Fahim Farook
Posts
1616Following
138Followers
881I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
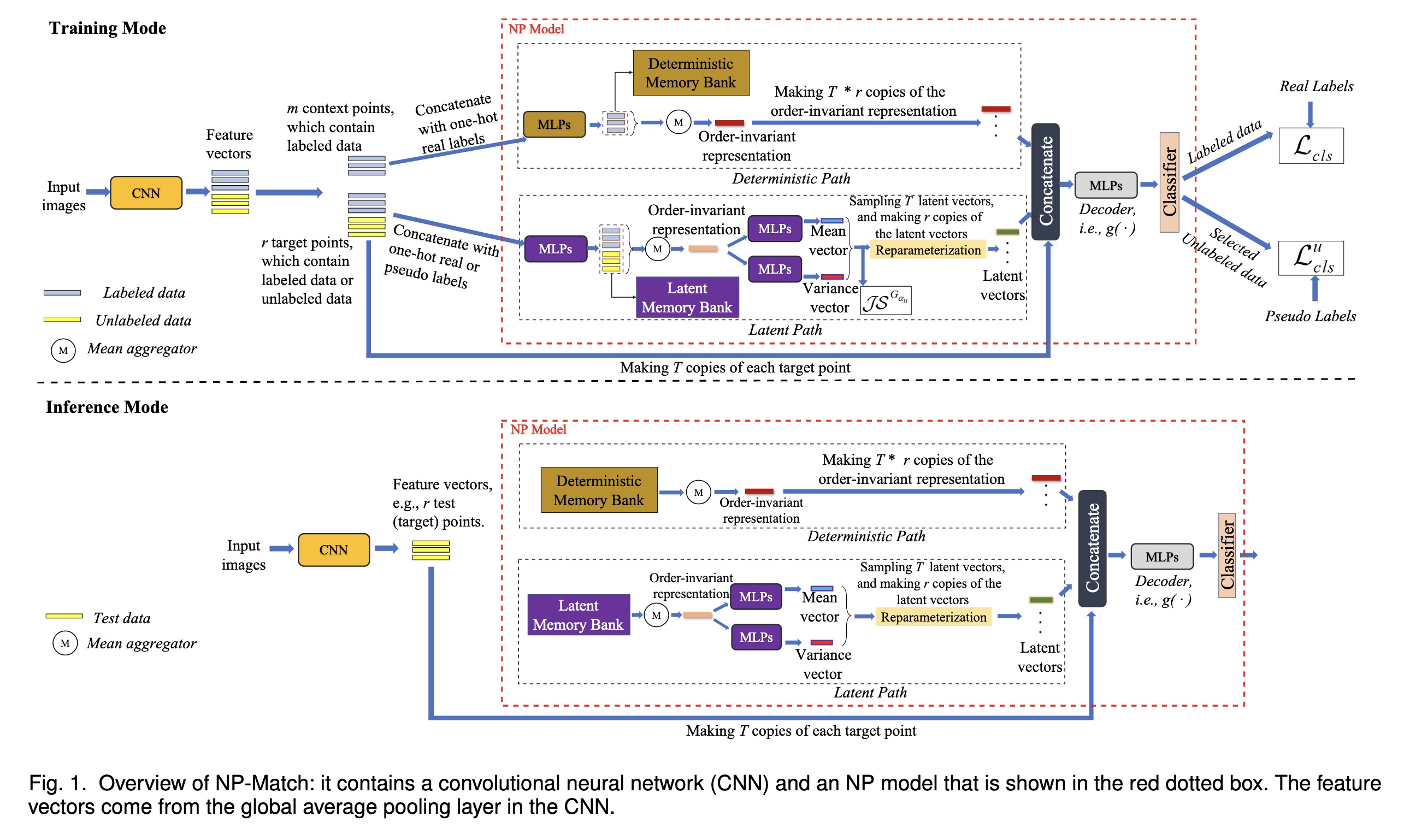
"NP-Match: Towards a New Probabilistic Model for Semi-Supervised Learning. (arXiv:2301.13569v1 [cs.CV])" — Adapting neural processes (NPs) for semi-supervised image classification tasks to arrive at a solution with much less computational overhead, which can save time at both the training and the testing phases.
Paper: http://arxiv.org/abs/2301.13569
Code: https://github.com/jianf-wang/np-match
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of NP-Match: it contai…
Paper: http://arxiv.org/abs/2301.13569
Code: https://github.com/jianf-wang/np-match
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of NP-Match: it contai…
 0
0
 1
1
 1
1
Fahim Farook
f
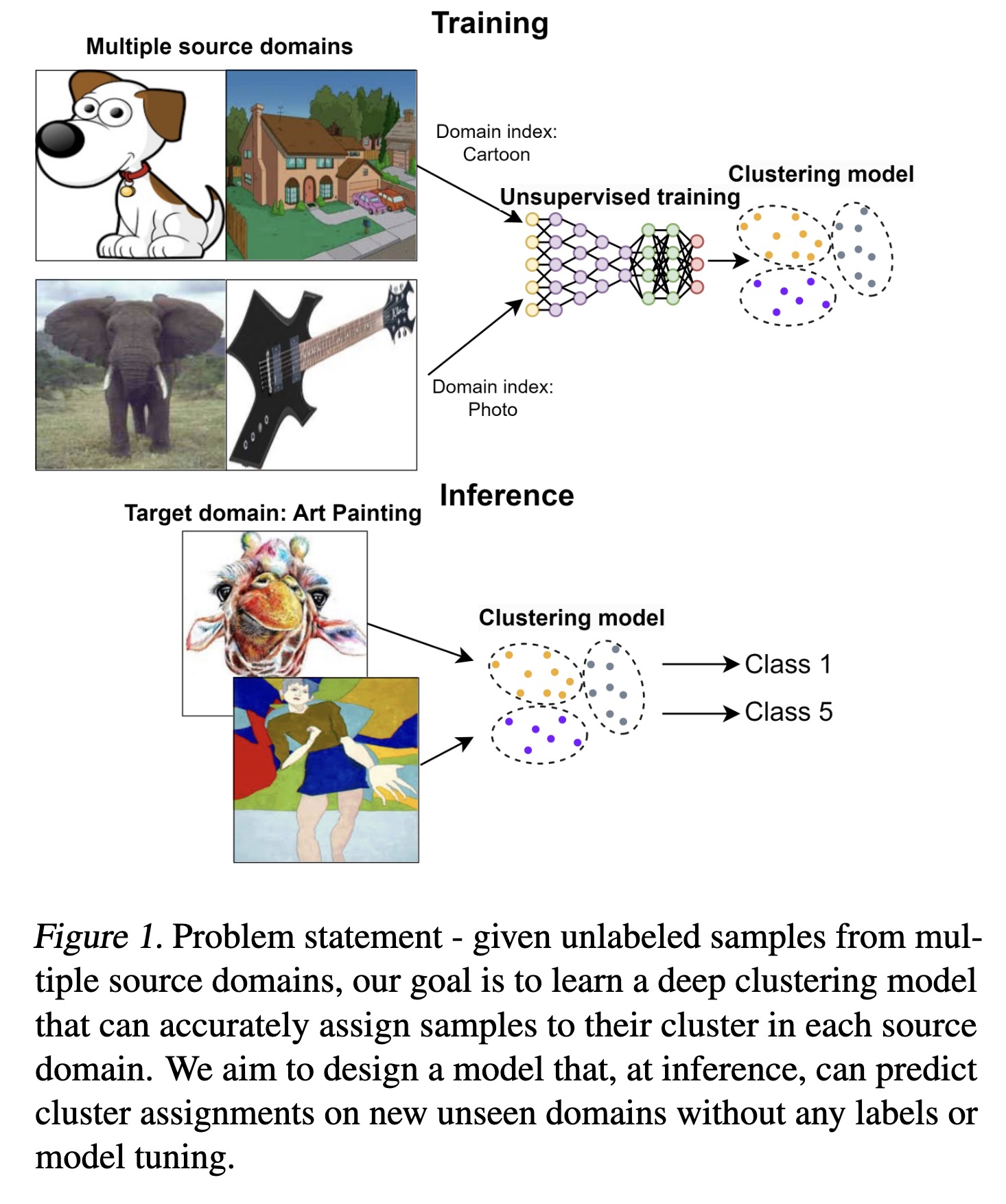
"Domain-Generalizable Multiple-Domain Clustering. (arXiv:2301.13530v1 [cs.LG])" — Given unlabeled samples from multiple source domains, an attempt to learn a shared classifier that assigns the examples to various clusters by using the classifier for predicting cluster assignments in a previously unseen domain.
