Fahim Farook
Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation. (arXiv:2302.08113v1 [cs.CV])" — Controlling diffusion-based image generation so that you can specify image components, component placement etc. without any further fine-tuning.
Paper: http://arxiv.org/abs/2302.08113
Code: https://github.com/omerbt/MultiDiffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
MultiDiffusion enables flexible…

Paper: http://arxiv.org/abs/2302.08113
Code: https://github.com/omerbt/MultiDiffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
MultiDiffusion enables flexible…
 0
0
 1
1
 0
0
Fahim Farook
f
"\`A-la-carte Prompt Tuning (APT): Combining Distinct Data Via Composable Prompting. (arXiv:2302.07994v1 [cs.LG])" — Having multiple subsets of data trained on specific prompts and being able to compose the final model based on the prompts you select.
Paper: http://arxiv.org/abs/2302.07994
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A-la-carte Learning and APT. Gi…
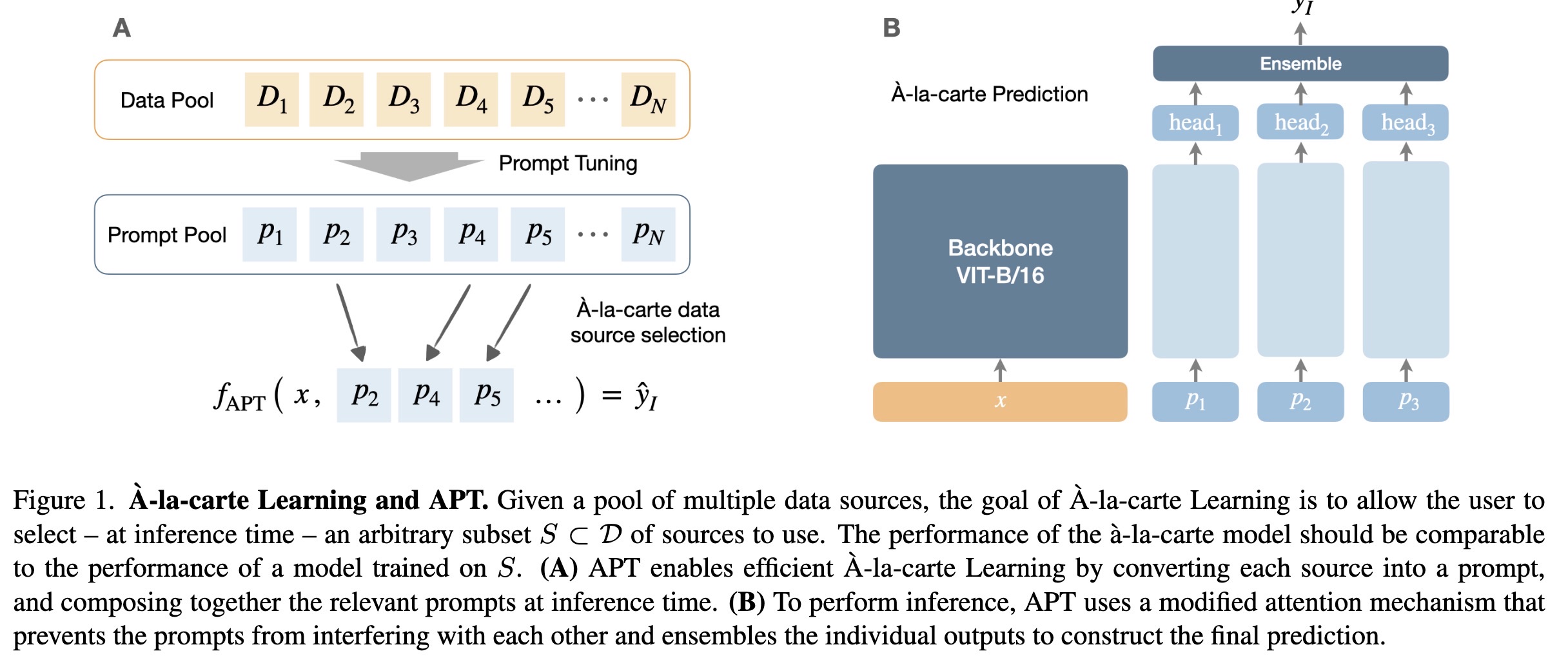
Paper: http://arxiv.org/abs/2302.07994
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A-la-carte Learning and APT. Gi…
0
2
0
Fahim Farook
f
"PRedItOR: Text Guided Image Editing with Diffusion Prior. (arXiv:2302.07979v1 [cs.CV])" — Structure preserving, text guided image editing using diffusion models without needing a base prompt, fine-tuning of models etc.
Paper: http://arxiv.org/abs/2302.07979
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of text guided image e…

Paper: http://arxiv.org/abs/2302.07979
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of text guided image e…
0
2
1
Fahim Farook
f
Yesterday's Pratchett novel title prompt was: "Raising Steam".
Here's the thing about the prompt — I generated images on macOS initially and I was happy with the images I was getting since I was getting strange stuff. Nothing really to do with the prompt possibly, but all sorts of weird and wonderful landscapes 🙂
Then I switched to Windows for generation and suddenly all I'd get were trains or some sort of steam engine. Not a lot of variety ... No matter how many models I tried 😛
I've selected a mixed set from both sides for fair representation but I feel as if this needs more exploration ...
