Fahim Farook
Posts
1641Following
139Followers
886I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"MemeTector: Enforcing deep focus for meme detection. (arXiv:2205.13268v2 [cs.CV] UPDATED)" — A methodology that utilizes the visual part of image memes as instances of the regular image class and the initial image memes as instances of the image meme class to force the model to concentrate on the critical parts that characterize an image meme.
Paper: http://arxiv.org/abs/2205.13268
Code: https://github.com/mever-team/memetector
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example image meme vs. a regula…

Paper: http://arxiv.org/abs/2205.13268
Code: https://github.com/mever-team/memetector
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example image meme vs. a regula…
 0
0
 1
1
 0
0
Fahim Farook
f
"Learning Sequential Latent Variable Models from Multimodal Time Series Data. (arXiv:2204.10419v2 [cs.LG] UPDATED)" — A self-supervised generative modelling framework to jointly learn a probabilistic latent state representation of multimodal data and the respective dynamics to improve prediction and representation quality.
Paper: http://arxiv.org/abs/2204.10419
Code: https://github.com/utiasstars/visual-haptic-dynamics
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We learn a sequential latent va…
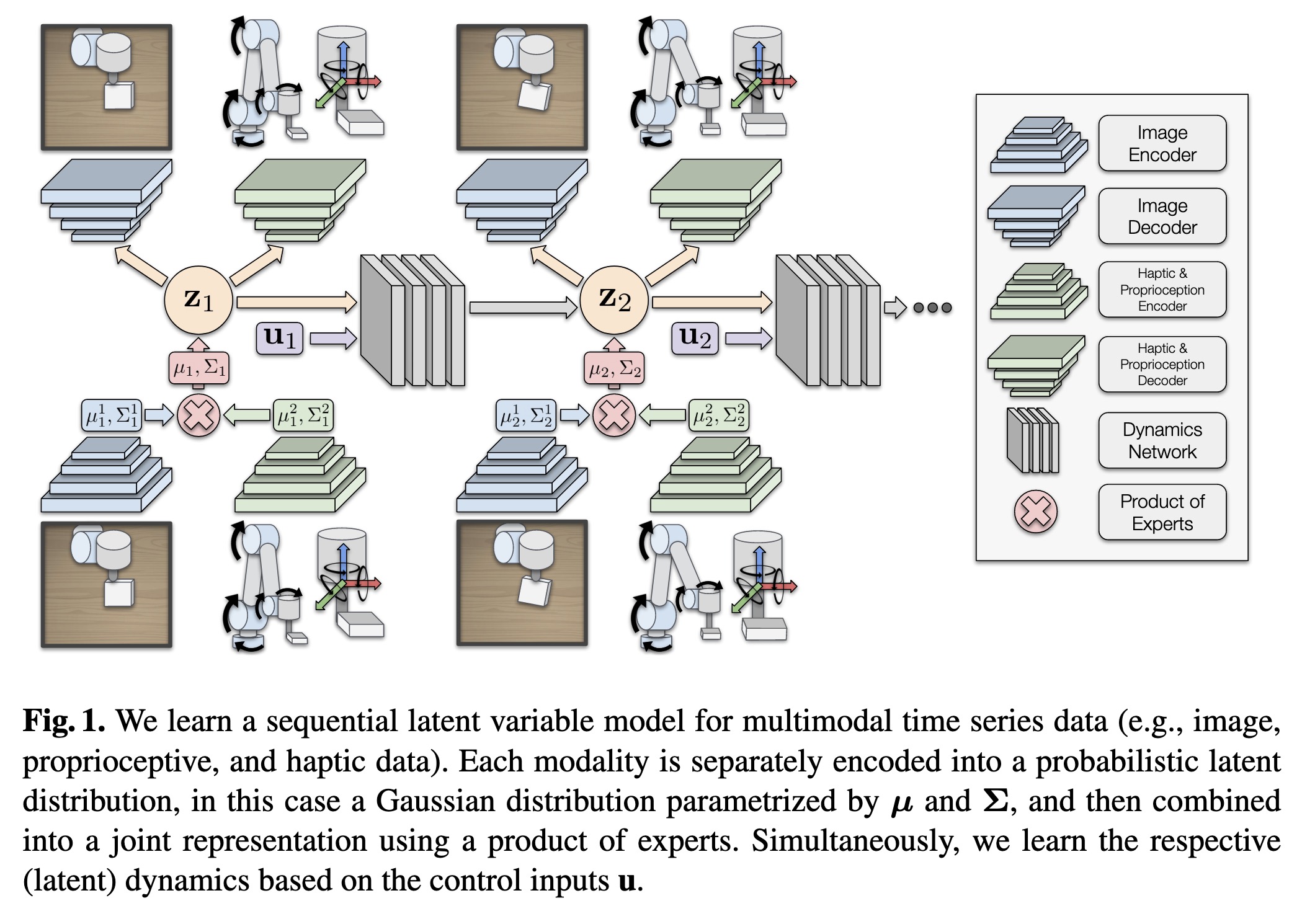
Paper: http://arxiv.org/abs/2204.10419
Code: https://github.com/utiasstars/visual-haptic-dynamics
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We learn a sequential latent va…
0
2
1
Fahim Farook
f
"REx: Data-Free Residual Quantization Error Expansion. (arXiv:2203.14645v2 [cs.CV] UPDATED)" — A quantization method that leverages residual error expansion, along with group sparsity and an ensemble approximation for better parallelization.
