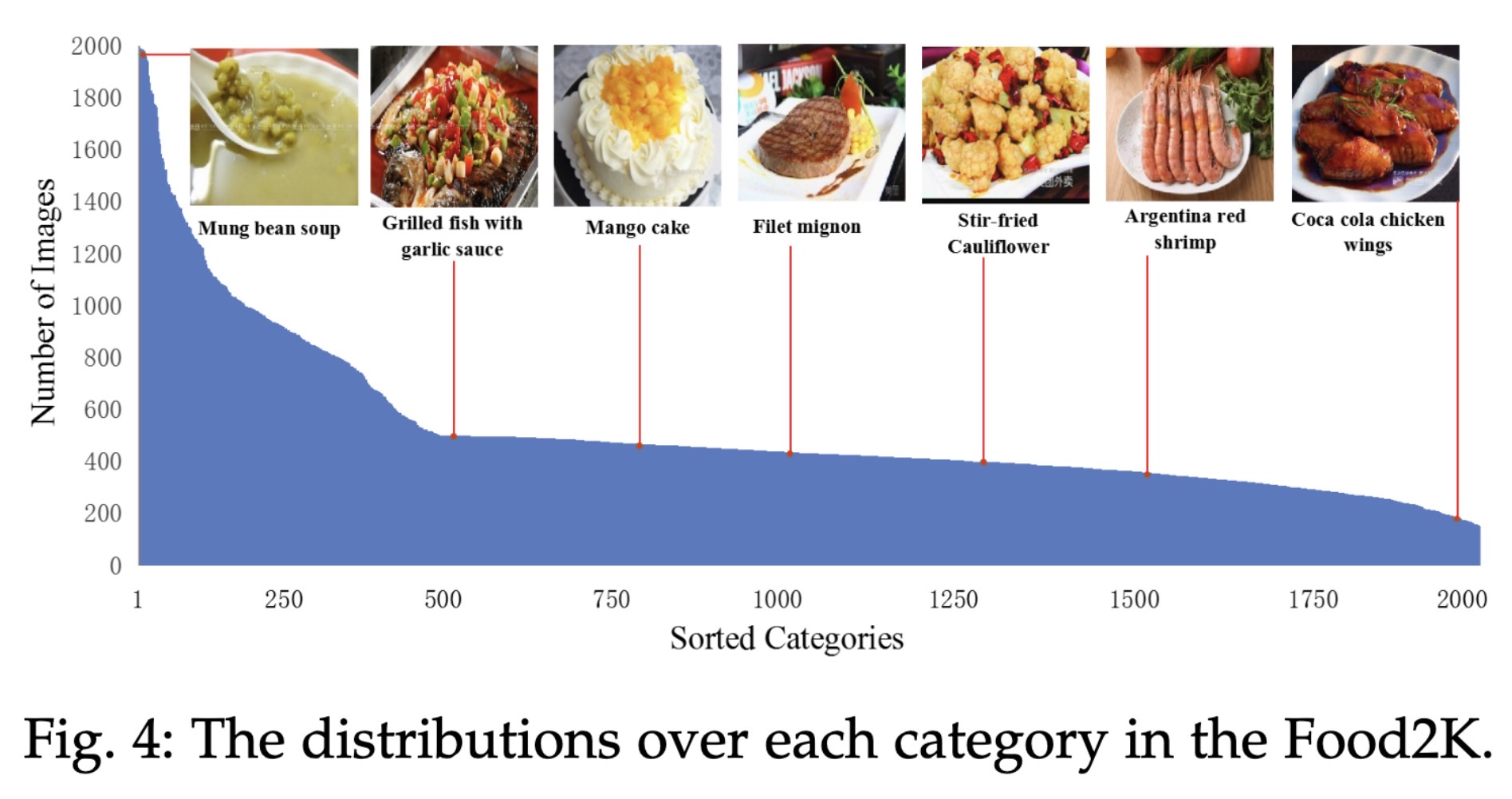
Paper: http://arxiv.org/abs/2103.16107
Code: https://github.com/Liuyuxinict/prenet/
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The distributions over each cat…
0
1
1
Fahim Farook
f
"Directed Diffusion: Direct Control of Object Placement through Attention Guidance. (arXiv:2302.13153v1 [cs.CV])" — Controlling object placement in diffusion models by way of attention guidance.
