Fahim Farook
Posts
1621Following
138Followers
881I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
 repeated
repeated
repeated
donni saphire
donni@mastodon.social
I get knocked down, but I get up again briefly, complain a lot, then lie back down voluntarily
 1
3
1
3
 0
0
Fahim Farook
f
@jesper I have a script which gives me the RSS feed for each day for a given category, filtering out anything I’d read the previous day 🙂 Not that there’s much overlap in the RSS feeds between days, mind you.
The script generates a table with the summary from each paper and I go through the summaries, find the ones I like and the table also has a link to the full PDF and so, if I like the summary, I go through the full paper …
Yeah, I know… probably way too much work 😛
The script generates a table with the summary from each paper and I go through the summaries, find the ones I like and the table also has a link to the full PDF and so, if I like the summary, I go through the full paper …
Yeah, I know… probably way too much work 😛
0
0
0
Fahim Farook
repeated
repeated
Ben Hoare
BenHoare@toot.communityThis ancient goat willow is half-tree, half-octopus!
It may have been broken by a Cumbrian storm, but is still very much alive - and supporting lots of other life too. One of my favourite trees 💚
#ThickTrunkTuesday #nature #woodland #environment #Mosstodon #Cumbria #LakeDistrict



 1
4
0
1
4
0
Fahim Farook
f
In case anybody wants a #CoreML #StableDiffusion model that works for the new image-2-image functionality, I have published my first model (based on the StableDiffusion 2.1 base model) on HuggingFace here:
https://huggingface.co/FahimF/StableDiffusion-2.1_512_EINSUM_img2img
I’ve been creating a bunch of models which support image-2-image but it’ll take a while before I’m ready to upload all of them 🙂
#Model #StabelDiffusion #CoreML #img2img
https://huggingface.co/FahimF/StableDiffusion-2.1_512_EINSUM_img2img
I’ve been creating a bunch of models which support image-2-image but it’ll take a while before I’m ready to upload all of them 🙂
#Model #StabelDiffusion #CoreML #img2img
1
0
1
Fahim Farook
f
Now that I’ve got my new #CoreML #StableDiffusion GUI working, I wanted to test the new img2img functionality. That’s when I discovered that none of the existing models worked for img2img … well at least not the ones I could find 😛
Incidentally, if you search HuggingFace for “coreml img2img” you will find a bunch of models which are supposed to work. But for whatever reason, those didn’t work for me. Maybe they were created before the latest changes to the Apple CoreML code?
Either way, I ended up spending the afternoon trying to generate new models which would work for img2img.
My first try was to go with Guernika (https://huggingface.co/Guernika/CoreMLStableDiffusion) since that has worked for me in the past. It has an option to create the Encoder that I needed, but unfortunately, that didn’t work.
I then spent some time trying a lot of things with the Apple Python code before I finally got it to work. So in case you are stuck in the same place, here are the important things to remember:
1. You need to use Python 3.8. This is very important. Other Python versions do not seem to work and result in errors.
2. I saw a note about also needing Ventura 13.1 or higher and this probably is correct since I know Apple added some changes to make StableDiffusion to work in Ventura 13.1 … but since I am on Ventura 13.2.1, I can’t verify this one for sure.
Once I did #1, the Apple Python code for generating models worked so much better. Their documentation is still a bit confusing and all over the place, but I was finally able to convert existing CKPT models to CoreML and be able to use them with img2img. So now I’m going to be doing a lot of conversions I guess? 🙂
Incidentally, if you search HuggingFace for “coreml img2img” you will find a bunch of models which are supposed to work. But for whatever reason, those didn’t work for me. Maybe they were created before the latest changes to the Apple CoreML code?
Either way, I ended up spending the afternoon trying to generate new models which would work for img2img.
My first try was to go with Guernika (https://huggingface.co/Guernika/CoreMLStableDiffusion) since that has worked for me in the past. It has an option to create the Encoder that I needed, but unfortunately, that didn’t work.
I then spent some time trying a lot of things with the Apple Python code before I finally got it to work. So in case you are stuck in the same place, here are the important things to remember:
1. You need to use Python 3.8. This is very important. Other Python versions do not seem to work and result in errors.
2. I saw a note about also needing Ventura 13.1 or higher and this probably is correct since I know Apple added some changes to make StableDiffusion to work in Ventura 13.1 … but since I am on Ventura 13.2.1, I can’t verify this one for sure.
Once I did #1, the Apple Python code for generating models worked so much better. Their documentation is still a bit confusing and all over the place, but I was finally able to convert existing CKPT models to CoreML and be able to use them with img2img. So now I’m going to be doing a lot of conversions I guess? 🙂
0
1
2
Fahim Farook
repeated
repeated