Paper: http://arxiv.org/abs/2203.14645
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the proposed me…
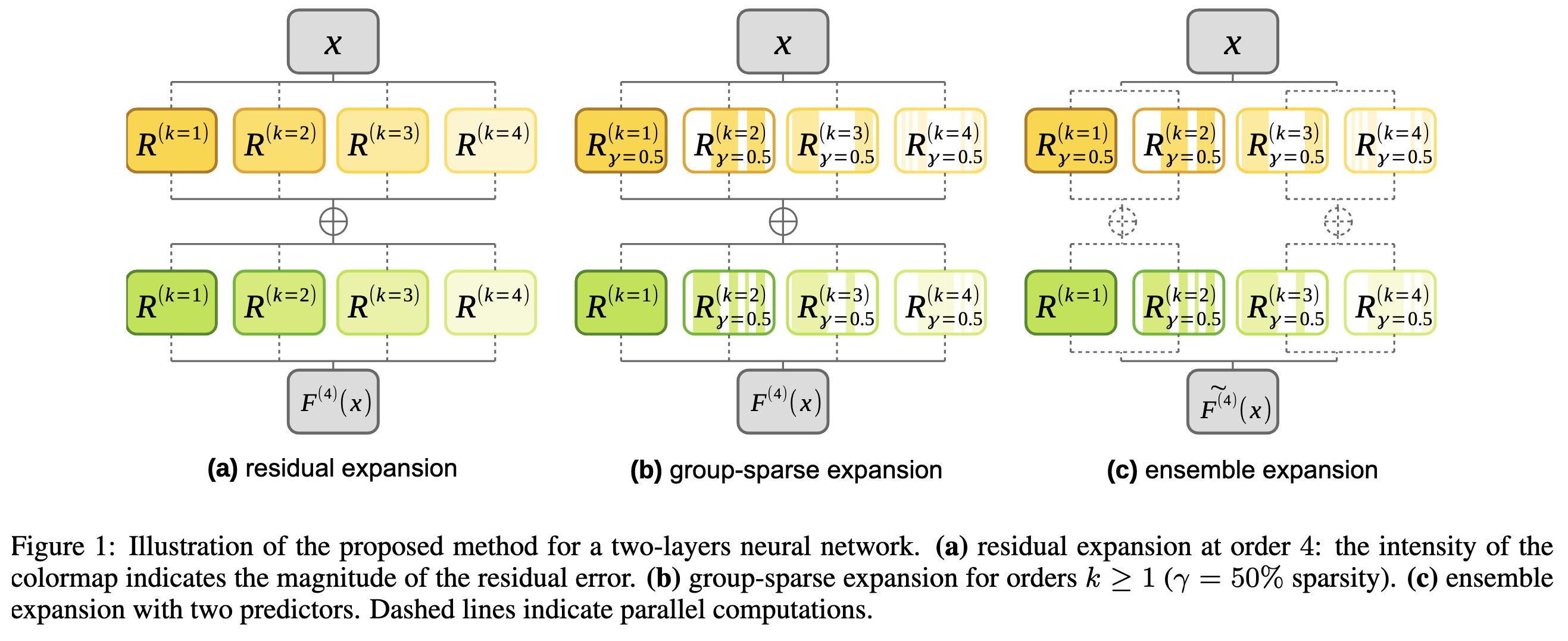
Paper: http://arxiv.org/abs/2203.14645
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Illustration of the proposed me…
0
1
0
Fahim Farook
f
"Novel-View Acoustic Synthesis. (arXiv:2301.08730v1 [cs.CV])" — Given the sight and sound observed at a source viewpoint, synthesizing the *sound* of that scene from an unseen target viewpoint using a neural rendering approach.
