Fahim Farook
Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"A Comparative Analysis of CNN-Based Pretrained Models for the Detection and Prediction of Monkeypox. (arXiv:2302.10277v1 [cs.CV])" — Using Convolutional Neural Networks (CNN) to detect monkeypox since it's difficult to diagnose early due to its similarity to other diseases like chickenpox and measles.
Paper: http://arxiv.org/abs/2302.10277
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Chart showing confirmed monkeyp…
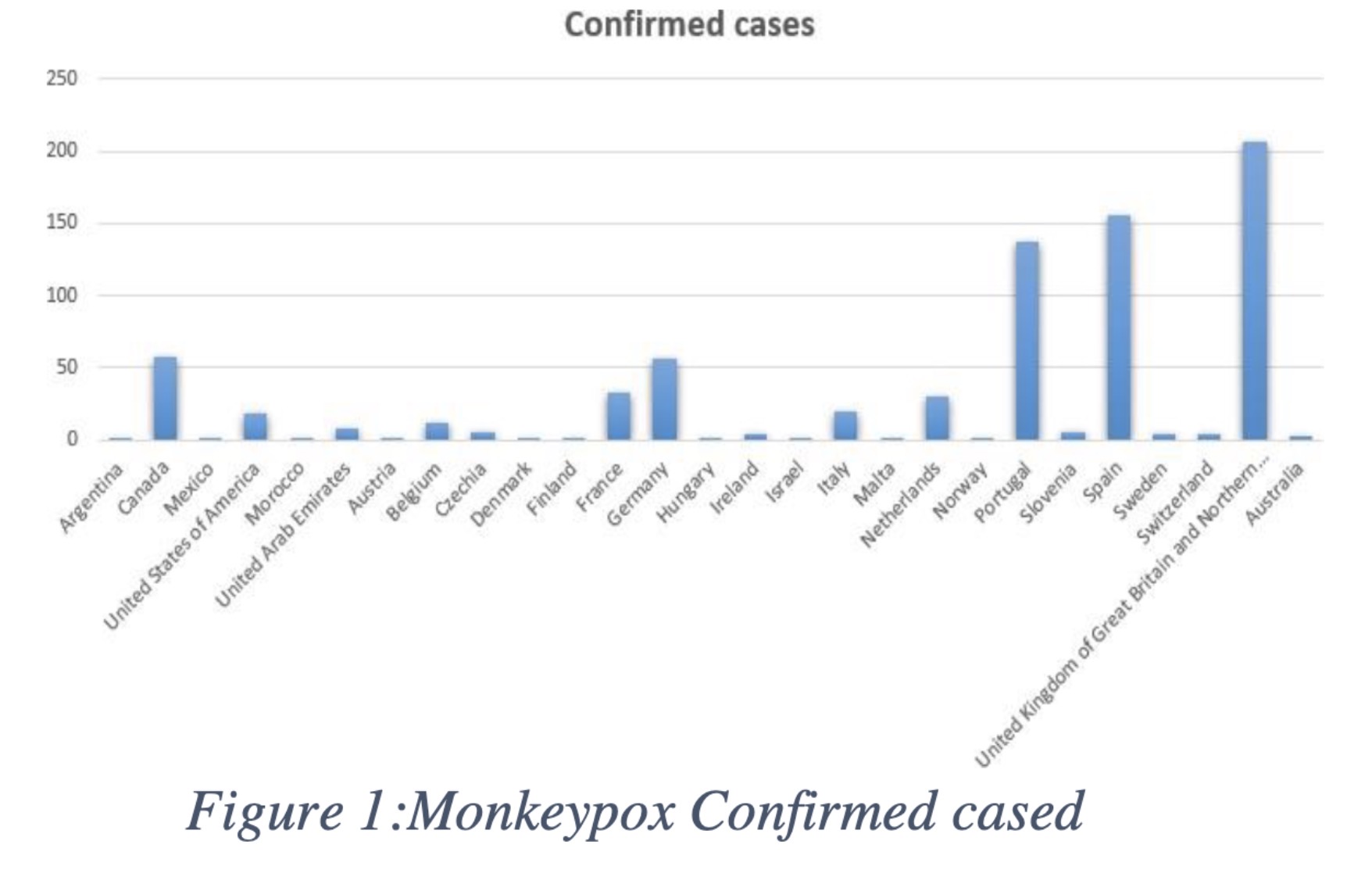
Paper: http://arxiv.org/abs/2302.10277
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Chart showing confirmed monkeyp…
 0
0
 0
0
 1
1
Fahim Farook
f
I've been trying out leonardo.ai with a bunch of new prompts since yesterday.