Paper: http://arxiv.org/abs/2302.13153
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Directed Diffusion (DD) key res…

Paper: http://arxiv.org/abs/2302.13153
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Directed Diffusion (DD) key res…
0
0
1
Fahim Farook
f
"In What Languages are Generative Language Models the Most Formal? Analyzing Formality Distribution across Languages" — Measuring the formality of the generated text for different languages using multilingual generative language models.
Paper: https://arxiv.org/abs/2302.12299
#AI #NewPaper #DeepLearning #MachineLearning #Language
<<Find this useful? Please boost so that others can benefit too 🙂>>
Differences between formal and …
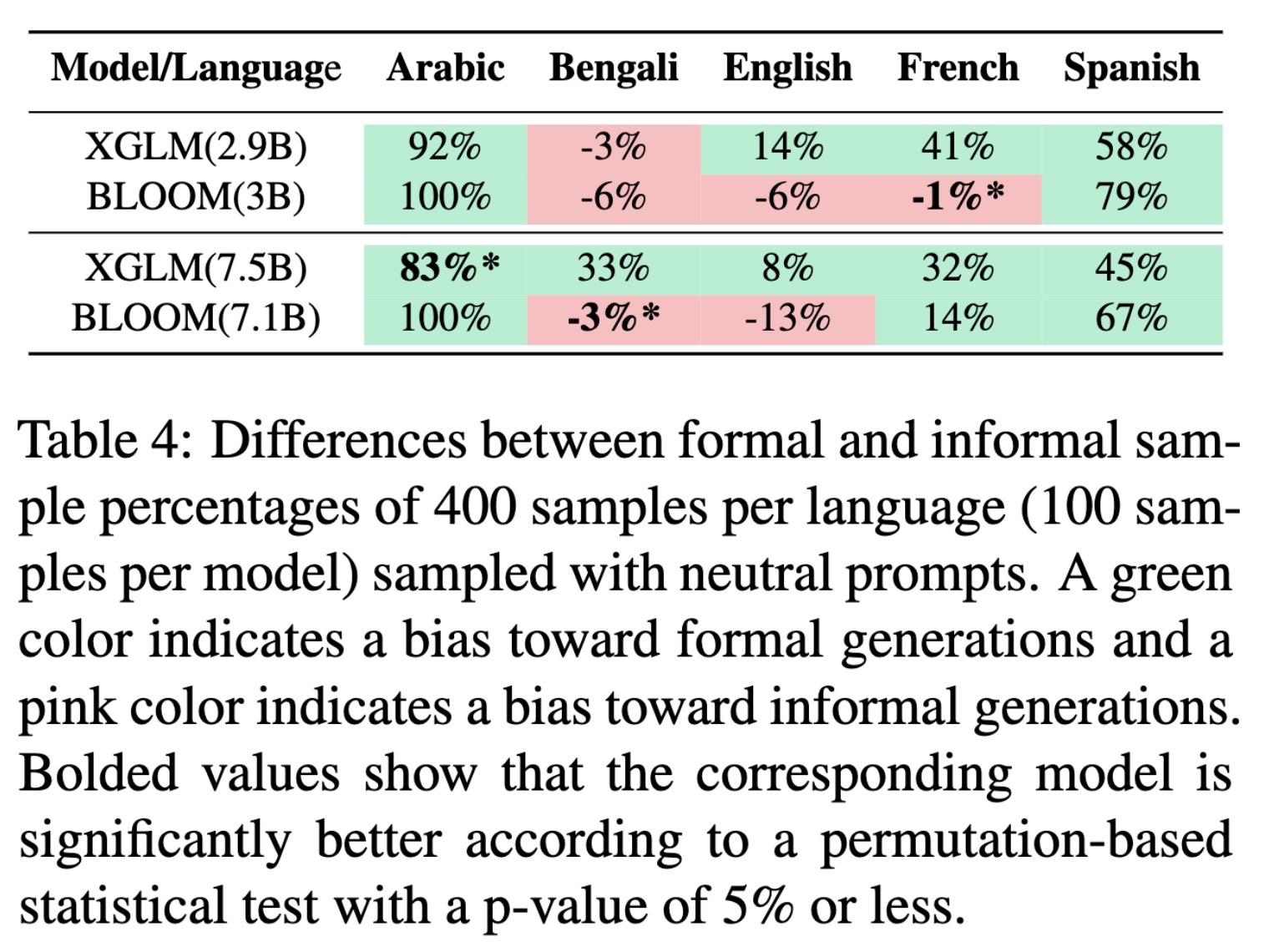
Paper: https://arxiv.org/abs/2302.12299
#AI #NewPaper #DeepLearning #MachineLearning #Language
<<Find this useful? Please boost so that others can benefit too 🙂>>
Differences between formal and …
0
0
1
Fahim Farook
f
"ISS: Image as Stepping Stone for Text-Guided 3D Shape Generation. (arXiv:2209.04145v6 [cs.CV] UPDATED)" — Using 2D images as a stepping stone for creating 3D shapes and eliminating the need for paired text-shape data.