Paper: http://arxiv.org/abs/2301.08730
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Novel-view acoustic synthesis t…
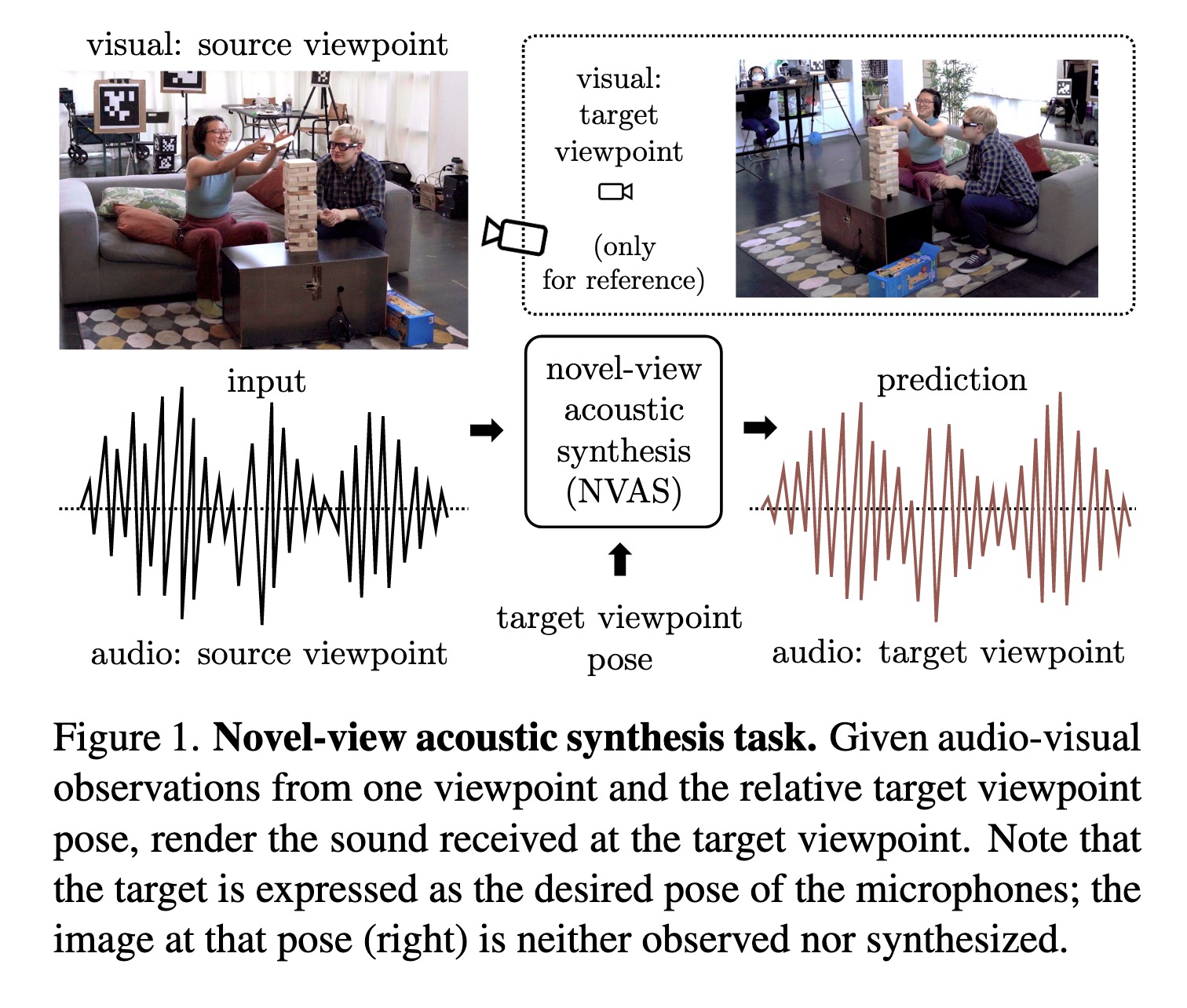
Paper: http://arxiv.org/abs/2301.08730
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Novel-view acoustic synthesis t…
0
2
0
Fahim Farook
f
"Visual Writing Prompts: Character-Grounded Story Generation with Curated Image Sequences. (arXiv:2301.08571v1 [cs.CL])" — A new image-grounded dataset for improving visual story generation due to the fact that existing image sequence collections do not have coherent plots behind them.