Paper: http://arxiv.org/abs/2301.13530
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Problem statement - given unlab…
Paper: http://arxiv.org/abs/2301.13530
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Problem statement - given unlab…
0
1
0
Fahim Farook
f
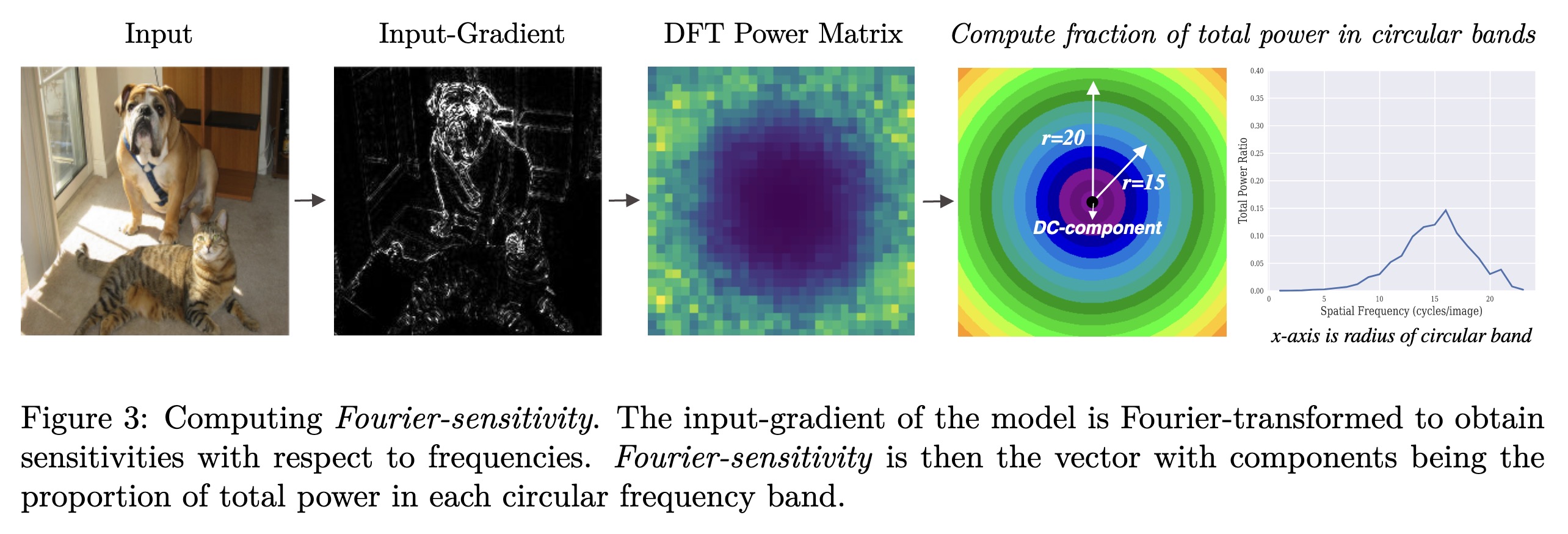
"Fourier Sensitivity and Regularization of Computer Vision Models. (arXiv:2301.13514v1 [cs.CV])" — A study of the frequency sensitivity characteristics of deep neural networks using a principled approach due to recent work showing that deep neural networks latch on to the Fourier statistics of training data and show increased sensitivity to Fourier-basis directions in the input.
Paper: http://arxiv.org/abs/2301.13514
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Computing Fourier-sensitivity. …
Paper: http://arxiv.org/abs/2301.13514
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Computing Fourier-sensitivity. …
0
2
1
Fahim Farook
f
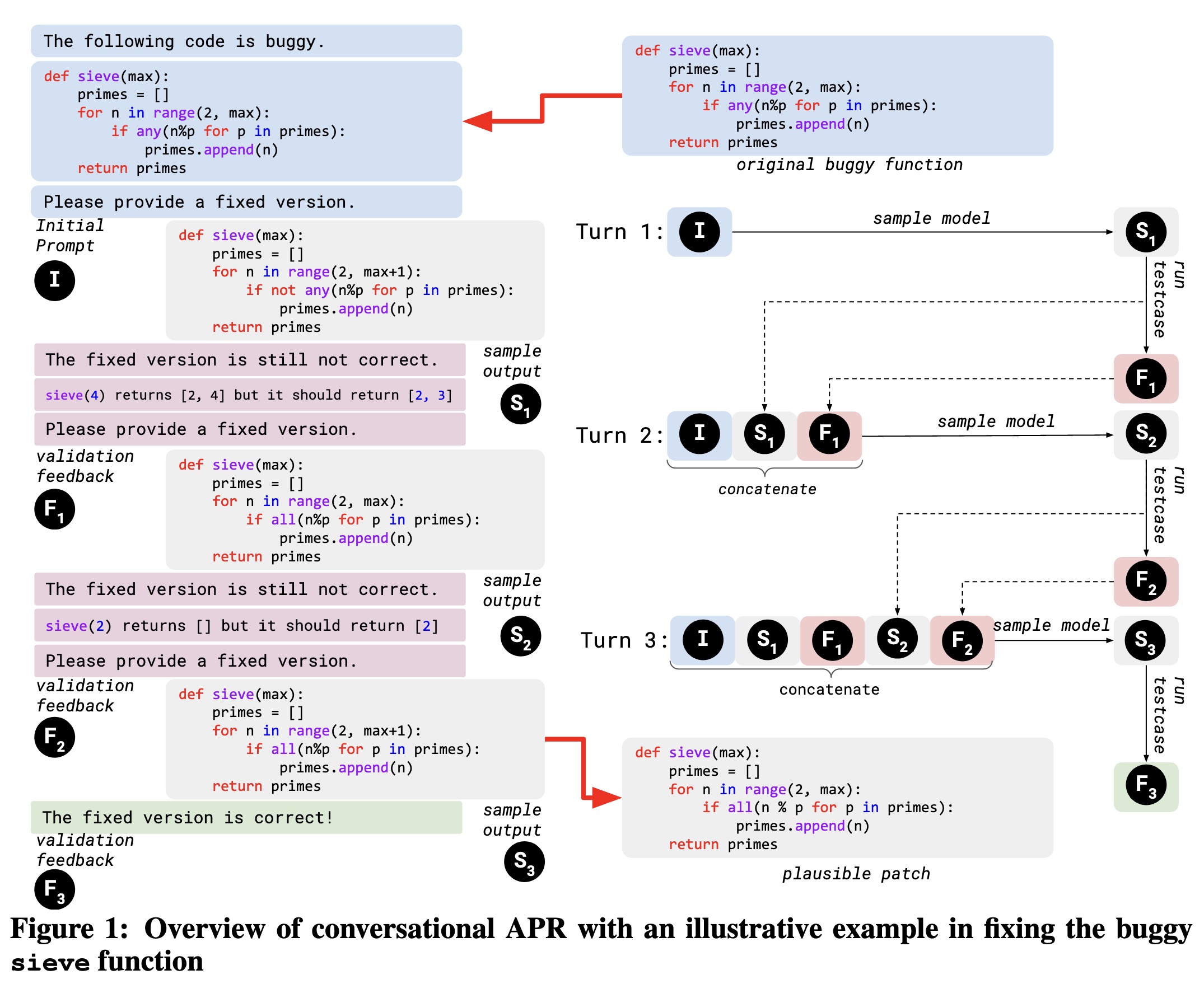
"Conversational Automated Program Repair" — A method to help developers automatically generate patches for bugs using Large Language Models (LLMs) using a conversational approach for patch generation and validation.