Paper: http://arxiv.org/abs/2209.04145
Code: https://github.com/liuzhengzhe/ISS-Image-as-Stepping-Stone-for-Text-Guided-3D-Shape-Generation
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Our novel “Image as Stepping St…
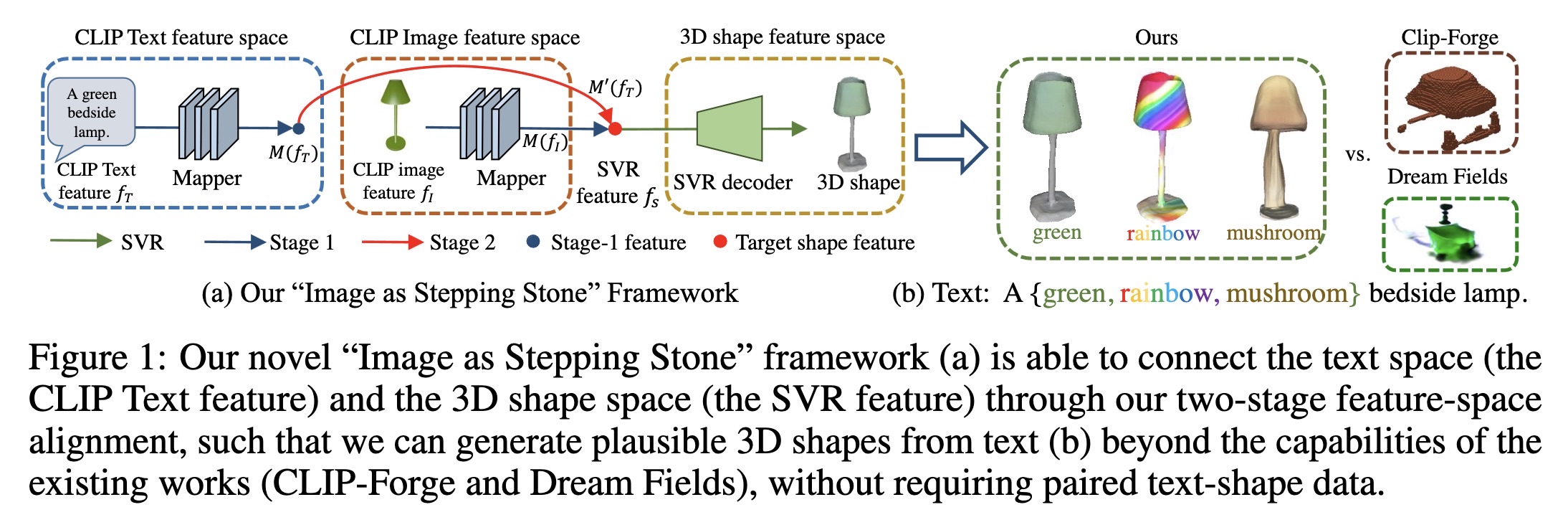
Paper: http://arxiv.org/abs/2209.04145
Code: https://github.com/liuzhengzhe/ISS-Image-as-Stepping-Stone-for-Text-Guided-3D-Shape-Generation
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Our novel “Image as Stepping St…
0
1
2
Fahim Farook
f
"Modulating Pretrained Diffusion Models for Multimodal Image Synthesis. (arXiv:2302.12764v1 [cs.CV])" — Multimodal Conditioning Modules (MCM) for enabling conditional image synthesis using pretrained diffusion models so that you can generate images using not just a text prompt, but additional input such as a segmentation map or a sketch.