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “Raising Steam”. A dark…
Prompt: “Raising Steam”. Some s…
Prompt: “Raising Steam”. A stra…
Prompt: “Raising Steam”. A dark…




Here's the thing about the prompt — I generated images on macOS initially and I was happy with the images I was getting since I was getting strange stuff. Nothing really to do with the prompt possibly, but all sorts of weird and wonderful landscapes 🙂
Then I switched to Windows for generation and suddenly all I'd get were trains or some sort of steam engine. Not a lot of variety ... No matter how many models I tried 😛
I've selected a mixed set from both sides for fair representation but I feel as if this needs more exploration ...
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “Raising Steam”. A dark…
Prompt: “Raising Steam”. Some s…
Prompt: “Raising Steam”. A stra…
Prompt: “Raising Steam”. A dark…
0
2
7
Fahim Farook
f
"Forward Pass: On the Security Implications of Email Forwarding Mechanism and Policy" — How email forwarding can create security vulnerabilities and and allow spoofing.
Paper: https://arxiv.org/abs/2302.07287
#AI #NewPaper #Security
Example message with a FROM hea…
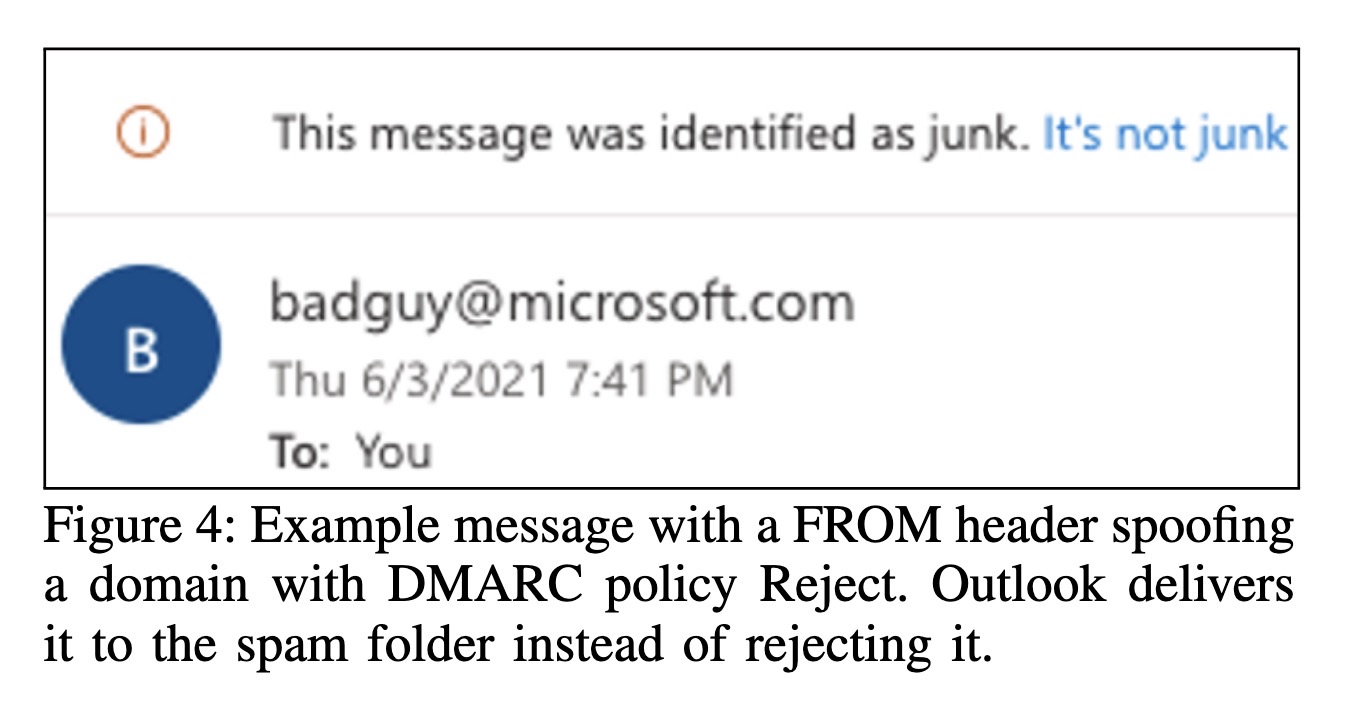
Paper: https://arxiv.org/abs/2302.07287
#AI #NewPaper #Security
Example message with a FROM hea…
0
0
0
Fahim Farook
f
"AI Chat Assistants can Improve Conversations about Divisive Topics" — A study looking at how Large Language Models can improve conversations on divisive topics by making the participants feel understood.