Paper: https://arxiv.org/abs/2301.13246
#AI #NewPaper #MachineLearning #SoftwareEngineering
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of conversational APR …
Paper: https://arxiv.org/abs/2301.13246
#AI #NewPaper #MachineLearning #SoftwareEngineering
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of conversational APR …
0
0
1
Fahim Farook
f
"Continuous Spatiotemporal Transformers. (arXiv:2301.13338v1 [cs.LG])" — A new transformer architecture that is designed for the modeling of continuous systems which guarantees a continuous and smooth output via optimization in Sobolev space.
Paper: http://arxiv.org/abs/2301.13338
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diagram of CST’s workflow. (A) …
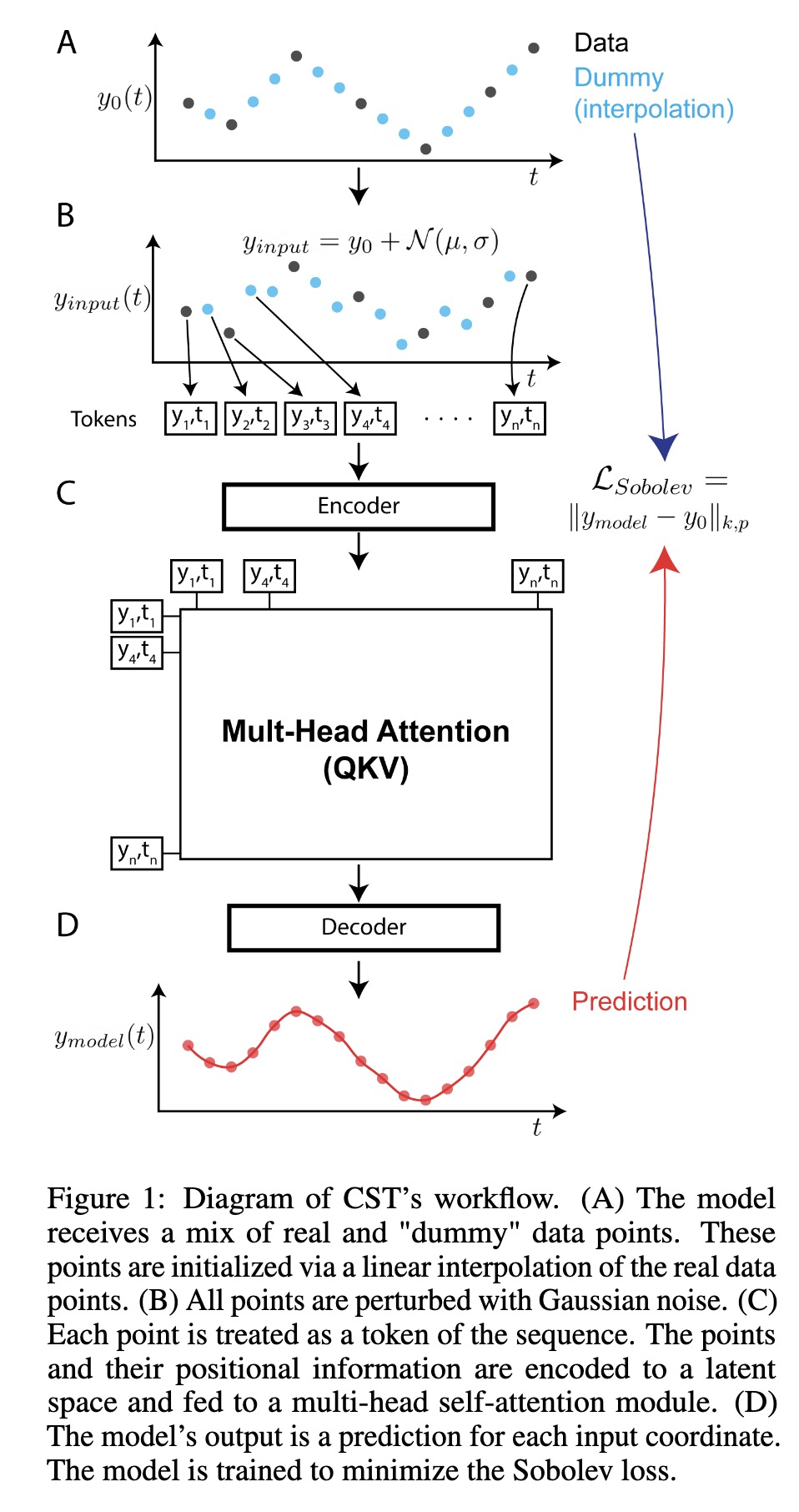
Paper: http://arxiv.org/abs/2301.13338
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diagram of CST’s workflow. (A) …
0
1
1
Fahim Farook
f
"ERA-Solver: Error-Robust Adams Solver for Fast Sampling of Diffusion Probabilistic Models. (arXiv:2301.12935v2 [cs.LG] UPDATED)" — An error-robust Adams solver (ERA-Solver), which utilizes the implicit Adams numerical method that consists of a predictor and a corrector.