Paper: http://arxiv.org/abs/2302.12764
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multimodal conditioning modules…

Paper: http://arxiv.org/abs/2302.12764
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multimodal conditioning modules…
0
1
1
Fahim Farook
f
"Surface Recognition for e-Scooter Using Smartphone IMU Sensor. (arXiv:2302.12720v1 [eess.SP])" — Detecting whether an e-scooter is on a paved road or a sidewalk using the Inertial Measurement Unit (IMU) sensors on a smartphone.
Paper: http://arxiv.org/abs/2302.12720
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: an example of a street wi…

Paper: http://arxiv.org/abs/2302.12720
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: an example of a street wi…
0
1
0
Fahim Farook
f
"Data-driven Approach for Automatically Correcting Faulty Road Maps. (arXiv:2211.06544v2 [cs.CV] UPDATED)" — A method to fix faulty road maps (specifically roads displayed on maps) using machine learning.
Paper: http://arxiv.org/abs/2211.06544
Code: https://github.com/soojunghong/image_inpainting_model_for_lane_geomery_discovery
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
GT, Input, and Output denotes t…
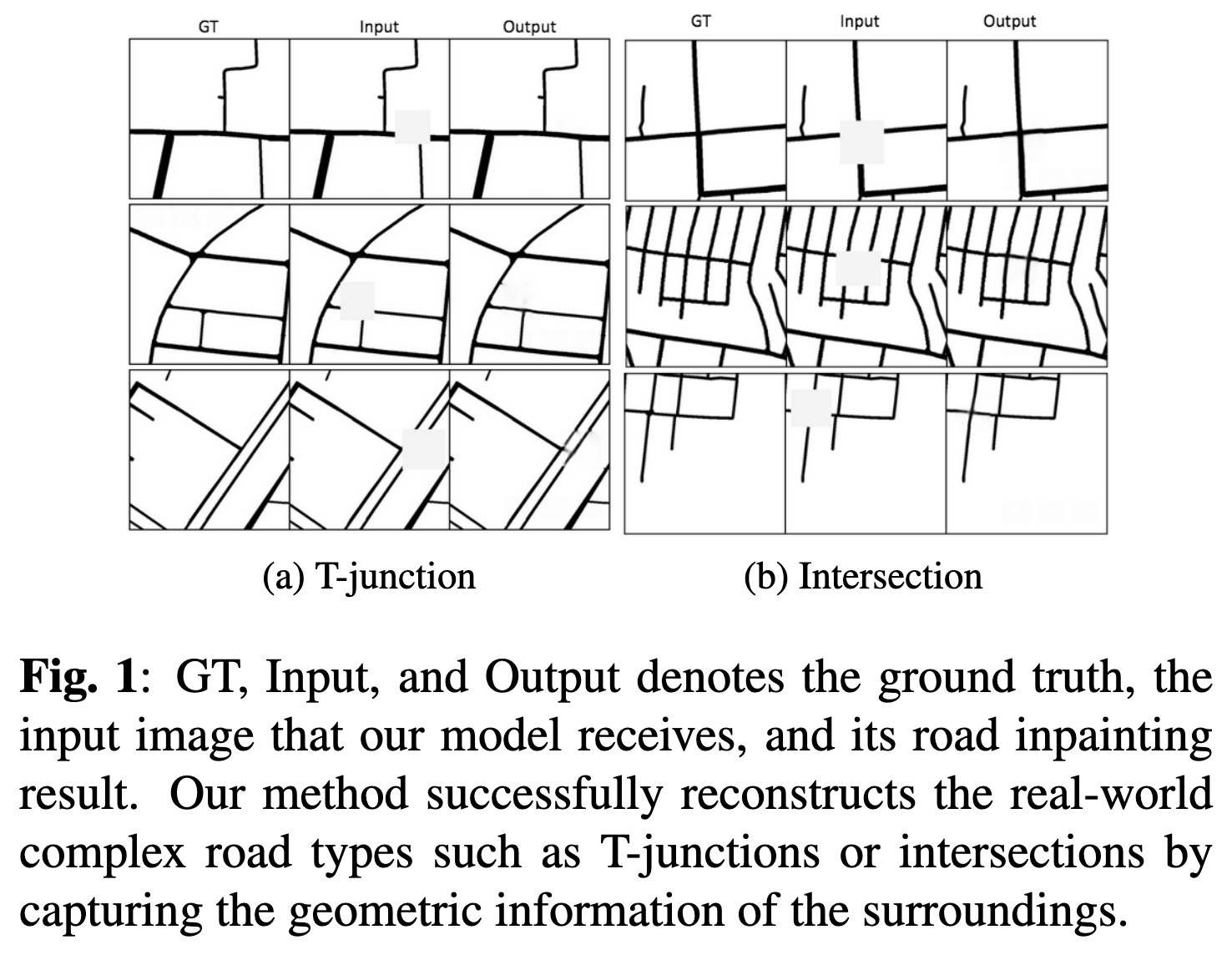
Paper: http://arxiv.org/abs/2211.06544
Code: https://github.com/soojunghong/image_inpainting_model_for_lane_geomery_discovery
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
GT, Input, and Output denotes t…
0
0
0
Fahim Farook
f
"ZITS++: Image Inpainting by Improving the Incremental Transformer on Structural Priors. (arXiv:2210.05950v2 [cs.CV] UPDATED)" — Better image inpainting by detecting structures in the source image using techniques such as edge detection.