Fahim Farook
repeated
repeated
Rudy Rucker
rudytheelder@sfba.socialInvasion of the oak people. Hitched a ride on the pseudo-balloons (not actually) from China.
 0
2
0
0
2
0
Fahim Farook
repeated
repeated
LadyFluffyOrca
weaniejeanie53@mas.to
This is an ornate spiny lobster (Panulirus ornatus). Apparently this is what it takes to impress the girls in lobster world.... Works for me.
 9
3
0
9
3
0
Fahim Farook
f
@AngelaPreston 🙂 It’s based on a new model which combines OpenJourney (which is an attempt on the StableDiffusion side to get the MidJourney aesthetic …) and something else which, if I recall correctly, was also supposed to give great visuals. Not quite sure it’s up to MidJourney levels, but the visuals did improve from the bland stuff I was getting earlier for “I Shall Wear Midnight” with the standard StableDiffusion model …
0
0
1
Fahim Farook
repeated
repeated
Fox Moxin
CamWeck@mastodon.socialAnd I've been let go.
So uh.
Anyone in Philly Hiring a Data Analyst, let me know.
1
2
0
Fahim Farook
f
Now that I've got a working workflow for StableDiffusion image generation again, I can finally get back to the long neglected #DiscWorld novel title series ...
Yesterday's prompt was: "I Shall Wear Midnight"
Not much DiscWorld-iness in the images, but they all were suitably dark to represent midnight, I guess 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…