Paper: http://arxiv.org/abs/2301.12935
Note: The PDF for this version of the paper is currently not available
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We adopt the pretrained diffusi…
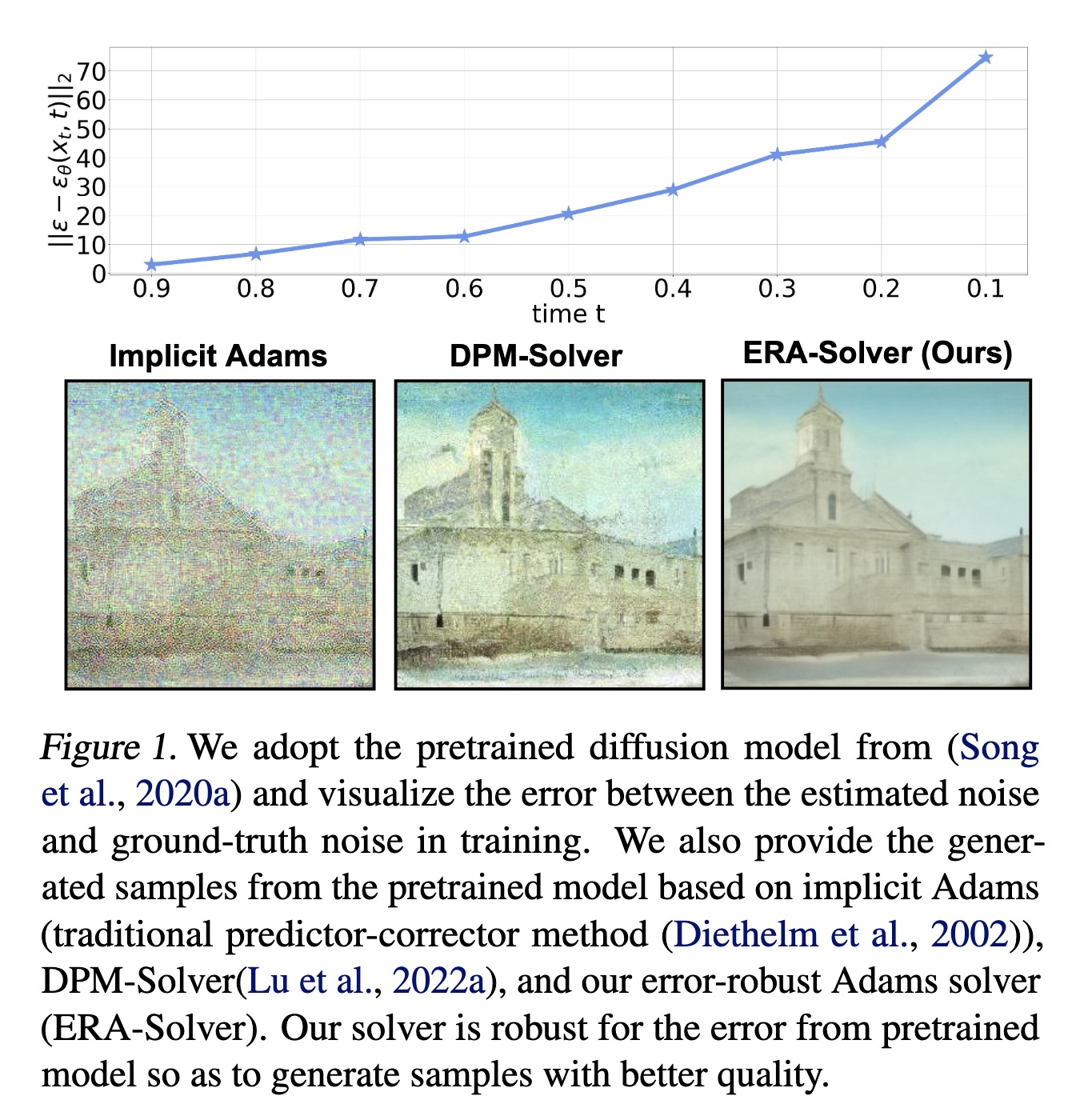
Paper: http://arxiv.org/abs/2301.12935
Note: The PDF for this version of the paper is currently not available
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We adopt the pretrained diffusi…
0
1
0
Fahim Farook
f
"PromptMix: Text-to-image diffusion models enhance the performance of lightweight networks. (arXiv:2301.12914v2 [cs.CV] UPDATED)" — A method for artificially boosting the size of existing datasets, that can be used to improve the performance of lightweight networks.
Paper: http://arxiv.org/abs/2301.12914
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of PromptMix
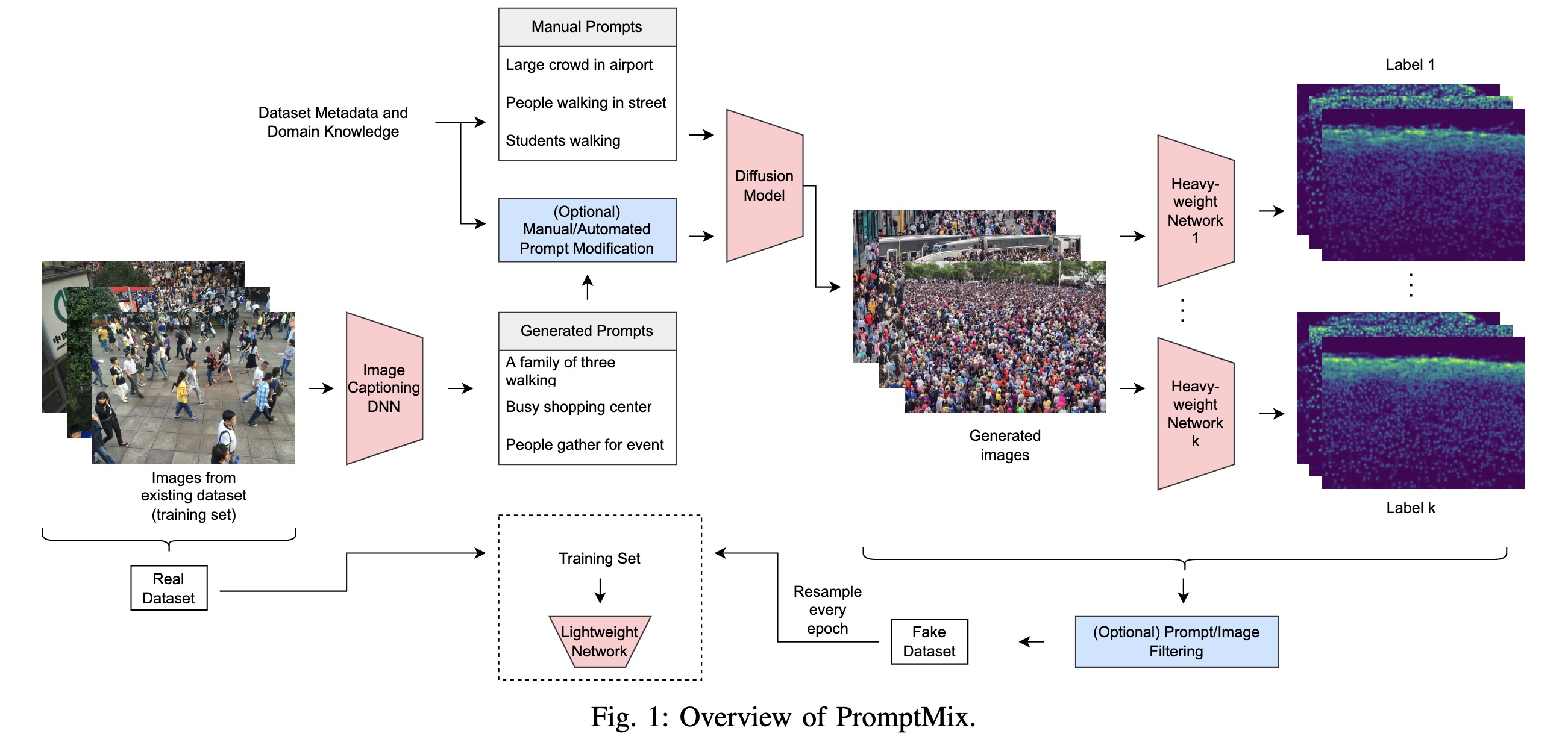
Paper: http://arxiv.org/abs/2301.12914
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of PromptMix
0
1
0
Fahim Farook
f
"MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models. (arXiv:2210.01820v2 [cs.CV] UPDATED)" — A family of neural networks that build on top of mobile convolution (i.e., inverted residual blocks) and attention which not only enhances the network representation capacity, but also produces better downsampled features.