Paper: https://arxiv.org/abs/2302.07268
#AI #NewPaper #DeepLearning #MachineLearning #Language #HumanComputerInteraction
Treated Conversation Flow: Resp…
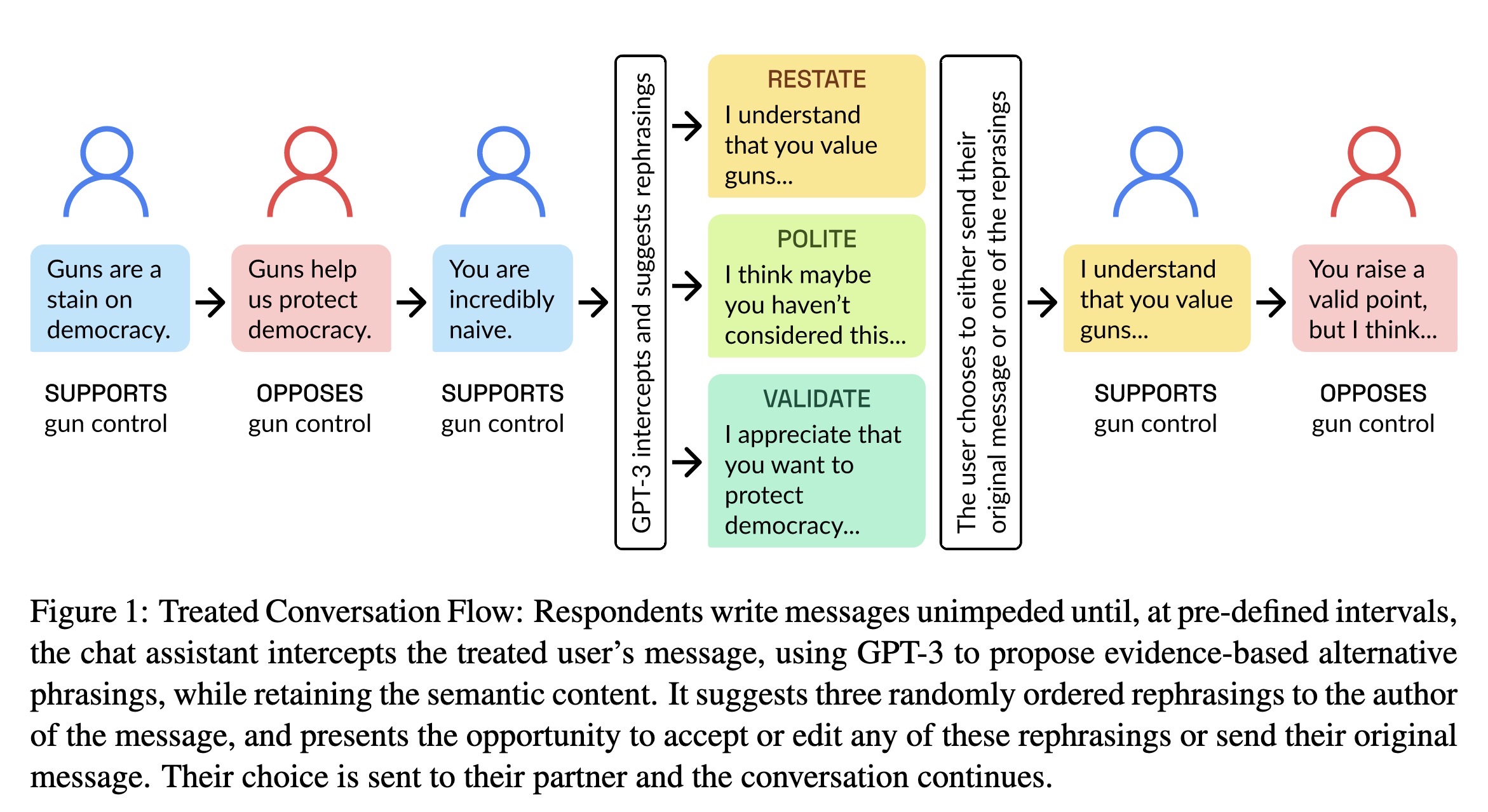
Paper: https://arxiv.org/abs/2302.07268
#AI #NewPaper #DeepLearning #MachineLearning #Language #HumanComputerInteraction
Treated Conversation Flow: Resp…
0
1
0
Fahim Farook
f
"CiteSee: Augmenting Citations in Scientific Papers with Persistent and Personalized Historical Context" — A tool that uses a reader’s publishing, reading, and saving history to provide personalised context to citations in papers that they’re reading.