The following are the best results for: "Burning the cradle at both ends" ... and no "cradle" wasn't a typo, that was the prompt I wanted 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …




The following are the best results for: "Burning the cradle at both ends" ... and no "cradle" wasn't a typo, that was the prompt I wanted 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
0
1
4
Fahim Farook
f
"Vulnerability analysis of captcha using Deep learning. (arXiv:2302.09389v1 [cs.CR])" — Using a Convolutional Neural Network (CNN) model to predict text-based CAPTCHAs to examine the flaws inherent in the system and to create more resilient CAPTCHAs.
Paper: http://arxiv.org/abs/2302.09389
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of different alphanume…

Paper: http://arxiv.org/abs/2302.09389
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of different alphanume…
0
1
0
Fahim Farook
f
"Exploring the Representation Manifolds of Stable Diffusion Through the Lens of Intrinsic Dimension. (arXiv:2302.09301v1 [cs.CL])" — An investigation into the basic geometric properties induced by prompts in Stable Diffusion and how this impact depends on the layer being considered.
Paper: http://arxiv.org/abs/2302.09301
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The output of the model at the …

Paper: http://arxiv.org/abs/2302.09301
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The output of the model at the …
0
1
0
Fahim Farook
f
"Web Photo Source Identification based on Neural Enhanced Camera Fingerprint. (arXiv:2302.09228v1 [cs.CV])" — Using a neural network to identify sensor patterns in an effort to identify the source camera for images published on the web.
Paper: http://arxiv.org/abs/2302.09228
Code: https://github.com/PhotoNecf/PhotoNecf
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three main stages of source ide…
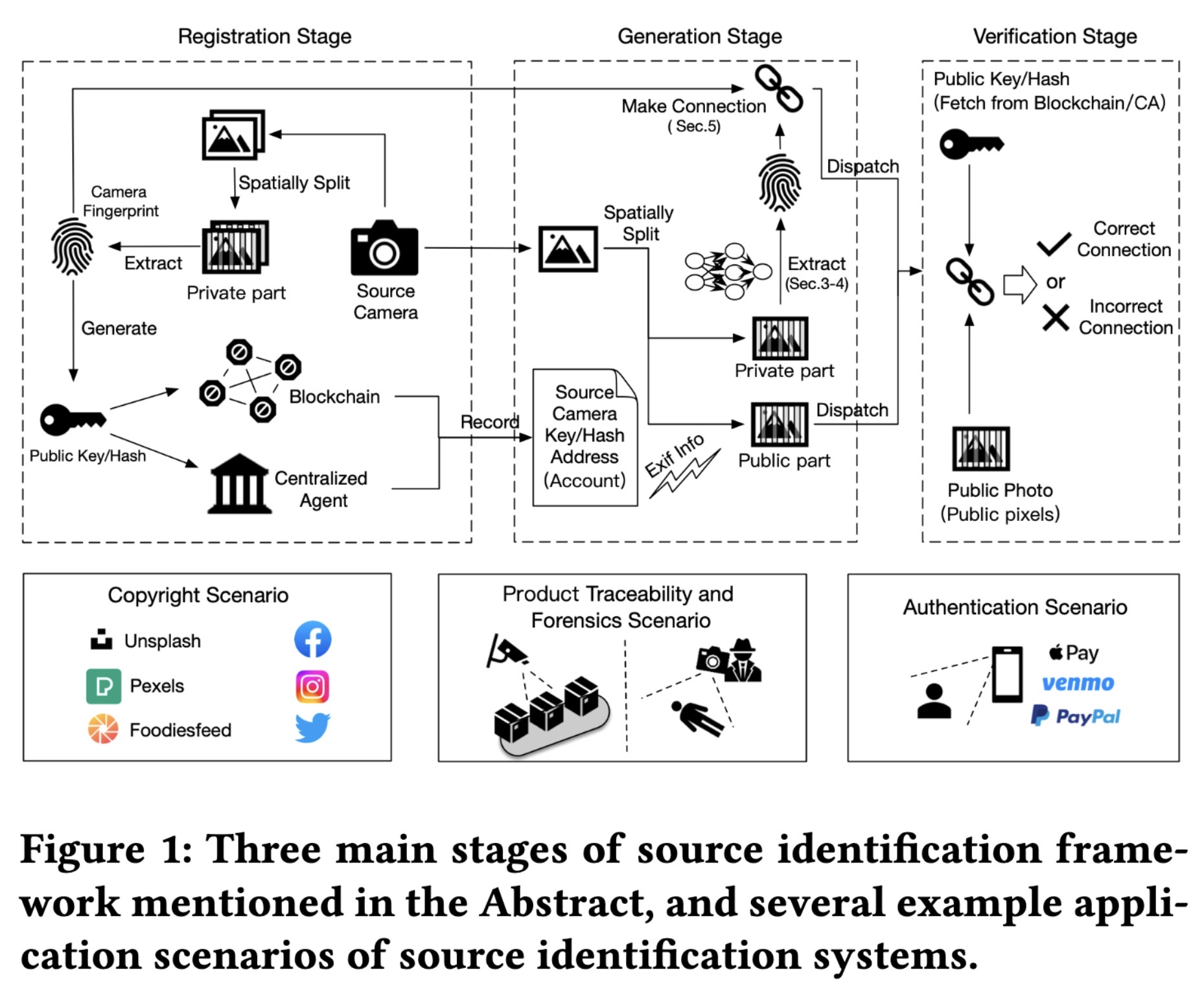
Paper: http://arxiv.org/abs/2302.09228
Code: https://github.com/PhotoNecf/PhotoNecf
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three main stages of source ide…
0
2
1
Fahim Farook
f
"A Pilot Evaluation of ChatGPT and DALL-E 2 on Decision Making and Spatial Reasoning. (arXiv:2302.09068v1 [cs.AI])" — An evaluation of ChatGPT and DALL-E2 to assess the spatial reasoning and decision making abilities of each model.
Paper: http://arxiv.org/abs/2302.09068
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
DALL-E output for the prompts: …

Paper: http://arxiv.org/abs/2302.09068
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
DALL-E output for the prompts: …
0
1
0
Fahim Farook
f
""Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction. (arXiv:2210.03735v2 [cs.HC] UPDATED)" — A study of how explainability can support human-AI interaction using a real-world AI applicaiton.
Paper: http://arxiv.org/abs/2210.03735
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Screenshots of Merlin, our stu…
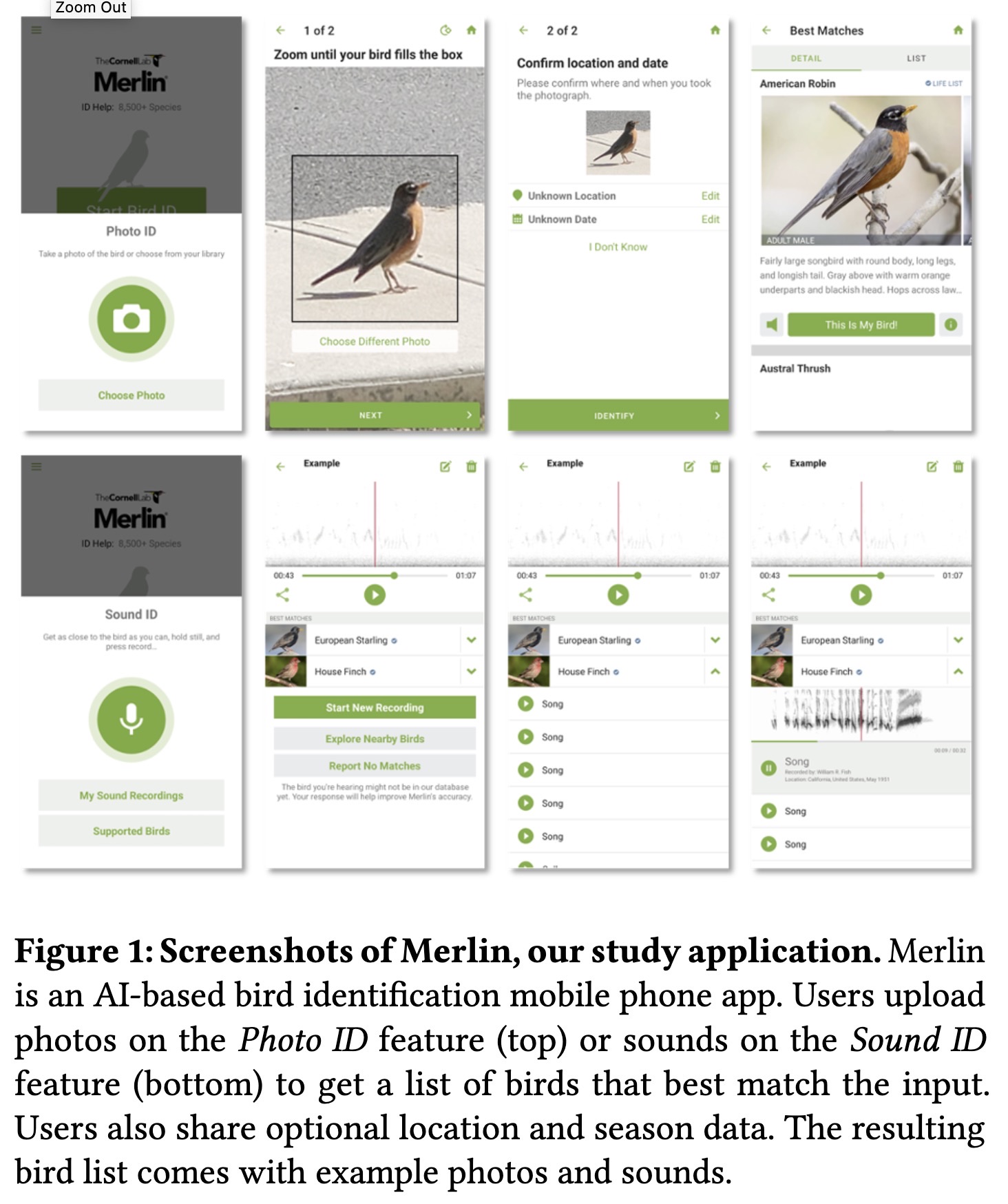
Paper: http://arxiv.org/abs/2210.03735