Paper: http://arxiv.org/abs/2210.01820
Code: https://github.com/google-research/deeplab2
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Block comparison. (a) The MBCon…
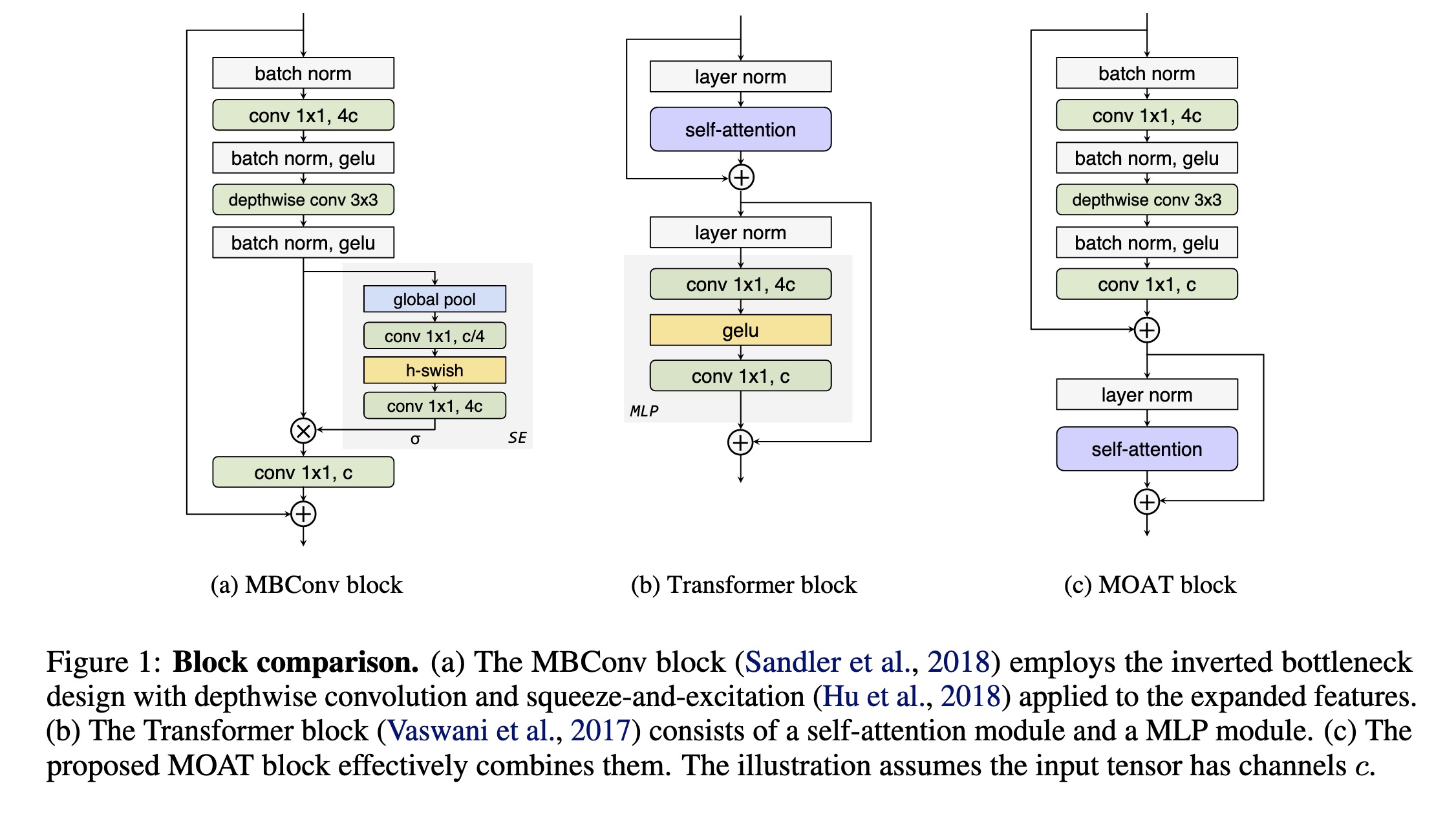
Paper: http://arxiv.org/abs/2210.01820
Code: https://github.com/google-research/deeplab2
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Block comparison. (a) The MBCon…
0
1
0
Fahim Farook
f
"DAG: Depth-Aware Guidance with Denoising Diffusion Probabilistic Models. (arXiv:2212.08861v2 [cs.CV] UPDATED)" — A guidance method for diffusion models that uses estimated depth information derived from the rich intermediate representations of diffusion models.
Paper: http://arxiv.org/abs/2212.08861
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative comparisons of synt…

Paper: http://arxiv.org/abs/2212.08861
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Qualitative comparisons of synt…
0
1
0
Fahim Farook
f
"Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis. (arXiv:2212.05032v2 [cs.CV] UPDATED)" — Improving the compositional skills of text-to-image models; specifically, obtainining more accurate attribute binding and better image compositions by incorporating linguistic structures with the diffusion guidance process based on the controllable properties of manipulating cross-attention layers in diffusion-based models.
Paper: http://arxiv.org/abs/2212.05032
Code: https://github.com/weixi-feng/structured-diffusion-guidance
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three challenging phenomena in …

Paper: http://arxiv.org/abs/2212.05032
Code: https://github.com/weixi-feng/structured-diffusion-guidance
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three challenging phenomena in …
0
1
1
Fahim Farook
f
"Refining Generative Process with Discriminator Guidance in Score-based Diffusion Models. (arXiv:2211.17091v2 [cs.CV] UPDATED)" — A generative SDE with score adjustment using an auxiliary discriminator with the goal of improving the original generative process of a pre-trained diffusion model by estimating the gap between the pre-trained score estimation and the true data score.
Paper: http://arxiv.org/abs/2211.17091
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of the denoising pro…

Paper: http://arxiv.org/abs/2211.17091
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of the denoising pro…
0
1
0
Fahim Farook
f
"Learning on tree architectures outperforms a convolutional feedforward network. (arXiv:2211.11378v3 [cs.CV] UPDATED)" — A 3-layer tree architecture inspired by experimental-based dendritic tree adaptations is developed and applied to the offline and online learning of the CIFAR-10 database to show that this architecture outperforms the achievable success rates of the 5-layer convolutional LeNet.
Paper: http://arxiv.org/abs/2211.11378
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of offline and onlin…
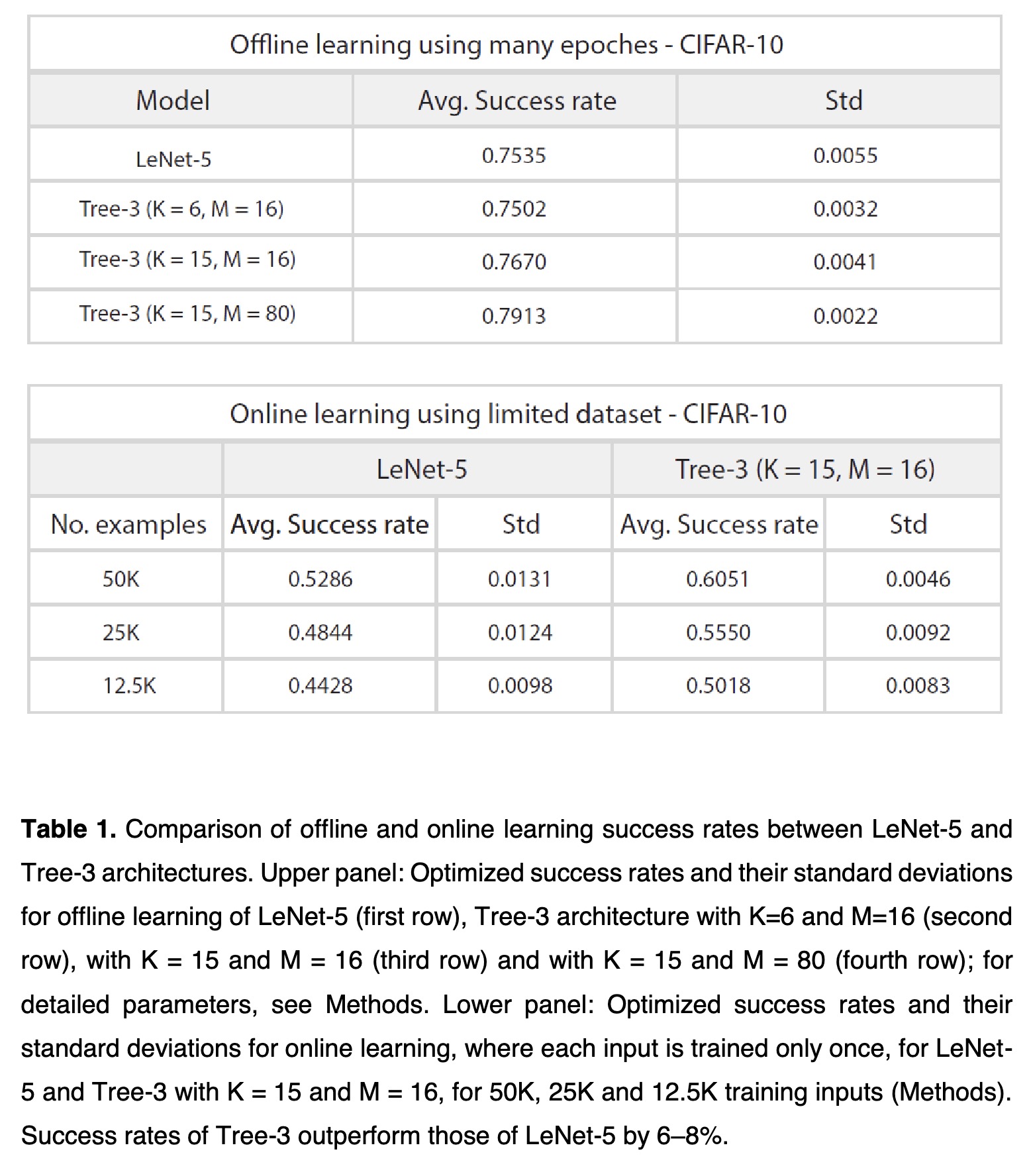
Paper: http://arxiv.org/abs/2211.11378
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of offline and onlin…
0
1
1
Fahim Farook
f
"Continual Learning by Modeling Intra-Class Variation. (arXiv:2210.05398v2 [cs.LG] UPDATED)" — An examination of memory-based continual learning which identifies that large variation in the representation space is crucial for avoiding catastrophic forgetting.