Paper: https://arxiv.org/abs/2302.07302
#NewPaper #HumanComputerInteraction
CiteSee augments inline citatio…
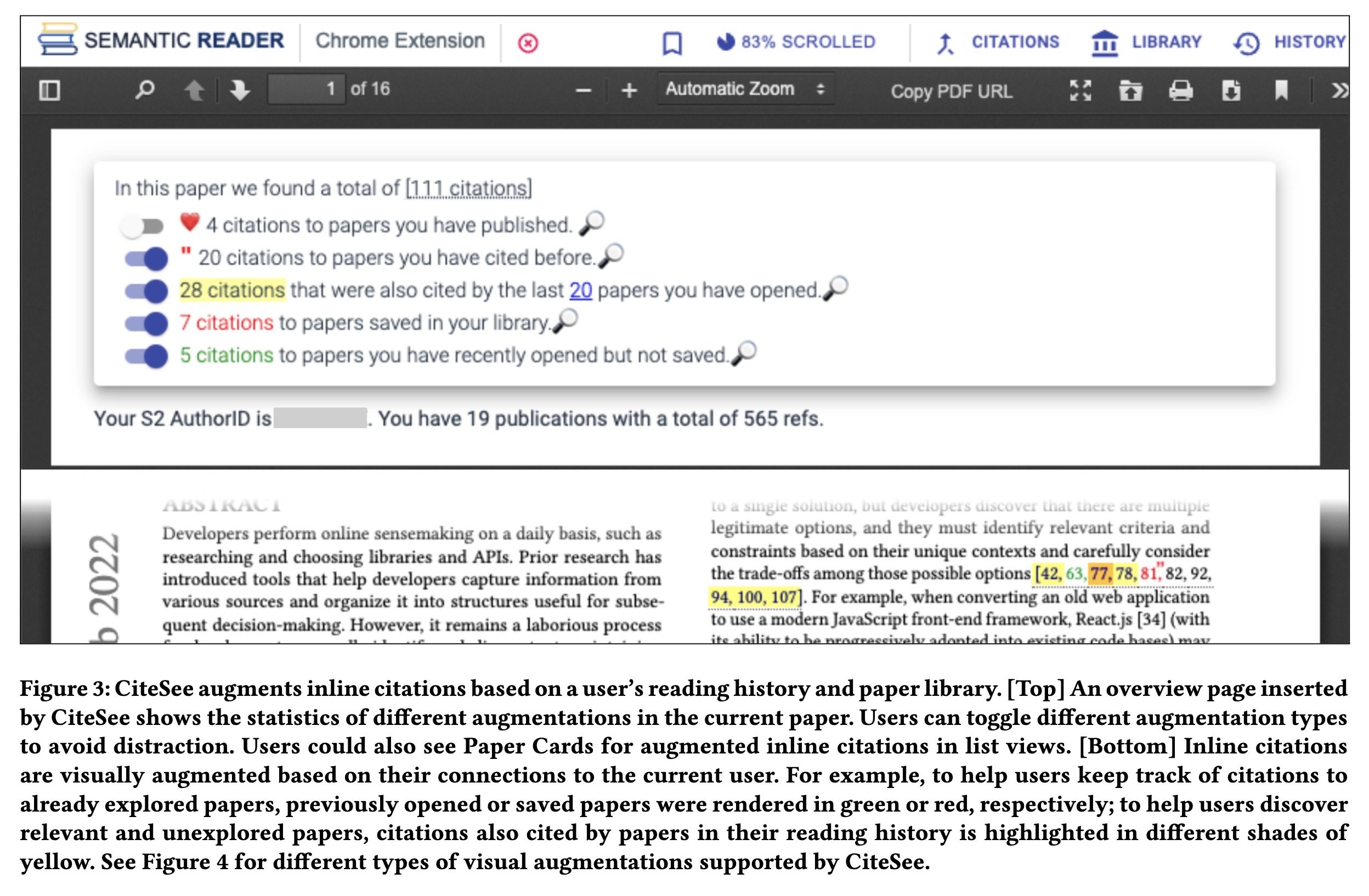
Paper: https://arxiv.org/abs/2302.07302
#NewPaper #HumanComputerInteraction
CiteSee augments inline citatio…
0
2
1
Fahim Farook
f
"Stitchable Neural Networks. (arXiv:2302.06586v2 [cs.LG] UPDATED)" — A way to combine different pretrained models to combine models of varying complexity and performance.
Paper: http://arxiv.org/abs/2302.06586
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Compared with previous scalable…
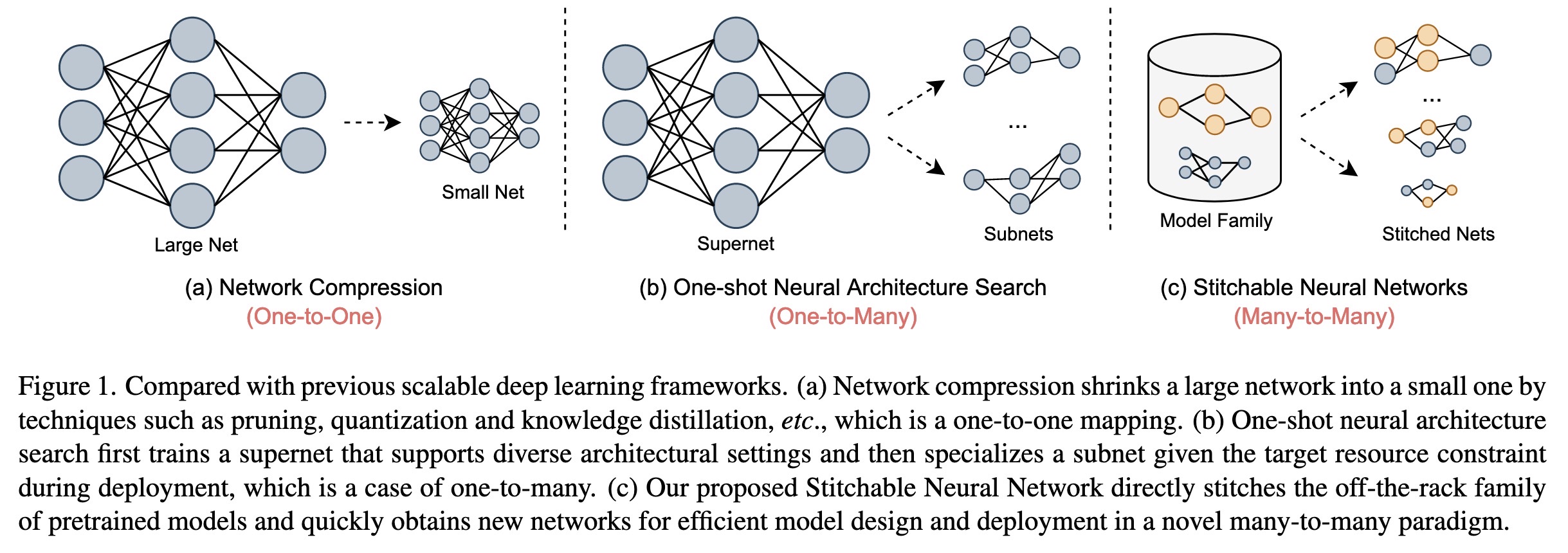
Paper: http://arxiv.org/abs/2302.06586
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Compared with previous scalable…
0
1
0
Fahim Farook
f
"Learning When to Say "I Don't Know". (arXiv:2209.04944v2 [cs.CV] UPDATED)" — A method to teach learning systems when they don't know something, or at least to identify areas of uncertainty. Perhaps this should be tried with ChatGPT and Bing to mitigate all the gaslighting? 😛
Paper: http://arxiv.org/abs/2209.04944