Paper: http://arxiv.org/abs/2210.05950
Code: https://github.com/dqiaole/zits_inpainting
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left (a)-(e): Comparisons of ZI…

Paper: http://arxiv.org/abs/2210.05950
Code: https://github.com/dqiaole/zits_inpainting
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left (a)-(e): Comparisons of ZI…
0
0
0
Fahim Farook
f
"Designing an Encoder for Fast Personalization of Text-to-Image Models. (arXiv:2302.12228v1 [cs.CV])" — A method to teach text-to-image models new concepts in seconds.
Paper: http://arxiv.org/abs/2302.12228
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Our encoder-based method enable…

Paper: http://arxiv.org/abs/2302.12228
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Our encoder-based method enable…
0
0
1
Fahim Farook
f
"Aligning Text-to-Image Models using Human Feedback. (arXiv:2302.12192v1 [cs.LG])" — A fine-tuning method for better aligning generated images to the input text prompt when using diffusion models.
Paper: http://arxiv.org/abs/2302.12192
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The steps in our fine-tuning me…
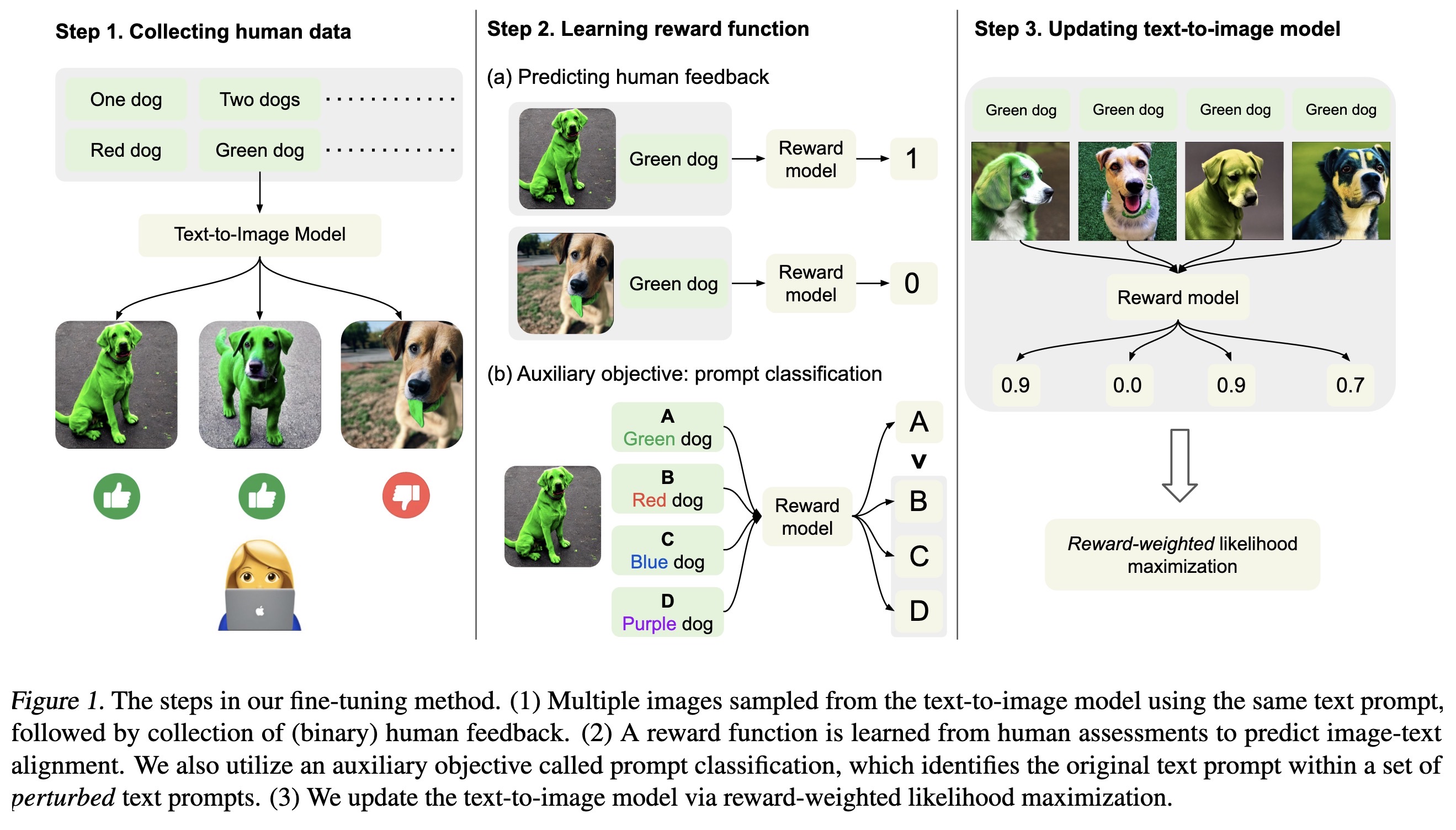
Paper: http://arxiv.org/abs/2302.12192
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The steps in our fine-tuning me…
0
4
1
Fahim Farook
f
"Evaluating the Efficacy of Skincare Product: A Realistic Short-Term Facial Pore Simulation. (arXiv:2302.11950v1 [cs.CV])" — Simulating the effects of skincare products on your skin (specifically the pores) to gauge efficacy of the product.