Paper: http://arxiv.org/abs/2210.05398
Code: https://github.com/yulonghui/moca
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Average intra-class angle devia…
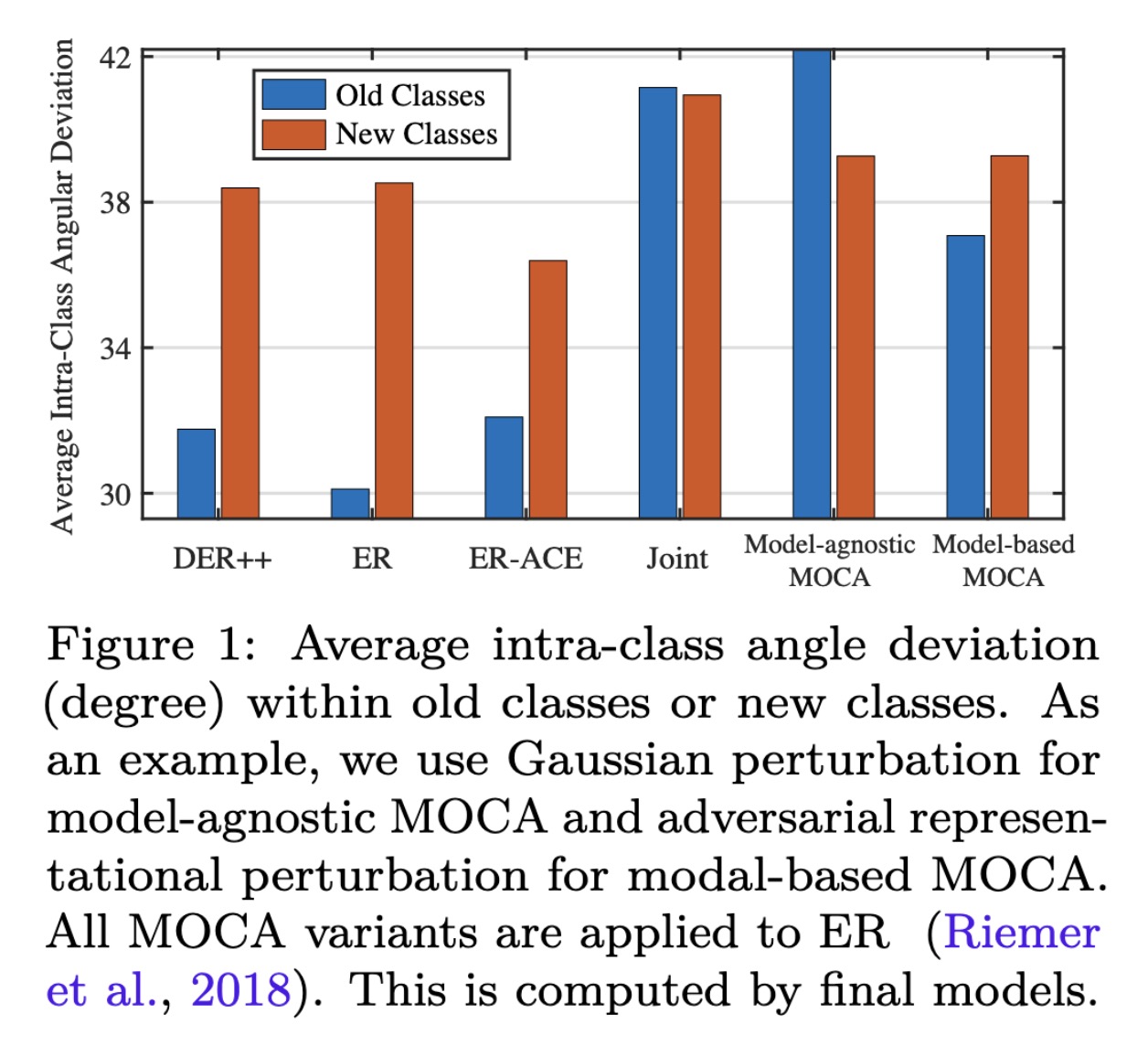
Paper: http://arxiv.org/abs/2210.05398
Code: https://github.com/yulonghui/moca
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Average intra-class angle devia…
0
1
0
Fahim Farook
f
"Scalable and Equivariant Spherical CNNs by Discrete-Continuous (DISCO) Convolutions. (arXiv:2209.13603v3 [cs.CV] UPDATED)" — A hybrid discrete-continuous (DISCO) group convolution for spherical convolutional neural networks (CNN) that is simultaneously equivariant and computationally scalable to high-resolution.
Paper: http://arxiv.org/abs/2209.13603
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Spherical CNN categorization
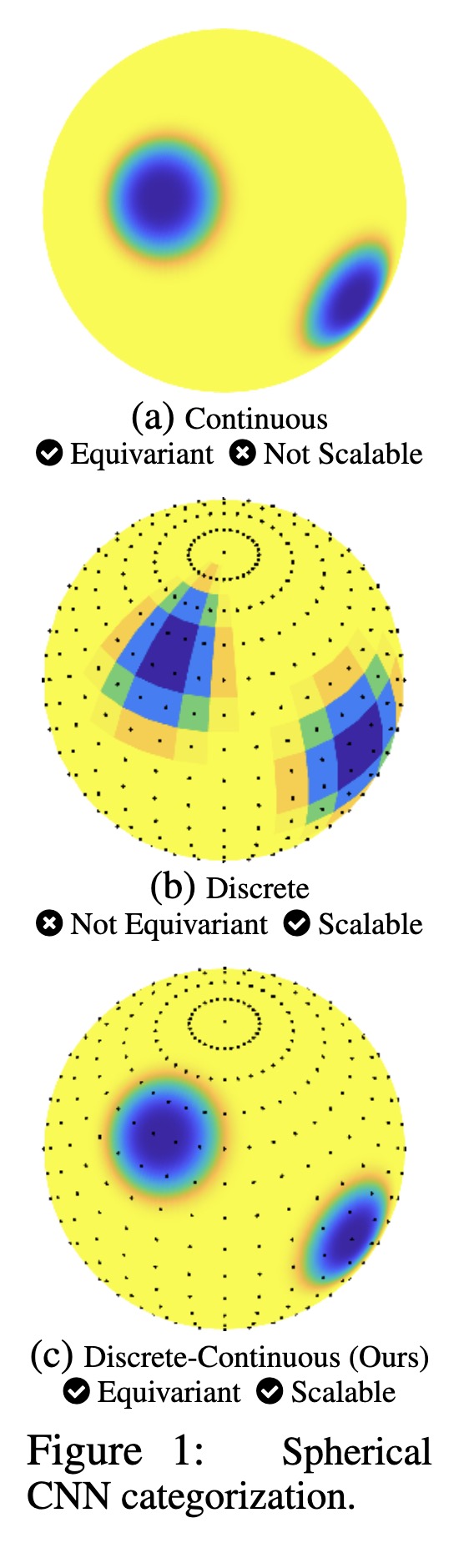
Paper: http://arxiv.org/abs/2209.13603
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Spherical CNN categorization
0
0
1
Fahim Farook
f
"Multi-Level Visual Similarity Based Personalized Tourist Attraction Recommendation Using Geo-Tagged Photos. (arXiv:2109.08275v2 [cs.MM] UPDATED)" — A geo-tagged photo based tourist attraction recommendation system which utilizes the visual contents of photos and interaction behavior data to obtain the final embeddings of users and tourist attractions, which are then used to predict the visit probabilities.