Yesterday's prompt was: "I Shall Wear Midnight"
Not much DiscWorld-iness in the images, but they all were suitably dark to represent midnight, I guess 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
1
2
6
Fahim Farook
f
And that’s the end of another day of paper reading — some really interesting (to me at least) stuff today but only 7 papers in the cs.CV category (and one outside) boosted from a total of 97 papers on arXiv.org today …
#AI #CV #NewPapers #DeepLearning #MachineLearning
#AI #CV #NewPapers #DeepLearning #MachineLearning
0
1
0
Fahim Farook
f
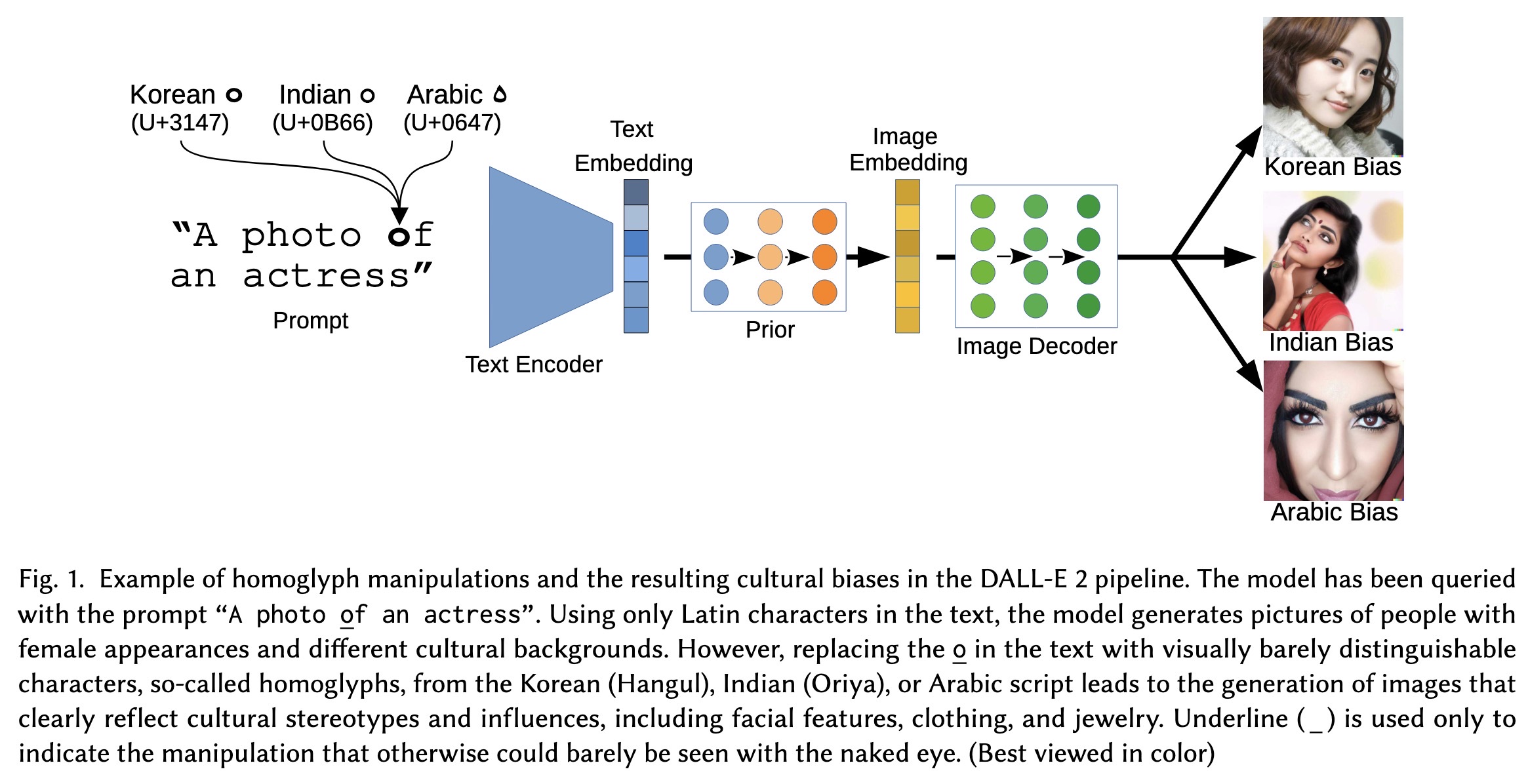
"Exploiting Cultural Biases via Homoglyphs in Text-to-Image Synthesis. (arXiv:2209.08891v2 [cs.CV] UPDATED)" — An interesting look at how replacing Latin characters with non-Latin (visual) equivalents, generative models reflect cultural stereotypes and biases in their generated images.
Paper: http://arxiv.org/abs/2209.08891
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of homoglyph manipulati…
Paper: http://arxiv.org/abs/2209.08891
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of homoglyph manipulati…
0
1
0
Fahim Farook
f
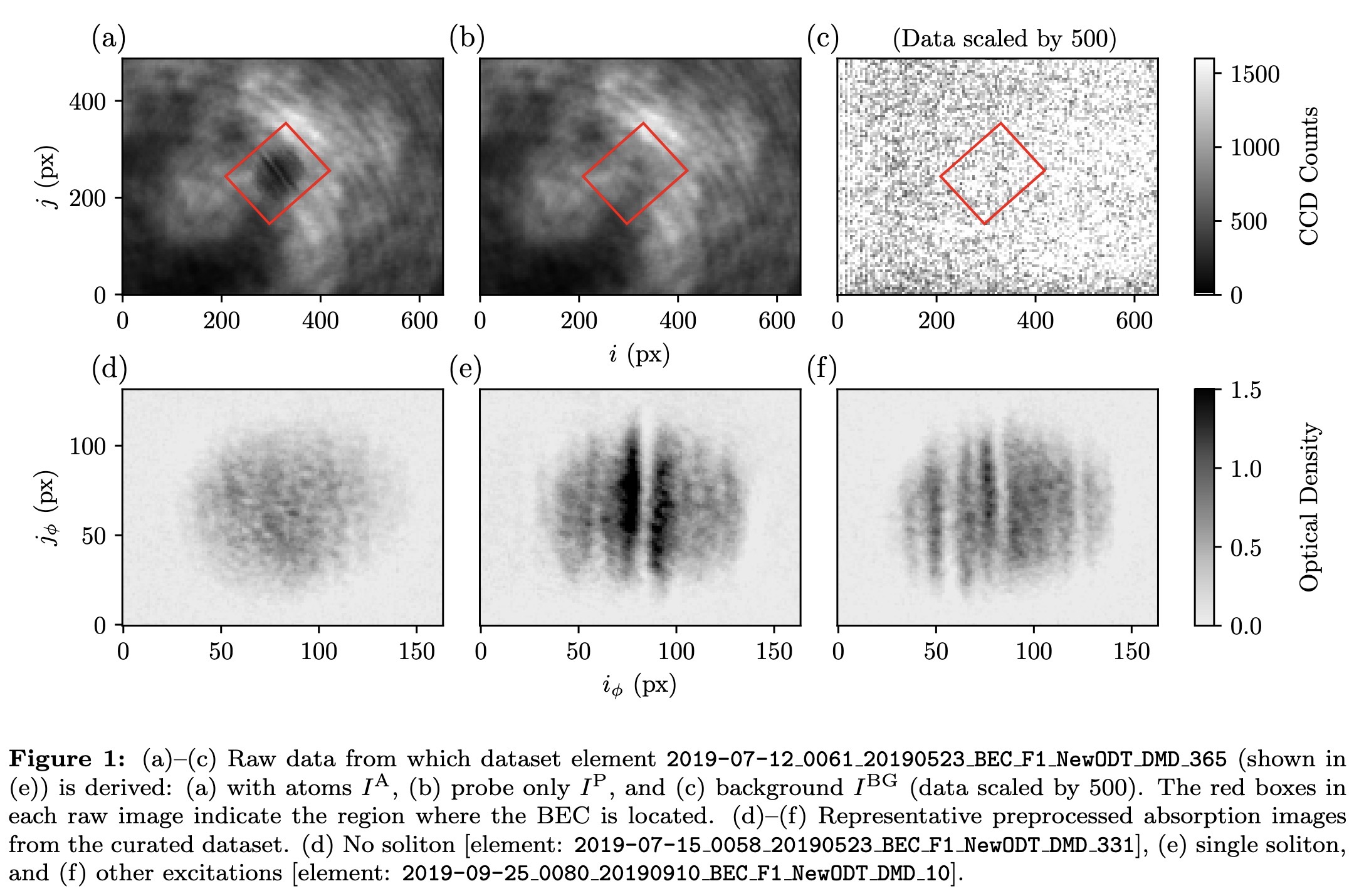
"Dark solitons in Bose-Einstein condensates: a dataset for many-body physics research. (arXiv:2205.09114v2 [cond-mat.quant-gas] UPDATED)" — A dataset of over 1.6×10⁴ experimental images of Bose-Einstein condensates containing solitonic excitations to enable machine learning (ML) for many-body physics research.
Paper: http://arxiv.org/abs/2205.09114
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a)–(c) Raw data from which dat…
Paper: http://arxiv.org/abs/2205.09114
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a)–(c) Raw data from which dat…
0
0
1
Fahim Farook
f
"I²SB: Image-to-Image Schrödinger Bridge. (arXiv:2302.05872v1 [cs.CV])" — A new class of conditional diffusion models that directly learn the nonlinear diffusion processes between two given distributions.
Paper: http://arxiv.org/abs/2302.05872
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outputs of our proposed Image-t…