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Screenshots of Merlin, our stu…
0
5
4
Fahim Farook
f
"Which country is this picture from? New data and methods for DNN-based country recognition. (arXiv:2209.02429v2 [cs.CV] UPDATED)" — A framework to identify the country where an image was taken, which could be useful in debunking fake news and many other applications.
Paper: http://arxiv.org/abs/2209.02429
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three sample photos taken from …

Paper: http://arxiv.org/abs/2209.02429
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three sample photos taken from …
0
2
0
Fahim Farook
f
"Consistent Diffusion Models: Mitigating Sampling Drift by Learning to be Consistent. (arXiv:2302.09057v1 [cs.LG])" — A possible solution to fix the sampling iterations drifting away from the training distribution when generating images using diffusion models.
Paper: http://arxiv.org/abs/2302.09057
Code: https://github.com/giannisdaras/cdm
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Visual comparison of EDM model …

Paper: http://arxiv.org/abs/2302.09057
Code: https://github.com/giannisdaras/cdm
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Visual comparison of EDM model …
0
1
1
Fahim Farook
f
"LayoutDiffuse: Adapting Foundational Diffusion Models for Layout-to-Image Generation. (arXiv:2302.08908v1 [cs.CV])" — A method for generating images based on a semantic layout which describes the positioning of the various component elements in the final image.