Paper: http://arxiv.org/abs/2302.11950
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative results of Facial P…
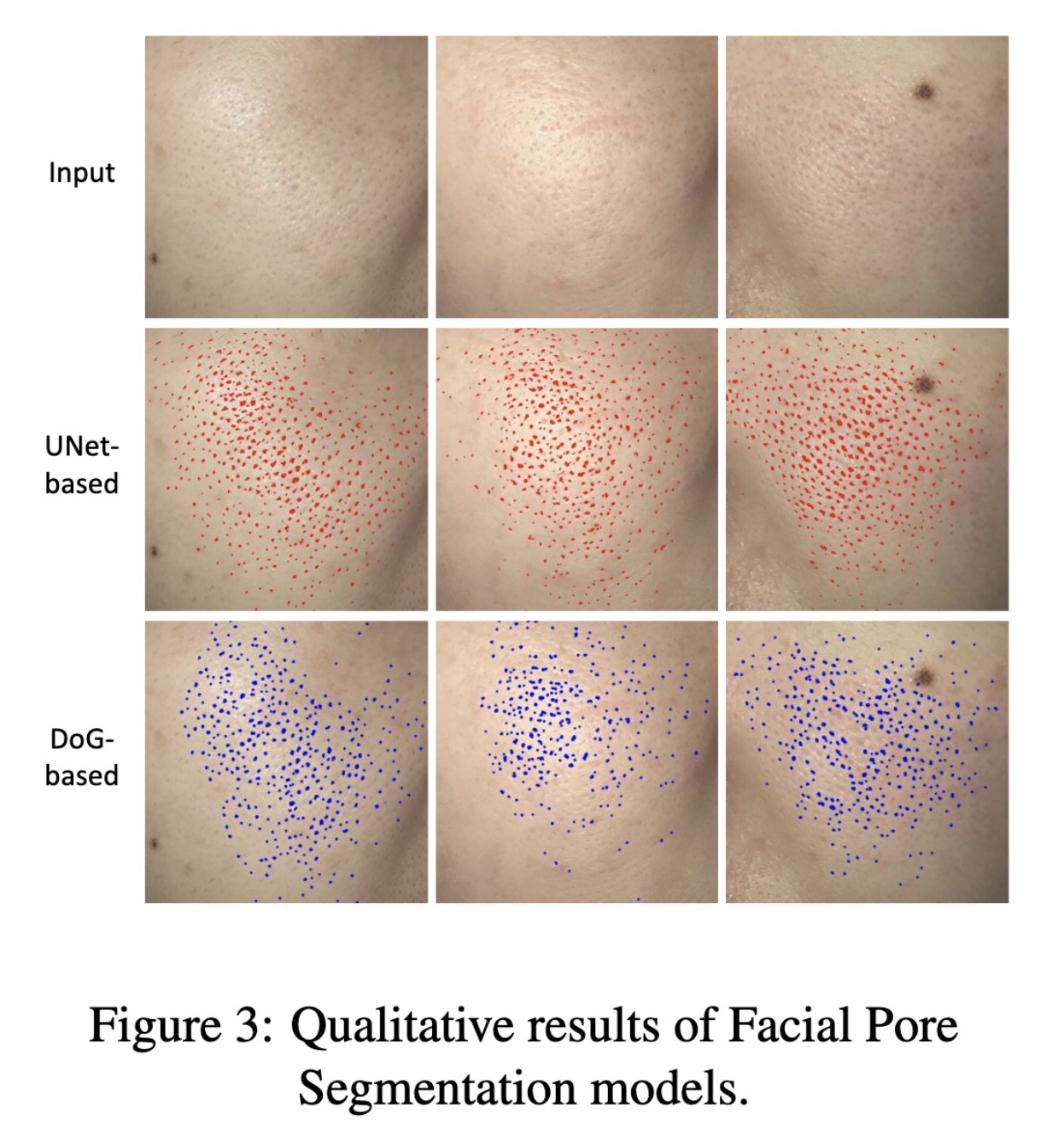
Paper: http://arxiv.org/abs/2302.11950
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative results of Facial P…
0
0
0
Fahim Farook
f
"Region-Aware Diffusion for Zero-shot Text-driven Image Editing. (arXiv:2302.11797v1 [cs.CV])" — A region-aware text-guided image editing method which aims to replace one entity with another.
What I always wonder with these approaches is whether you can replace a larger entity with a smaller one, or vice versa, (say a horse with a cat) in a way that looks realistic?
Paper: http://arxiv.org/abs/2302.11797
Code: https://github.com/haha-lisa/RDM-Region-Aware-Diffusion-Model
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The results of the proposed reg…

What I always wonder with these approaches is whether you can replace a larger entity with a smaller one, or vice versa, (say a horse with a cat) in a way that looks realistic?
Paper: http://arxiv.org/abs/2302.11797
Code: https://github.com/haha-lisa/RDM-Region-Aware-Diffusion-Model
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The results of the proposed reg…
0
0
0
Fahim Farook
f
"Controlled and Conditional Text to Image Generation with Diffusion Prior. (arXiv:2302.11710v1 [cs.CV])" — Using a Diffusion Prior to constrain the generation to a specific domain without altering the larger Diffusion Decoder in a memory and compute efficient way.