Paper: http://arxiv.org/abs/2109.08275
Code: https://github.com/revaludo/MEAL
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustration of the multi-le…
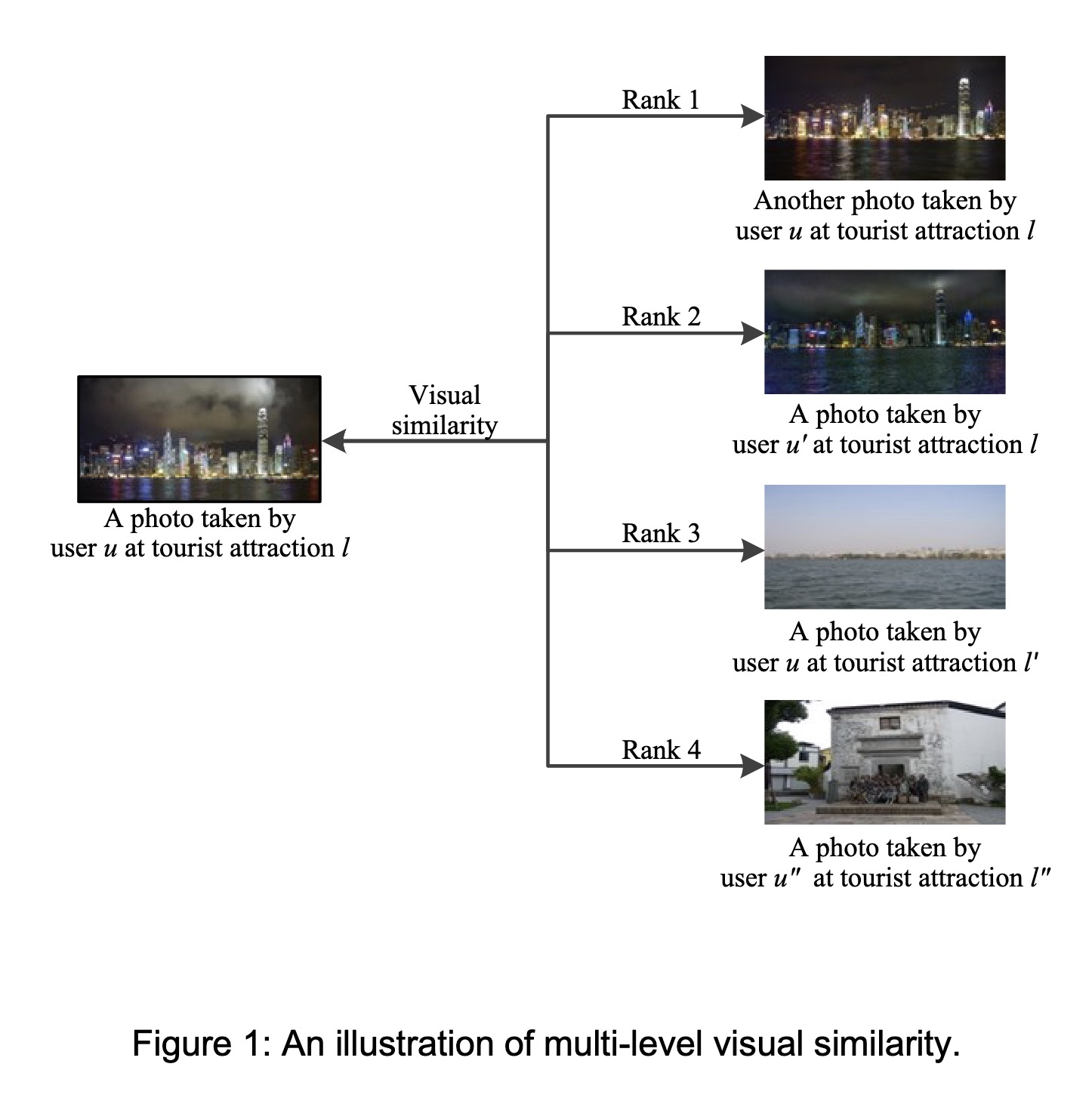
Paper: http://arxiv.org/abs/2109.08275
Code: https://github.com/revaludo/MEAL
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustration of the multi-le…
0
0
0
Fahim Farook
f
"BiAdam: Fast Adaptive Bilevel Optimization Methods. (arXiv:2106.11396v3 [math.OC] UPDATED)" — A novel fast adaptive bilevel framework to solve stochastic bilevel optimization problems that the outer problem is possibly nonconvex and the inner problem is strongly convex.