Paper: http://arxiv.org/abs/2302.08908
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
LayoutDiffuse is able to genera…
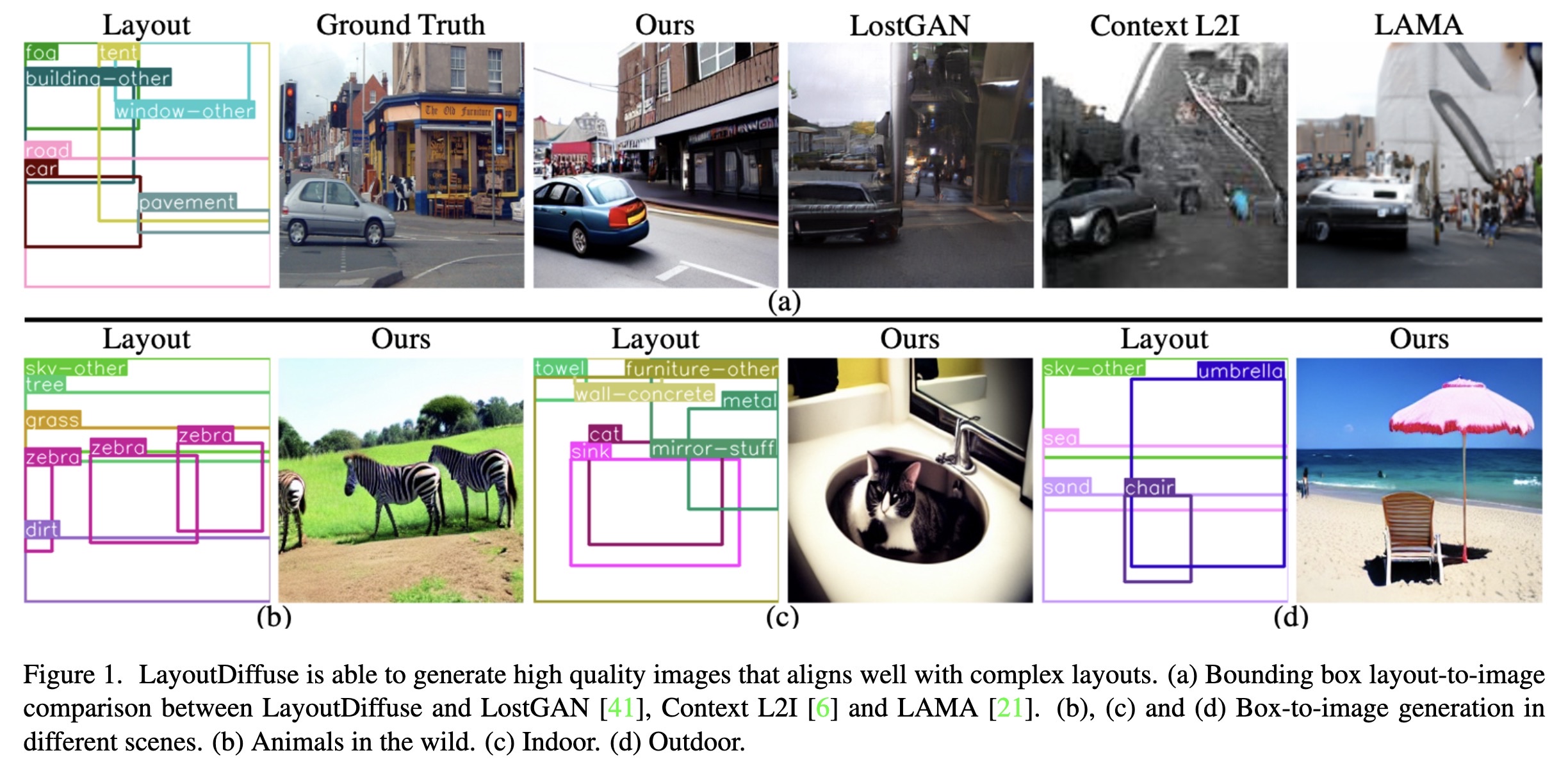
Paper: http://arxiv.org/abs/2302.08908
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
LayoutDiffuse is able to genera…
0
1
0
Fahim Farook
f
"Paint it Black: Generating paintings from text descriptions. (arXiv:2302.08808v1 [cs.CV])" — Explores generating paintings based on text input.
Paper: http://arxiv.org/abs/2302.08808
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of paintings generated…

Paper: http://arxiv.org/abs/2302.08808
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of paintings generated…
0
1
0
Fahim Farook
f
"Fine-grained Cross-modal Fusion based Refinement for Text-to-Image Synthesis. (arXiv:2302.08706v1 [cs.CV])" — Another text-to-image generation approach where, instead of generating the final image from a noisy image, you generate an initial low-resolution image based on the input text and then use a GAN (Generative Adversarial Network) during the second stage to generate the final output.
Paper: http://arxiv.org/abs/2302.08706
Code: https://github.com/haoranhfut/FF-GAN
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by Attn-GAN, …

Paper: http://arxiv.org/abs/2302.08706
Code: https://github.com/haoranhfut/FF-GAN
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Samples generated by Attn-GAN, …
0
1
0
Fahim Farook
f
Some years ago the news that a new “Civilization” game was in development would have excited me to no end 🙂 I used to love “SimCity” and “Civilization” to no end and I think back in the day, I played every “Sim” game that I could get my had on … “SimEarth”, “SimLife”, “SimFarm”, “SimTown”, “SimCopter” … I think I played all of them … or at least got them and tried them …
But, I didn’t play “Civilization VI” and the new game brings me no excitement. I think I just can’t get excited by that kind of gameplay any longer. Sure, compared to the original “Civilization”, the graphics have come a long way and it looks gorgeous, but I just don’t have the time/energy for the game play.