Paper: http://arxiv.org/abs/2302.05872
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outputs of our proposed Image-t…
0
3
2
Fahim Farook
f
"Heckerthoughts" — A manuscript going through the basic concepts central to AI and Machine Learning where the author claims that some concepts he included are missing from modern ML courses. Conversational style, anecdotal, and not too long at 54 pages. Worth reading …
Paper: https://arxiv.org/abs/2302.05449
#AI #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The “burst” of emails that prom…

Paper: https://arxiv.org/abs/2302.05449
#AI #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The “burst” of emails that prom…
0
4
1
Fahim Farook
f
"Stochastic Surprisal: An inferential measurement of Free Energy in Neural Networks. (arXiv:2302.05776v1 [cs.LG])" — A framework that allows for action during inference in supervised neural networks.
Paper: http://arxiv.org/abs/2302.05776
Code: https://github.com/olivesgatech/Stochastic-Surprisal
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Stochastic surprisal answers co…

Paper: http://arxiv.org/abs/2302.05776
Code: https://github.com/olivesgatech/Stochastic-Surprisal
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Stochastic surprisal answers co…
0
1
1
Fahim Farook
f
"Adding Conditional Control to Text-to-Image Diffusion Models. (arXiv:2302.05543v1 [cs.CV])" — A method to control pretrained large diffusion models to support additional input conditions which can be used to augment existing generative models such as StableDiffusion by enabling conditional inputs like edge maps, segmentation maps, keypoints, etc.
Paper: http://arxiv.org/abs/2302.05543
Code: https://github.com/lllyasviel/ControlNet
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Control Stable Diffusion with C…

Paper: http://arxiv.org/abs/2302.05543
Code: https://github.com/lllyasviel/ControlNet
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Control Stable Diffusion with C…
0
2
0
Fahim Farook
f
"MaskSketch: Unpaired Structure-guided Masked Image Generation. (arXiv:2302.05496v1 [cs.CV])" — An image generation method that uses a guiding sketch to generate realistic images that match the structure of the sketch.
Paper: http://arxiv.org/abs/2302.05496
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given an input sketch and its c…

Paper: http://arxiv.org/abs/2302.05496
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given an input sketch and its c…
0
1
0
Fahim Farook
f
"Element-Wise Attention Layers: an option for optimization. (arXiv:2302.05488v1 [cs.LG])" — A new method of attention mechanism which uses matrices multiplications and has shown 92% accuracy and a 97% reduction in parameters for the Fashion MNIST dataset.
Paper: http://arxiv.org/abs/2302.05488
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The outputs of the attention mo…

Paper: http://arxiv.org/abs/2302.05488
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The outputs of the attention mo…
0
1
0