Code: https://github.com/osu-cvl/learning-idk
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
t-SNE plots of logits from a we…

Paper: http://arxiv.org/abs/2209.04944
Code: https://github.com/osu-cvl/learning-idk
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
t-SNE plots of logits from a we…
0
4
4
Fahim Farook
f
"SoK: Anti-Facial Recognition Technology. (arXiv:2112.04558v2 [cs.CR] UPDATED)" — An analysis of the currently available Anti-Facial Recognition (AFR) research and the pros and cons of the different approaches.
Paper: http://arxiv.org/abs/2112.04558
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The workflow of how facial reco…
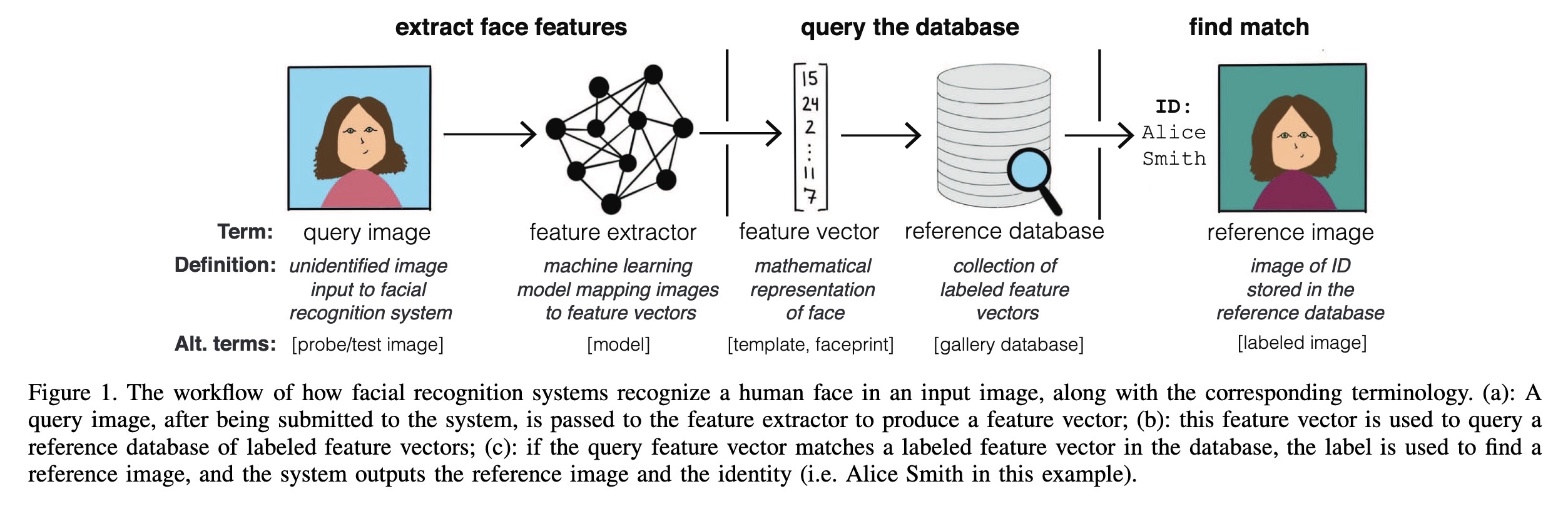
Paper: http://arxiv.org/abs/2112.04558
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The workflow of how facial reco…
0
0
0
Fahim Farook
f
"Team Triple-Check at Factify 2: Parameter-Efficient Large Foundation Models with Feature Representations for Multi-Modal Fact Verification. (arXiv:2302.07740v1 [cs.CL])" — Verifying facts across different modes (text and images) and types (claim and document).