Now if they come up with a new version of “Civilization: Beyond Earth” with a good storyline (not just the building and exploration), I might be up for that 🙂
#Games #Civilization
A new Civilization game is in d…
But, I didn’t play “Civilization VI” and the new game brings me no excitement. I think I just can’t get excited by that kind of gameplay any longer. Sure, compared to the original “Civilization”, the graphics have come a long way and it looks gorgeous, but I just don’t have the time/energy for the game play.
Now if they come up with a new version of “Civilization: Beyond Earth” with a good storyline (not just the building and exploration), I might be up for that 🙂
#Games #Civilization
A new Civilization game is in d…
1
1
3
Fahim Farook
f
Yesterday's Pratchett novel title was: "The Shepherd's Crown"
And that's the last of the #DiscWorld titles 😞 Sure there are a few others left like "Nation", "Dodger", and the "Bromeliad" stuff (not to mention "Johnny") but those don't really count as much here. I was reluctant to do this one since it feels (almost) like reading the last DiscWorld novel (and I haven't read anything much since then ...)
But time moves on and I guess we must too?
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI
Prompt: “The Shepherd's Crown”.…
Prompt: “The Shepherd's Crown”.…
Prompt: “The Shepherd's Crown”.…
Prompt: “The Shepherd's Crown”.…




And that's the last of the #DiscWorld titles 😞 Sure there are a few others left like "Nation", "Dodger", and the "Bromeliad" stuff (not to mention "Johnny") but those don't really count as much here. I was reluctant to do this one since it feels (almost) like reading the last DiscWorld novel (and I haven't read anything much since then ...)
But time moves on and I guess we must too?
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI
Prompt: “The Shepherd's Crown”.…
Prompt: “The Shepherd's Crown”.…
Prompt: “The Shepherd's Crown”.…
Prompt: “The Shepherd's Crown”.…
1
2
7
Fahim Farook
f
"Discrete Contrastive Diffusion for Cross-Modal Music and Image Generation. (arXiv:2206.07771v2 [cs.CV] UPDATED)" — Synthesis of multiple types of content such as dance-to-music or text-to-image using a new diffusion mechanism, at fewer steps.
Paper: http://arxiv.org/abs/2206.07771
Code: https://github.com/l-yezhu/cdcd
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of the input (left col…

Paper: http://arxiv.org/abs/2206.07771
Code: https://github.com/l-yezhu/cdcd
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of the input (left col…
0
1
0
Fahim Farook
f
"Write and Paint: Generative Vision-Language Models are Unified Modal Learners. (arXiv:2206.07699v2 [cs.CV] UPDATED)" — A unified model based on training a model to write and paint concurrently.