Paper: http://arxiv.org/abs/2301.08571
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of Visual Writing Pr…

Paper: http://arxiv.org/abs/2301.08571
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison of Visual Writing Pr…
0
2
3
Fahim Farook
f
"When Source-Free Domain Adaptation Meets Label Propagation. (arXiv:2301.08413v1 [cs.CV])" — An approach that tries to achieve efficient feature clustering from the perspective of label propagation by dividing the target data into inner and outlier samples based on the adaptive threshold of the learning state, and applying a customized learning strategy to best fits the data property.
Paper: http://arxiv.org/abs/2301.08413
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A toy illustration of target fe…
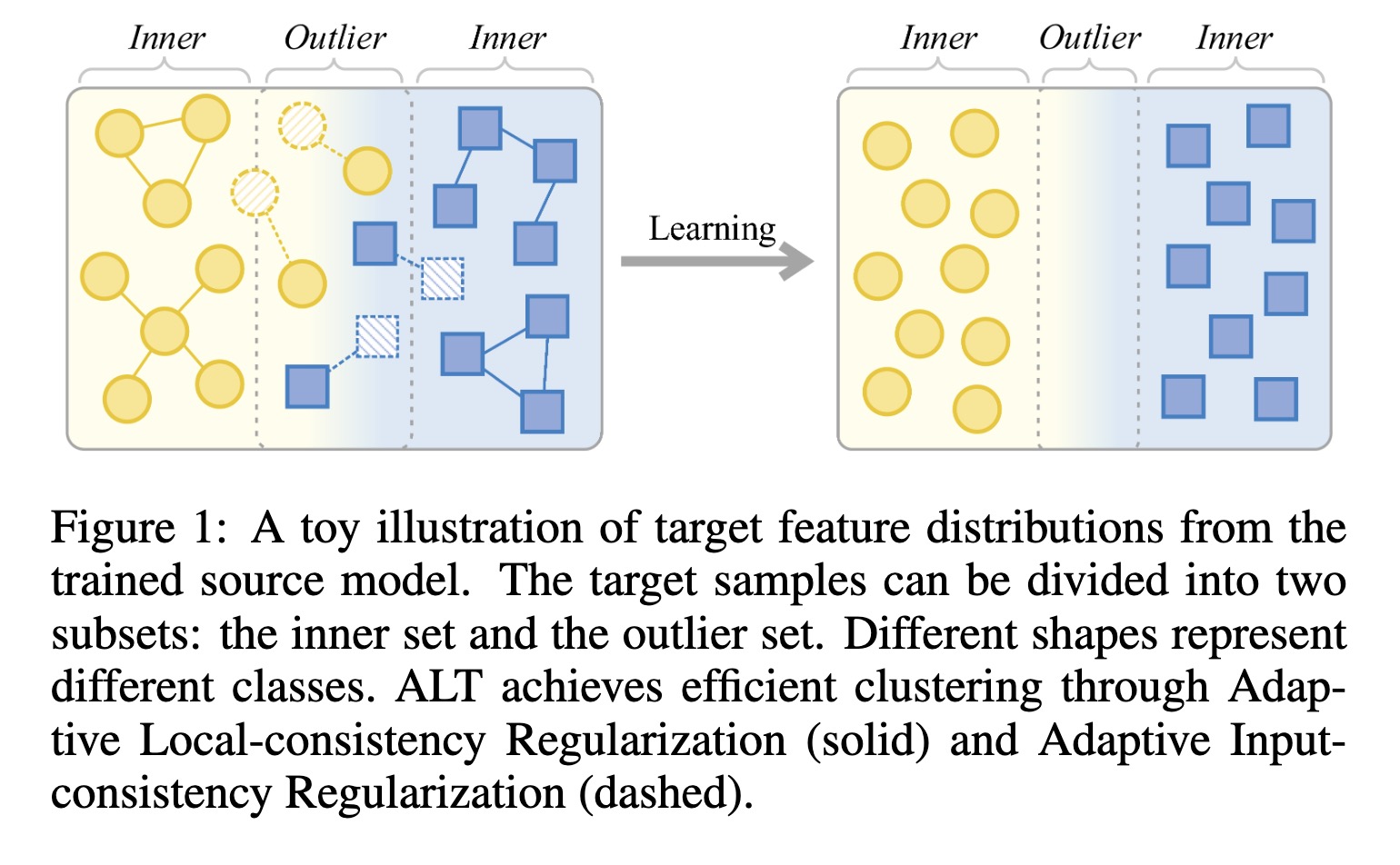
Paper: http://arxiv.org/abs/2301.08413
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A toy illustration of target fe…
0
1
0
Fahim Farook
f
"Open-Set Likelihood Maximization for Few-Shot Learning. (arXiv:2301.08390v1 [cs.CV])" — A generalization of the maximum likelihood principle, in which latent scores down-weighing the influence of potential outliers are introduced alongside the usual parametric model. This implementation can be applied on top of any pre-trained model seamlessly.