Paper: http://arxiv.org/abs/2302.07740
Code: https://github.com/wwweiwei/Pre-CoFactv2-AAAI-2023
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An example of each category in …

Paper: http://arxiv.org/abs/2302.07740
Code: https://github.com/wwweiwei/Pre-CoFactv2-AAAI-2023
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An example of each category in …
0
1
0
Fahim Farook
f
"Video Probabilistic Diffusion Models in Projected Latent Space. (arXiv:2302.07685v1 [cs.CV])" — Generating high-resolution and coherent video using diffusion models.
Paper: http://arxiv.org/abs/2302.07685
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
256×256 resolution, 128 frame v…
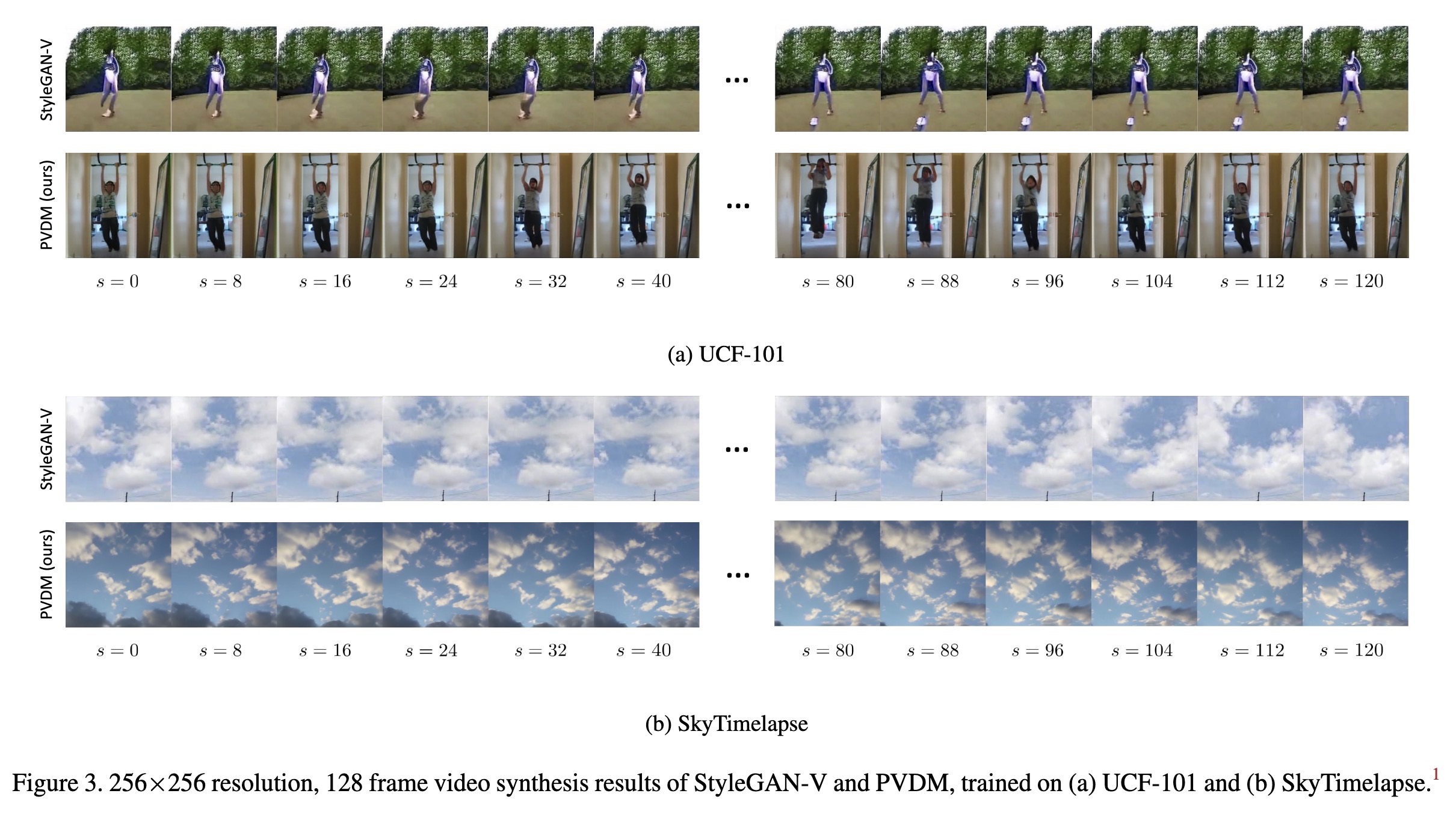
Paper: http://arxiv.org/abs/2302.07685
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
256×256 resolution, 128 frame v…
0
1
0
Fahim Farook
f
Yesterday's Pratchett novel title prompt was: "Snuff"
I didn't really expect much from that one since there isn't a lot to work with there. But I still got some interesting images 🙂
These are from multiple models and so the styles are a little different across images. But still, I thought the end results were interesting ...
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “Snuff”. Colourful pict…
Prompt: “Snuff”. A huge creatur…
Prompt: “Snuff”. A colourful im…
Prompt: “Snuff”. A colourful bu…




I didn't really expect much from that one since there isn't a lot to work with there. But I still got some interesting images 🙂
These are from multiple models and so the styles are a little different across images. But still, I thought the end results were interesting ...