Paper: http://arxiv.org/abs/2206.07699
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the overall arc…
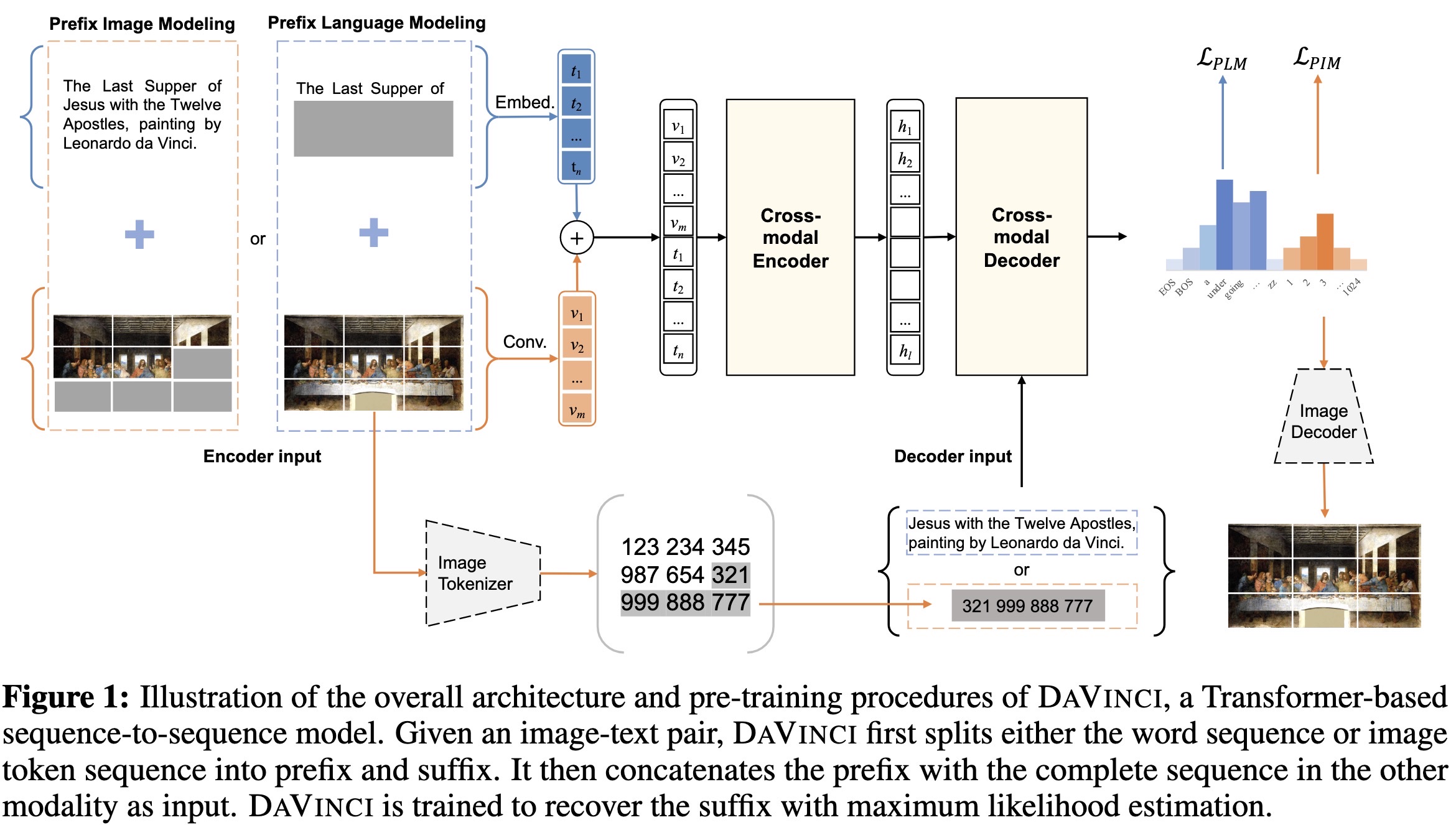
Paper: http://arxiv.org/abs/2206.07699
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the overall arc…
0
1
0
Fahim Farook
f
"Towards Reliable Image Outpainting: Learning Structure-Aware Multimodal Fusion with Depth Guidance. (arXiv:2204.05543v2 [cs.CV] UPDATED)" — Reliable outpainting using depth-guidance.