Paper: http://arxiv.org/abs/2301.08390
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Intuition behind OSLO. Standard…
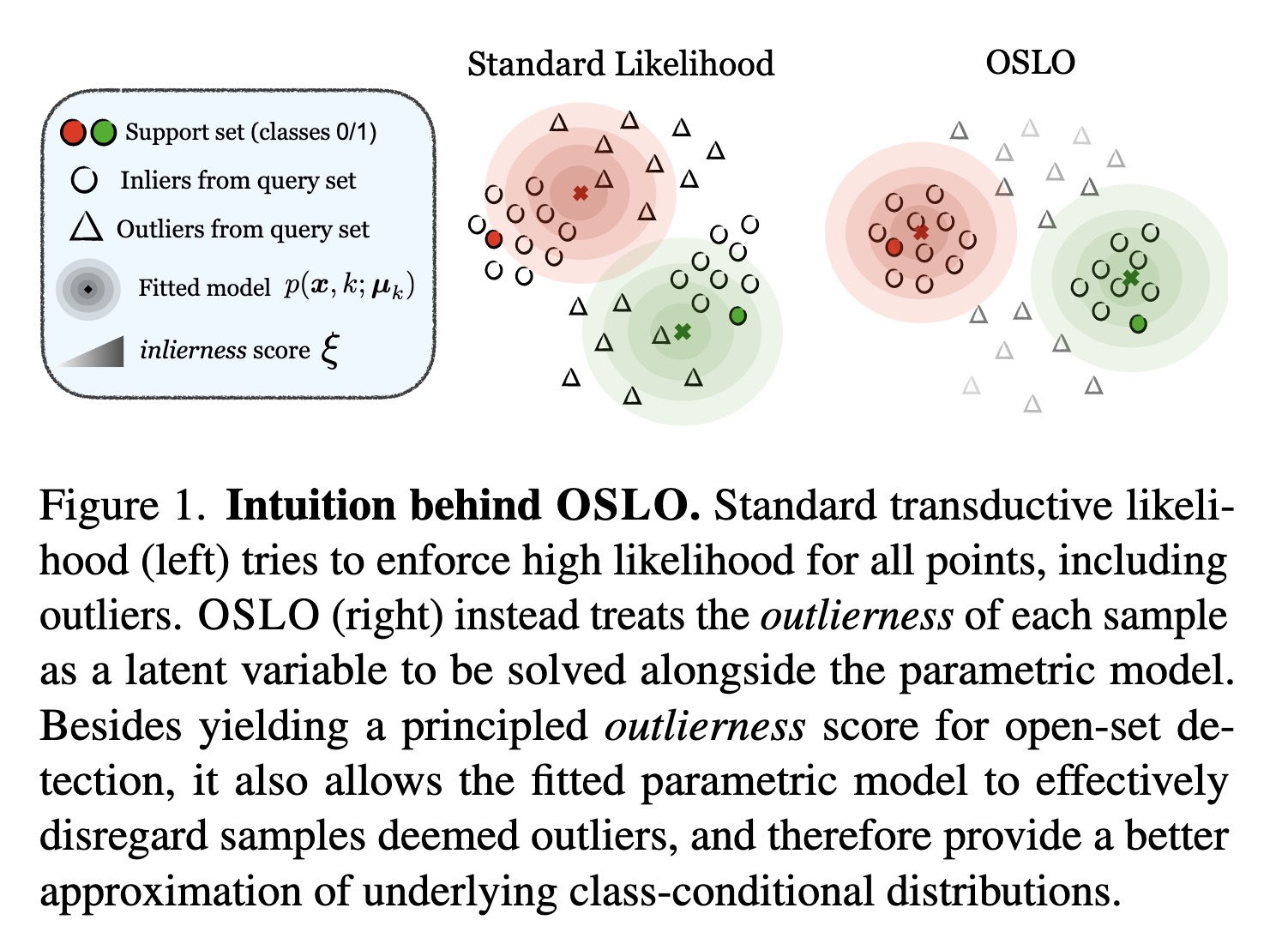
Paper: http://arxiv.org/abs/2301.08390
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Intuition behind OSLO. Standard…
0
1
2