Posts
1600Following
138Followers
882I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
Paper: http://arxiv.org/abs/2208.09141
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The forward diffusion process a…

 0
0
 1
1
 0
0
Fahim Farook
fPaper: http://arxiv.org/abs/2302.07257
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of our proposed strate…
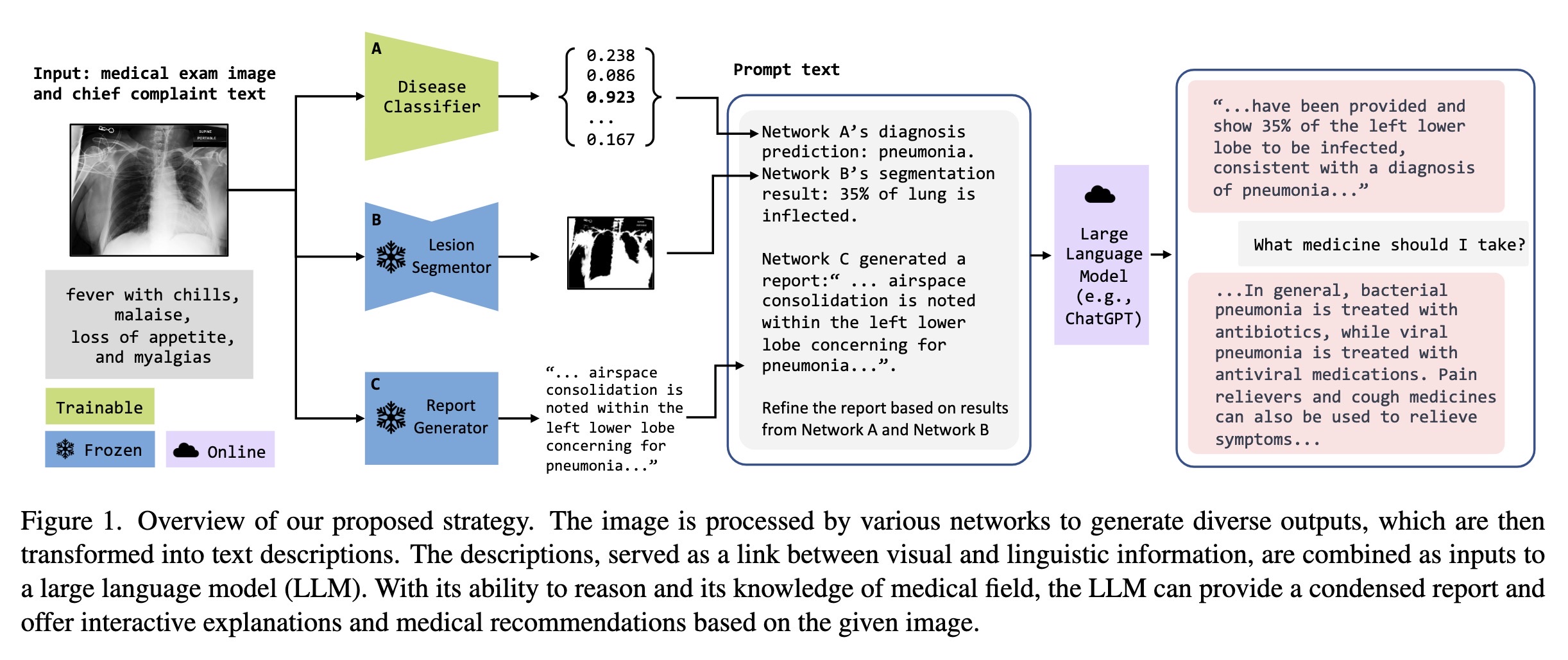 0
0
0
0
0
0
Fahim Farook
fPaper: http://arxiv.org/abs/2302.07224
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given only a single semantic ma…
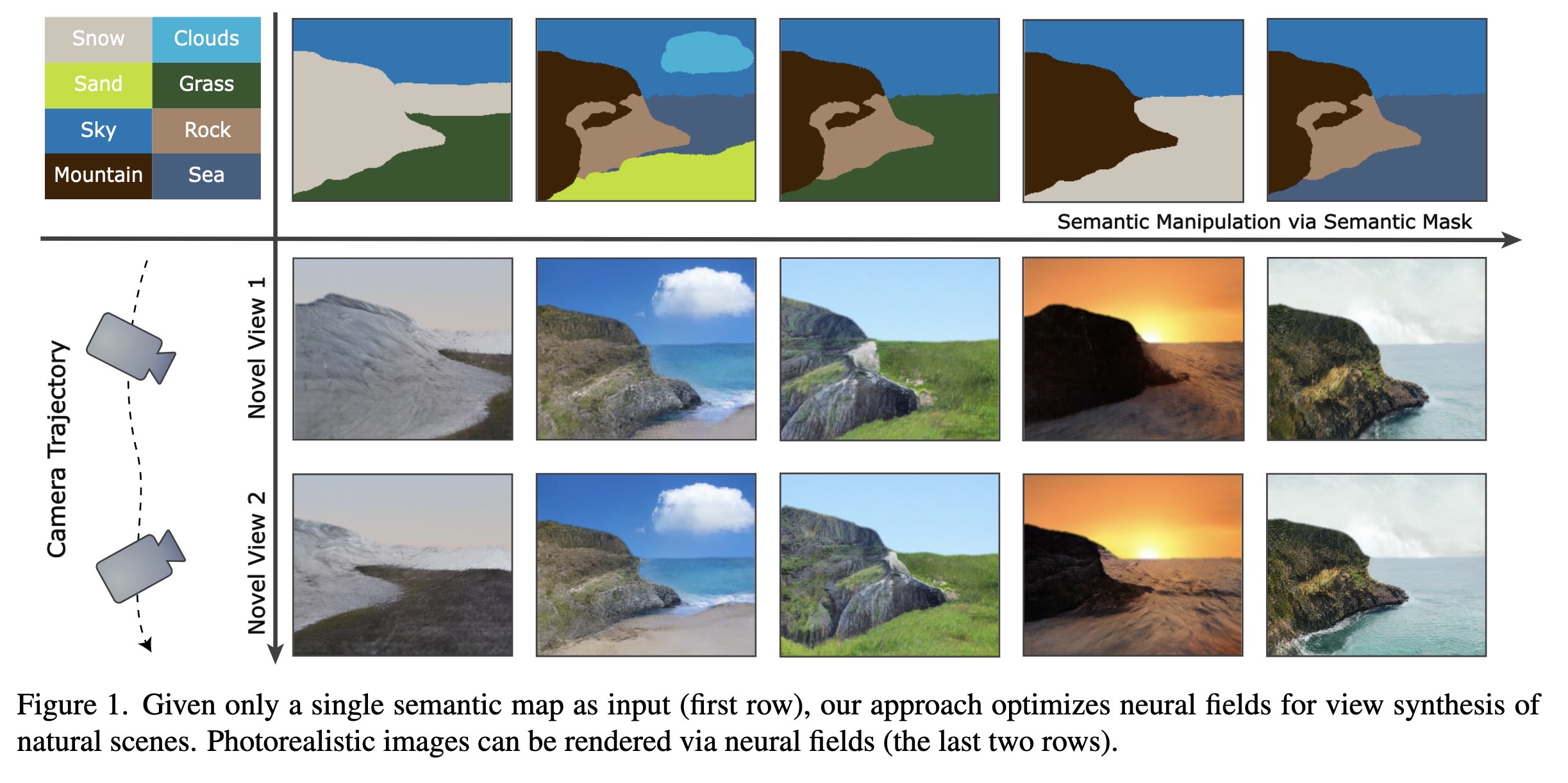 0
1
0
0
1
0
Fahim Farook
fPaper: http://arxiv.org/abs/2302.07136
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
0
2
0
Fahim Farook
fPaper: http://arxiv.org/abs/2302.07121
Code: https://github.com/arpitbansal297/Universal-Guided-Diffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of diffusion being gui…
 0
1
2
0
1
2
Fahim Farook
fHave CoreML models I want to play with, but I guess I’ll have to read papers instead 😛
#AI #CV #NewPapers #DeepLearning #MachineLearning
0
0
0
Fahim Farook
fSo, in case this helps anybody else, here are the important things to remember:
1. You *must* use Python 3.8. If you any other Python version, you will end up with errors. (Not that I’ve tested all Python versions, but I did have errors with Python 3.9 and have read reports of others …)
2. You should be on Ventura 13.1 or higher.
3. You need the models to be in Diffusers format to run the conversion, but the easiest way that has worked for me is to download a CKPT file, convert it to Diffusers and point the script at the local folder with the Diffusers format model.
4. HuggingFace folks have a bunch of conversion scripts here: https://github.com/huggingface/diffusers/tree/main/scripts
5. The above scripts don’t mention SAFETENSOR format in the file names but SAFETENSOR is just CKPT with some changes. The CKPT conversion file has an extra argument named “--from_safetensors” so you can use the same script for CKPT to convert SAFETENSOR files with that extra argument.