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “Snuff”. Colourful pict…
Prompt: “Snuff”. A huge creatur…
Prompt: “Snuff”. A colourful im…
Prompt: “Snuff”. A colourful bu…
0
0
2
Fahim Farook
f
"DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model. (arXiv:2302.06908v1 [cs.CV])" — Today seems to be the day for papers on turning sketches into realistic colour images using diffusion models 😛 This is another approach ...
Paper: http://arxiv.org/abs/2302.06908
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A Sketch-Guided Lantent Diffusi…

Paper: http://arxiv.org/abs/2302.06908
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A Sketch-Guided Lantent Diffusi…
0
1
1
Fahim Farook
f
"Text-Guided Scene Sketch-to-Photo Synthesis. (arXiv:2302.06883v1 [cs.CV])" — Creating a whole scene color image based on a sketch using generative models such as Stable Diffusion.
Paper: http://arxiv.org/abs/2302.06883
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of training and sampli…
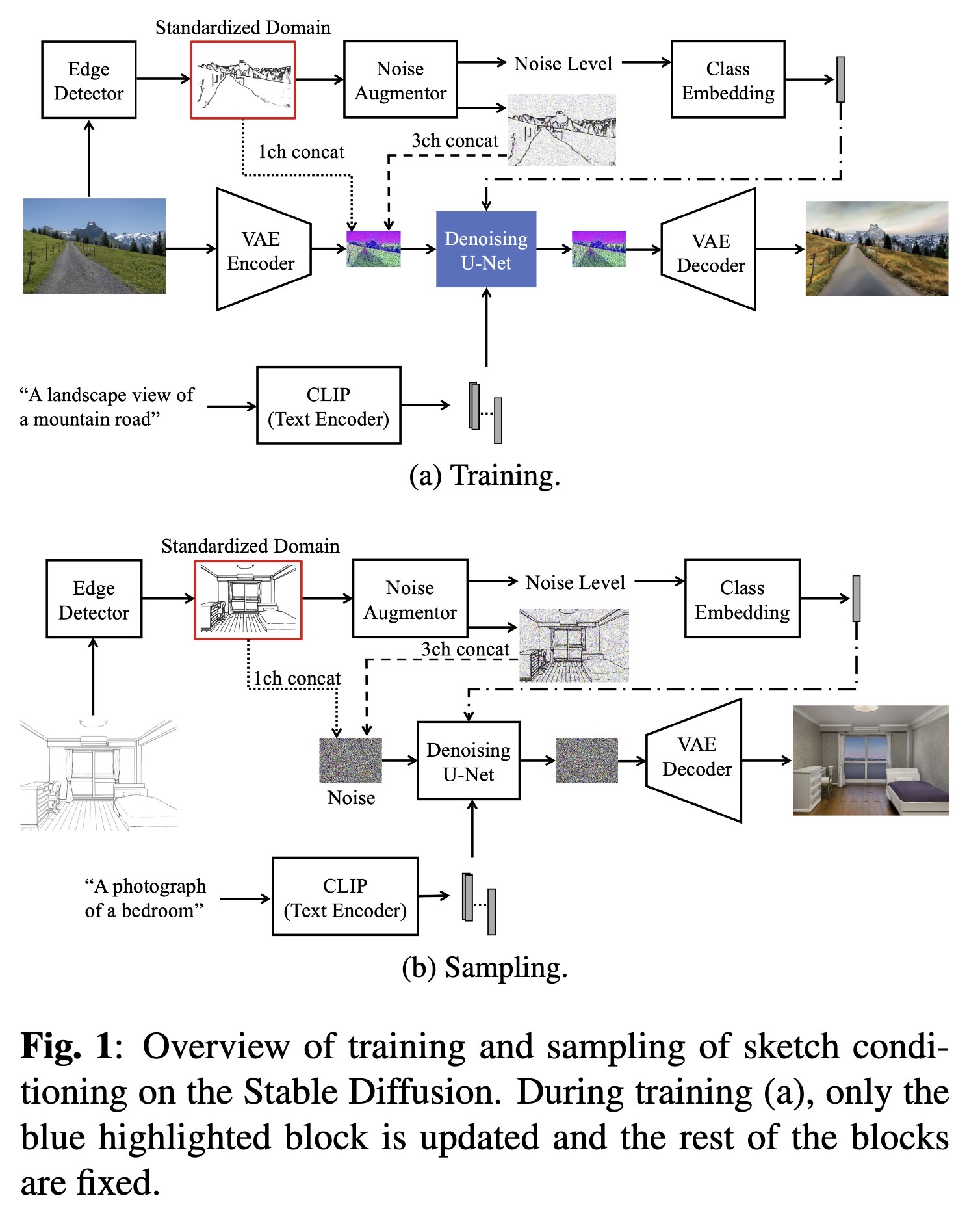
Paper: http://arxiv.org/abs/2302.06883
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of training and sampli…
0
1
0
Fahim Farook
f
"Make Your Brief Stroke Real and Stereoscopic: 3D-Aware Simplified Sketch to Portrait Generation. (arXiv:2302.06857v1 [cs.CV])" — Creating photorealistic images of people based on sketches using 3D generative models.