Paper: http://arxiv.org/abs/2106.11396
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The basic idea of the convergen…
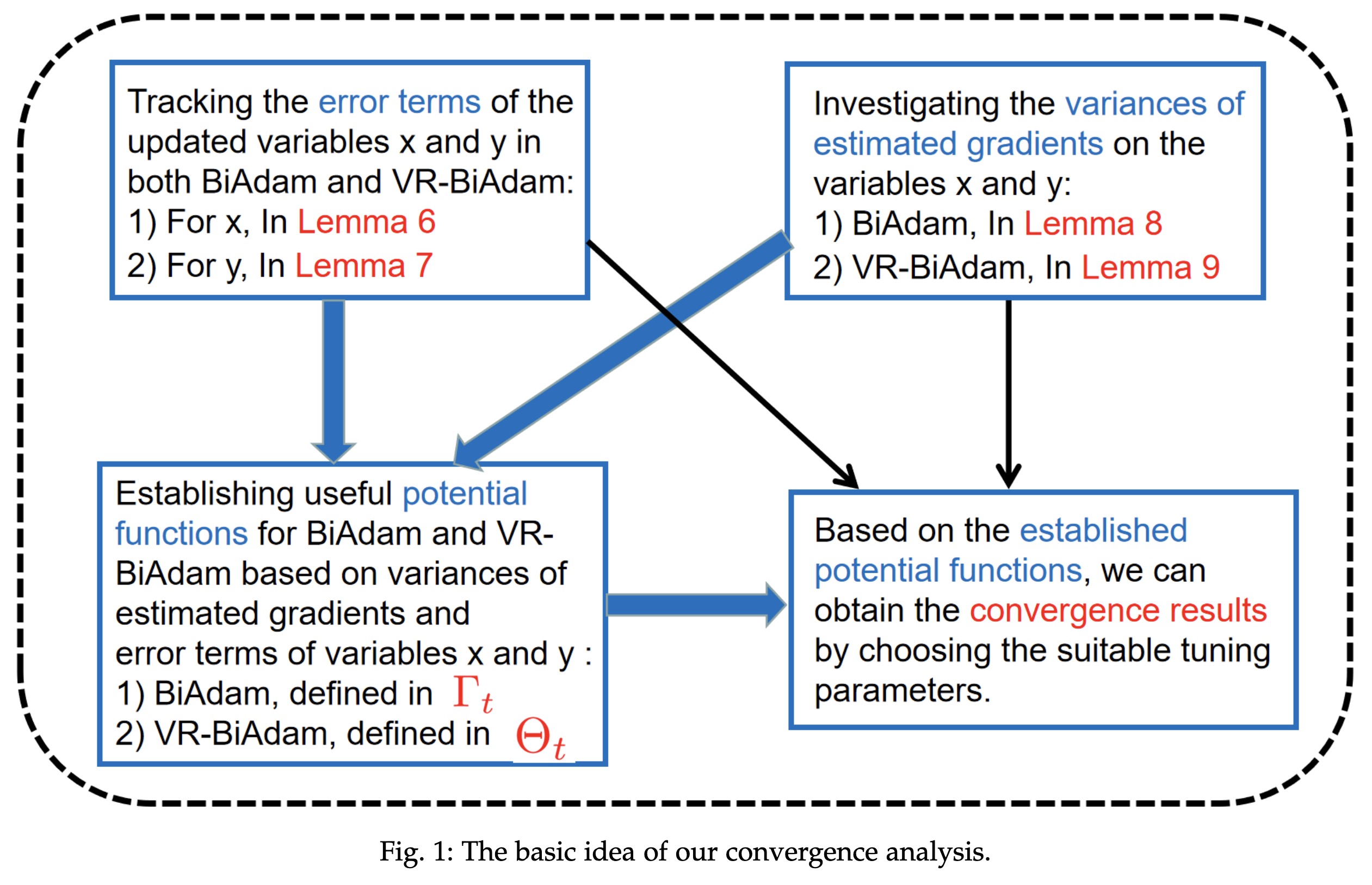
Paper: http://arxiv.org/abs/2106.11396
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The basic idea of the convergen…
0
0
0
Fahim Farook
f
"Sparse Oblique Decision Trees: A Tool to Understand and Manipulate Neural Net Features. (arXiv:2104.02922v2 [cs.LG] UPDATED)" — An effort to understanding which of the internal features computed by the neural net are responsible for a particular class, by mimicking part of the neural net with an oblique decision tree having sparse weight vectors at the decision nodes.
Paper: http://arxiv.org/abs/2104.02922
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Mimicking part of a neural net …

Paper: http://arxiv.org/abs/2104.02922
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Mimicking part of a neural net …
0
1
0
Fahim Farook
f
"Don't Play Favorites: Minority Guidance for Diffusion Models. (arXiv:2301.12334v1 [cs.LG])" — A framework that can make the generation process of the diffusion models focus on the minority samples, which are instances that lie on low-density regions of a data manifold.
Paper: http://arxiv.org/abs/2301.12334
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion models play favorites…

Paper: http://arxiv.org/abs/2301.12334
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion models play favorites…
0
1
0
Fahim Farook
f
"SEGA: Instructing Diffusion using Semantic Dimensions. (arXiv:2301.12247v1 [cs.CV])" — A semantic guidance method for diffusion models to allow making subtle and extensive edits and changes in composition and style, as well as optimize the overall artistic conception.
Paper: http://arxiv.org/abs/2301.12247
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Semantic control over image gen…

Paper: http://arxiv.org/abs/2301.12247
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Semantic control over image gen…
0
1
0
Fahim Farook
f
"Anticipate, Ensemble and Prune: Improving Convolutional Neural Networks via Aggregated Early Exits. (arXiv:2301.12168v1 [cs.LG])" — A new training technique based on weighted ensembles of early exits, which aims at exploiting the information in the structure of networks to maximise their performance.
Paper: http://arxiv.org/abs/2301.12168
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outline of the AEP technique. O…
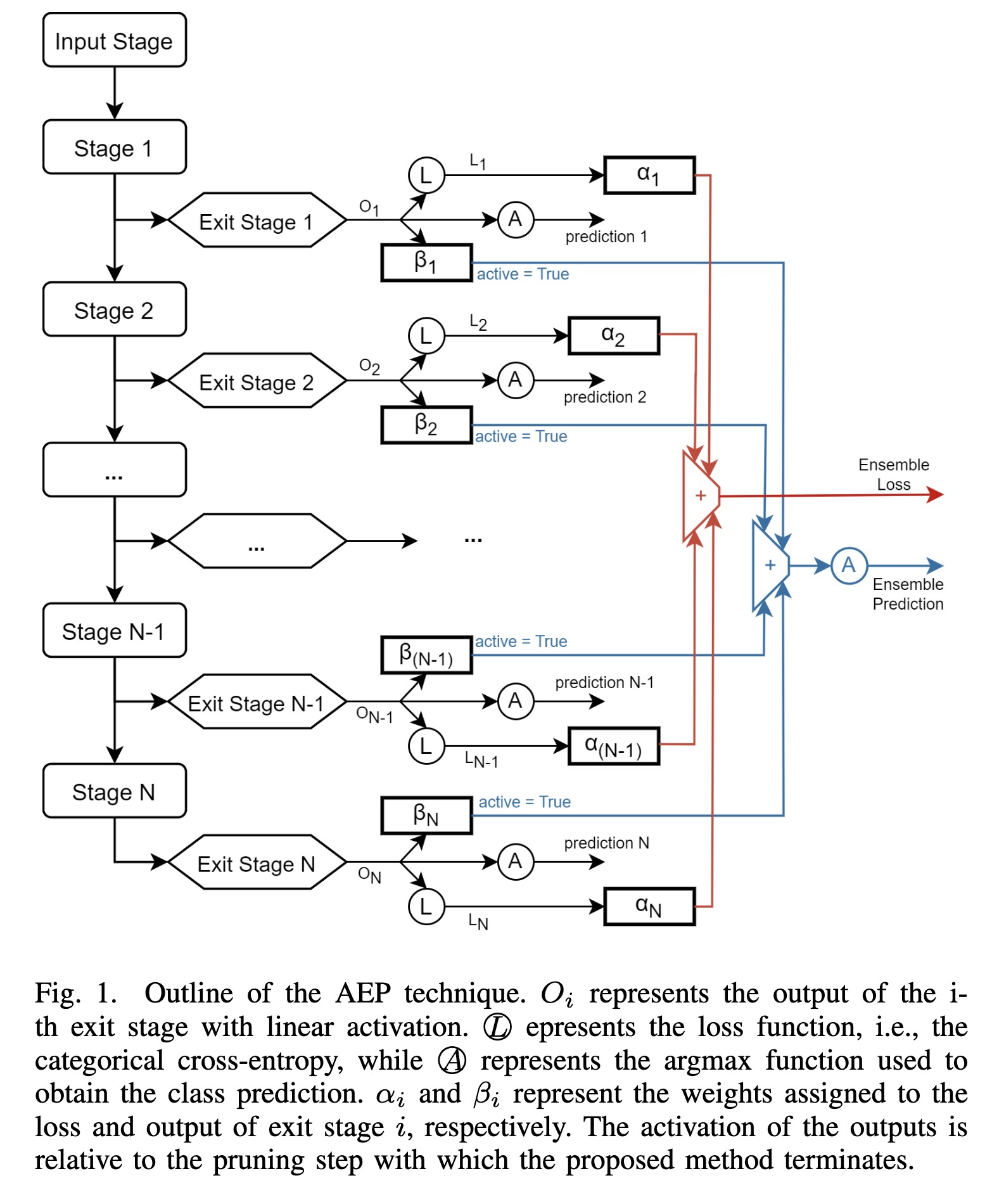
Paper: http://arxiv.org/abs/2301.12168
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outline of the AEP technique. O…
0
1
0