Paper: http://arxiv.org/abs/2302.11710
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion Prior can be trained …

Paper: http://arxiv.org/abs/2302.11710
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion Prior can be trained …
0
0
0
Fahim Farook
f
"Composer: Creative and Controllable Image Synthesis with Composable Conditions. (arXiv:2302.09778v2 [cs.CV] UPDATED)" — A way to flexibly control the output image from diffusion models to modify the layout or style of the final image.
Paper: http://arxiv.org/abs/2302.09778
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of compositional image …

Paper: http://arxiv.org/abs/2302.09778
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of compositional image …
0
0
0
Fahim Farook
f
"Entity-Level Text-Guided Image Manipulation. (arXiv:2302.11383v1 [cs.CV])" — A more accurate/efficient text-guided image editing/manipulation?
Paper: http://arxiv.org/abs/2302.11383
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison between our method a…

Paper: http://arxiv.org/abs/2302.11383
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison between our method a…
0
0
1
Fahim Farook
f
"Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities. (arXiv:2302.11154v1 [cs.CV])" — Creating a non-task/domain specific, general visual recognition model.
Paper: http://arxiv.org/abs/2302.11154
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustration of the proposed…

Paper: http://arxiv.org/abs/2302.11154
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustration of the proposed…
0
0
0