Paper: http://arxiv.org/abs/2204.05543
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A comparison of image outpainti…
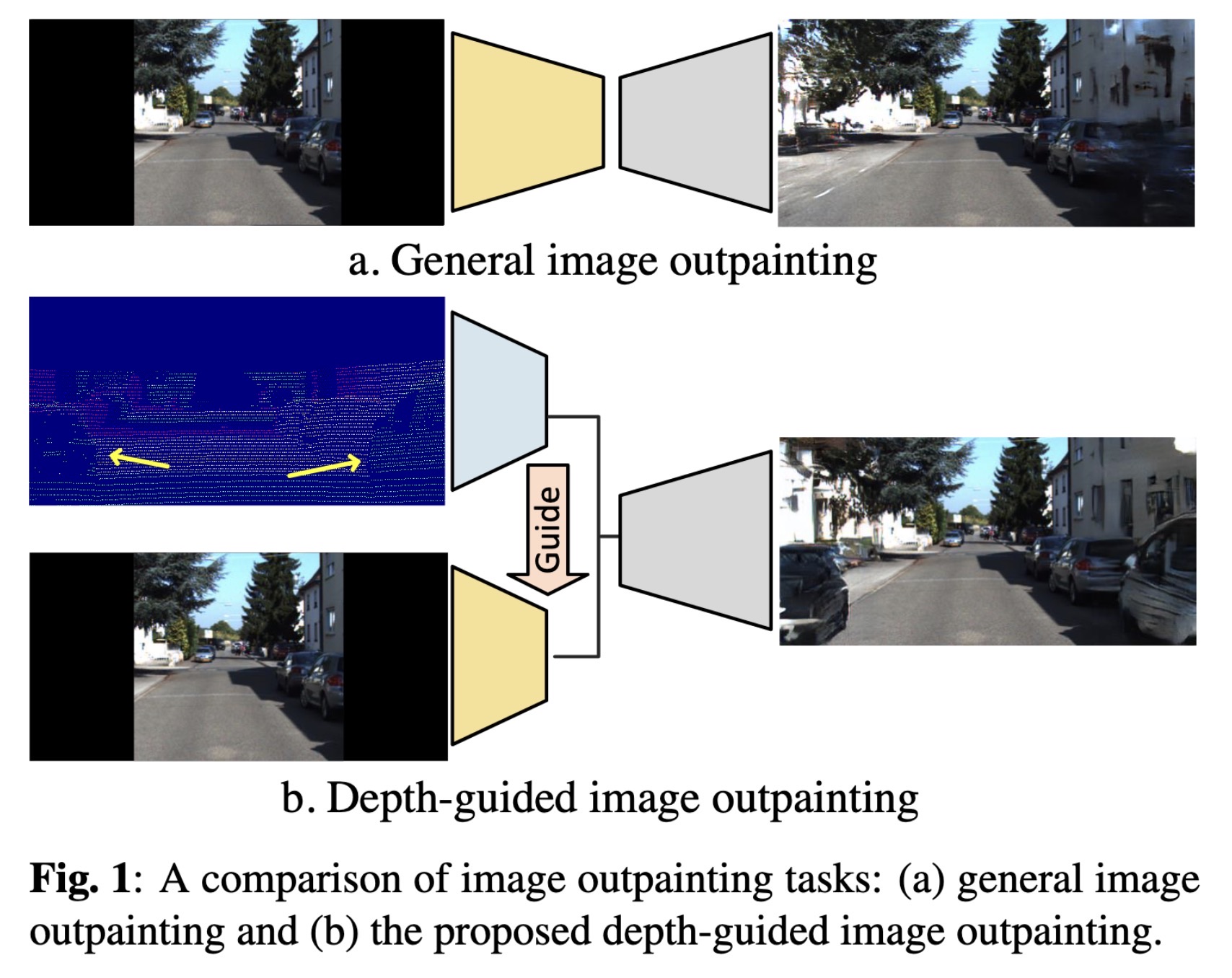
Paper: http://arxiv.org/abs/2204.05543
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A comparison of image outpainti…
0
1
0
Fahim Farook
f
"Text-driven Visual Synthesis with Latent Diffusion Prior. (arXiv:2302.08510v1 [cs.CV])" — Using diffusion models as the generic driver for diverse image generation tasks such as text-to3D, image editing, and StyleGAN adaptation.
Paper: http://arxiv.org/abs/2302.08510
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Applications of the proposed la…

Paper: http://arxiv.org/abs/2302.08510
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Applications of the proposed la…
0
2
0
Fahim Farook
f
"3D-aware Conditional Image Synthesis. (arXiv:2302.08509v1 [cs.CV])" — Using a 2 input such as a segmentation or edge map to generate photo-realistic images from different perspectives/viewpoints.
Paper: http://arxiv.org/abs/2302.08509
Code: https://github.com/dunbar12138/pix2pix3D
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given a 2D label map as input, …

Paper: http://arxiv.org/abs/2302.08509
Code: https://github.com/dunbar12138/pix2pix3D
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given a 2D label map as input, …
0
2
1
Fahim Farook
f
"T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models. (arXiv:2302.08453v1 [cs.CV])" — Controlling text-to-image diffusion models in a more granular fashion by using special adapters to provide extra guidance.
Paper: http://arxiv.org/abs/2302.08453
Code: https://github.com/TencentARC/T2I-Adapter
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We propose T2I-Adapter, a simpl…

Paper: http://arxiv.org/abs/2302.08453
Code: https://github.com/TencentARC/T2I-Adapter
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We propose T2I-Adapter, a simpl…
0
1
0