Paper: http://arxiv.org/abs/2302.06857
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The visualization of our Stereo…

Paper: http://arxiv.org/abs/2302.06857
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The visualization of our Stereo…
0
1
0
Fahim Farook
f
"DiffFashion: Reference-based Fashion Design with Structure-aware Transfer by Diffusion Models. (arXiv:2302.06826v1 [cs.CV])" — Transfer the input image appearance onto images of items of clothing while not altering the structure of the clothing item.
Paper: http://arxiv.org/abs/2302.06826
Code: https://github.com/Rem105-210/DiffFashion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two examples of a reference-bas…

Paper: http://arxiv.org/abs/2302.06826
Code: https://github.com/Rem105-210/DiffFashion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two examples of a reference-bas…
0
1
0
Fahim Farook
f
"Multiple Appropriate Facial Reaction Generation in Dyadic Interaction Settings: What, Why and How?. (arXiv:2302.06514v2 [cs.CV] UPDATED)" — An attempt to generate appropriate behavioral responses to received stimulus and to evaluate the appropriateness of the generated responses.
Paper: http://arxiv.org/abs/2302.06514
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multiple appropriate reaction g…

Paper: http://arxiv.org/abs/2302.06514
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multiple appropriate reaction g…
0
1
0
Fahim Farook
f
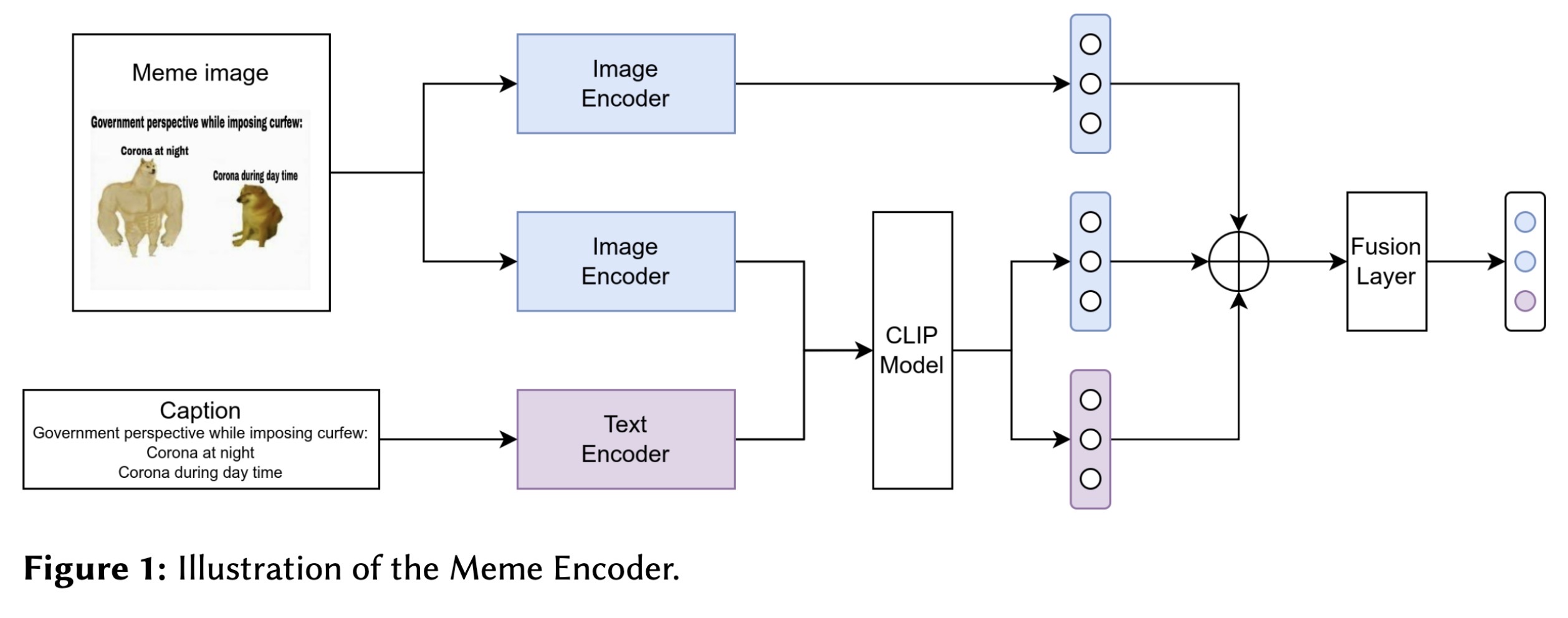
"NYCU-TWO at Memotion 3: Good Foundation, Good Teacher, then you have Good Meme Analysis. (arXiv:2302.06078v2 [cs.CL] UPDATED)" — Classifying the emotions and intensity expressed in memes using machine learning.
Paper: http://arxiv.org/abs/2302.06078
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of the Meme Encoder
Paper: http://arxiv.org/abs/2302.06078
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of the Meme Encoder
0
1
0
Fahim Farook
f
"Vector Quantized Diffusion Model with CodeUnet for Text-to-Sign Pose Sequences Generation. (arXiv:2208.09141v2 [cs.CV] UPDATED)" — Using diffusion models to generate sign language pose sequences based on spoken language.
Paper: http://arxiv.org/abs/2208.09141
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The forward diffusion process a…

Paper: http://arxiv.org/abs/2208.09141
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The forward diffusion process a…
0
1
0