6. You can use the Apple conversion script to convert one element at at a time using the different arguments such as “--convert-unet”, “--convert-text-encoder” etc. You don’t have to run all of them together. In fact, it turned out when I ran them all together, sometimes a component might be left out — generally the text encoder.
7. Once you’ve converted all the components and have them in one folder, you have to run the Apple conversion script once more with the “--bundle-resources-for-swift-cli” argument (pointing at your output folder) to create the final compiled CoreML model files (.mlmodelc) from your .mlpackage files.
That’s it 🙂 If you do all of the above, it should be fairly straightforward to create new CoreML models from existing StableDiffusion models.
Feel free to hit me up should you run into issues. Since I’ve gone through all this, I’d be happy to help anybody else facing the same issues ….
#CoreML #StableDiffusion #MachineLearning #DeepLearning #ModelConversion
0
1
1
repeated
Bryan Wright
catselbow@fosstodon.orgA tiny jumping spider pauses to take in the view.
#spiders #arachnids #spider #arthropods #nature #photography #macrophotography
 0
2
0
repeated
0
2
0
repeated
Low Quality Facts
lowqualityfacts@mstdn.social
Sounds awesome, please let us see it Joe.
https://patreon.com/lowqualityfacts
 3
2
0
repeated
3
2
0
repeated

 repeated
repeated
Katharina
Katharina@toot.walesPainted some pine trees and a Robin.
#watercolour #painting #pinetrees #Robin #landscapepainting #mastoart
 0
3
0
repeated
0
3
0
repeated
donni saphire
donni@mastodon.socialI get knocked down, but I get up again briefly, complain a lot, then lie back down voluntarily
1
3
0
repeated
Ben Hoare
BenHoare@toot.communityThis ancient goat willow is half-tree, half-octopus!
It may have been broken by a Cumbrian storm, but is still very much alive - and supporting lots of other life too. One of my favourite trees 💚
#ThickTrunkTuesday #nature #woodland #environment #Mosstodon #Cumbria #LakeDistrict



 1
4
0
1
4
0
Fahim Farook
fhttps://huggingface.co/FahimF/StableDiffusion-2.1_512_EINSUM_img2img
I’ve been creating a bunch of models which support image-2-image but it’ll take a while before I’m ready to upload all of them 🙂
#Model #StabelDiffusion #CoreML #img2img
1
0
1
Fahim Farook
fIncidentally, if you search HuggingFace for “coreml img2img” you will find a bunch of models which are supposed to work. But for whatever reason, those didn’t work for me. Maybe they were created before the latest changes to the Apple CoreML code?
Either way, I ended up spending the afternoon trying to generate new models which would work for img2img.
My first try was to go with Guernika (https://huggingface.co/Guernika/CoreMLStableDiffusion) since that has worked for me in the past. It has an option to create the Encoder that I needed, but unfortunately, that didn’t work.
I then spent some time trying a lot of things with the Apple Python code before I finally got it to work. So in case you are stuck in the same place, here are the important things to remember:
1. You need to use Python 3.8. This is very important. Other Python versions do not seem to work and result in errors.
2. I saw a note about also needing Ventura 13.1 or higher and this probably is correct since I know Apple added some changes to make StableDiffusion to work in Ventura 13.1 … but since I am on Ventura 13.2.1, I can’t verify this one for sure.
Once I did #1, the Apple Python code for generating models worked so much better. Their documentation is still a bit confusing and all over the place, but I was finally able to convert existing CKPT models to CoreML and be able to use them with img2img. So now I’m going to be doing a lot of conversions I guess? 🙂
0
1
2
repeated
 repeated
repeated
Rudy Rucker
rudytheelder@sfba.socialInvasion of the oak people. Hitched a ride on the pseudo-balloons (not actually) from China.
 0
2
0
repeated
0
2
0
repeated
LadyFluffyOrca
weaniejeanie53@mas.toThis is an ornate spiny lobster (Panulirus ornatus). Apparently this is what it takes to impress the girls in lobster world.... Works for me.
 11
3
0
repeated
11
3
0
repeated
Fox Moxin
CamWeck@mastodon.socialAnd I've been let go.
So uh.
Anyone in Philly Hiring a Data Analyst, let me know.
1
2
0
Fahim Farook
fYesterday's prompt was: "I Shall Wear Midnight"
Not much DiscWorld-iness in the images, but they all were suitably dark to represent midnight, I guess 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…



 1
2
6
1
2
6