Fahim Farook
Posts
1639Following
139Followers
885I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"Scaling up GANs for Text-to-Image Synthesis. (arXiv:2303.05511v1 [cs.CV])" — Adapting the GAN architecture for generating images via text prompts to work with large datasets, offering faster generation times and higher resolutions.
Paper: http://arxiv.org/abs/2303.05511
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Some sample images generated by…

Paper: http://arxiv.org/abs/2303.05511
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Some sample images generated by…
 0
0
 1
1
 1
1
Fahim Farook
f
"Mark My Words: Dangers of Watermarked Images in ImageNet. (arXiv:2303.05498v1 [cs.LG])" — A look at the potential risks of watermarked images present in
ImageNet and their impact on popular Deep Neural Networks (DNN) trained on this dataset.
Paper: http://arxiv.org/abs/2303.05498
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multiple images with watermarks…

ImageNet and their impact on popular Deep Neural Networks (DNN) trained on this dataset.
Paper: http://arxiv.org/abs/2303.05498
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multiple images with watermarks…
0
0
0
Fahim Farook
f
"3DGen: Triplane Latent Diffusion for Textured Mesh Generation. (arXiv:2303.05371v1 [cs.CV])" — Generating 3D meshes using diffusion models.
Paper: http://arxiv.org/abs/2303.05371
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Single category unconditional m…

Paper: http://arxiv.org/abs/2303.05371
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Single category unconditional m…
0
1
2
Fahim Farook
f
"BaDLAD: A Large Multi-Domain Bengali Document Layout Analysis Dataset. (arXiv:2303.05325v1 [cs.CV])" — A dataset to help with Bengali document layout analysis, containing 33,695 human annotated document samples from six domains.
Paper: http://arxiv.org/abs/2303.05325
Code: https://github.com/anon-user-for-web/badlad
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A sample of the different layou…

Paper: http://arxiv.org/abs/2303.05325
Code: https://github.com/anon-user-for-web/badlad
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A sample of the different layou…
0
0
0
Fahim Farook
f
"Detecting Images Generated by Diffusers. (arXiv:2303.05275v1 [cs.CV])" — Detecting if given images were generated by diffusion models or not. Appears to be limited to detecting images only if images generated by a particular diffusion model were in the training set.
Paper: http://arxiv.org/abs/2303.05275
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The two different network setup…
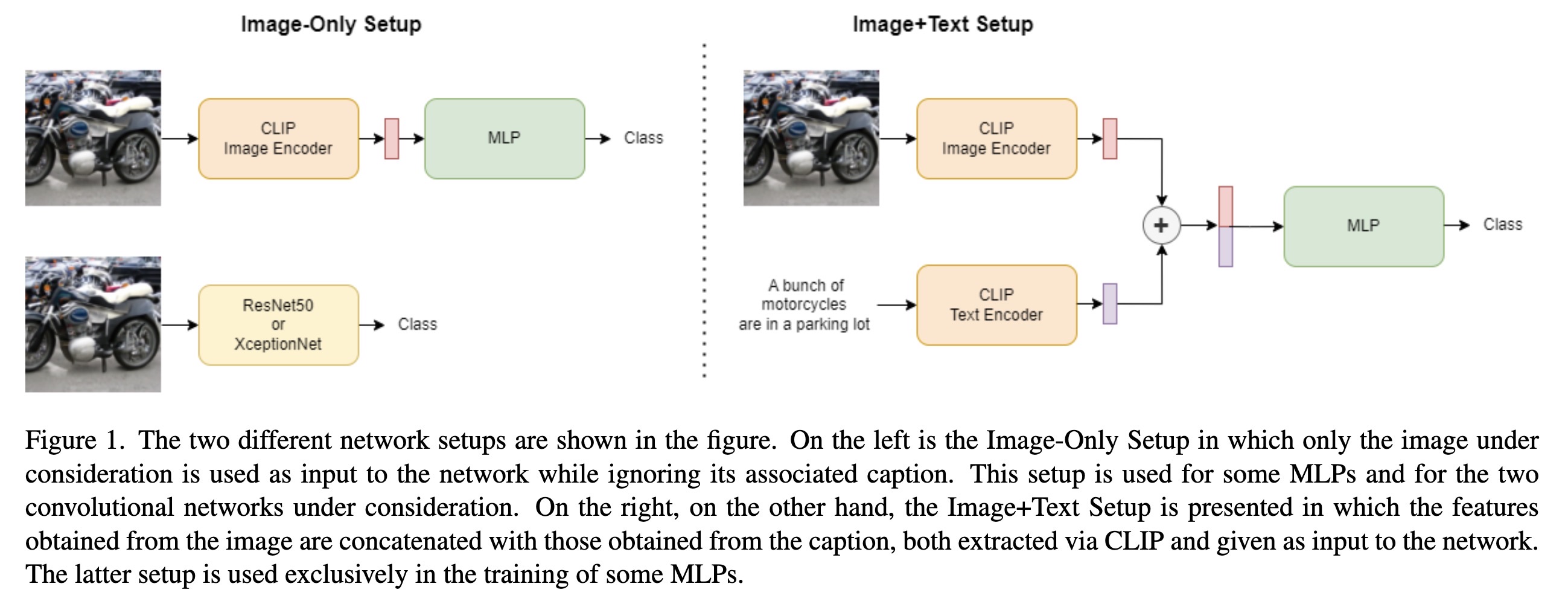
Paper: http://arxiv.org/abs/2303.05275
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The two different network setup…
0
0
0
Fahim Farook
f
"O2RNet: Occluder-Occludee Relational Network for Robust Apple Detection in Clustered Orchard Environments. (arXiv:2303.04884v1 [cs.CV])" — Using deep learning to detect apples in orchards for harvesting.
Paper: http://arxiv.org/abs/2303.04884
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Six sample images from the coll…

Paper: http://arxiv.org/abs/2303.04884
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Six sample images from the coll…
0
0
1
Fahim Farook
f
"Interactive Cartoonization with Controllable Perceptual Factors. (arXiv:2212.09555v2 [cs.CV] UPDATED)" — A model capable of converting input images to cartoons where you have the ability to control the texture and color of the final image.
Paper: http://arxiv.org/abs/2212.09555
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of the background makin…

Paper: http://arxiv.org/abs/2212.09555
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of the background makin…
0
0
1
Fahim Farook
f
"Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models. (arXiv:2303.04671v1 [cs.CV])" — An amalgamation of ChatGPT and image generation models such as Stable Diffusion to allow providing ChatGPT with not just text input but also images and to be able to provide visual questions or image editing instructions to ChatGPT.
Paper: http://arxiv.org/abs/2303.04671
No repo exists on GitHub matching the one linked in the paper.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of Visual ChatGPT. The…
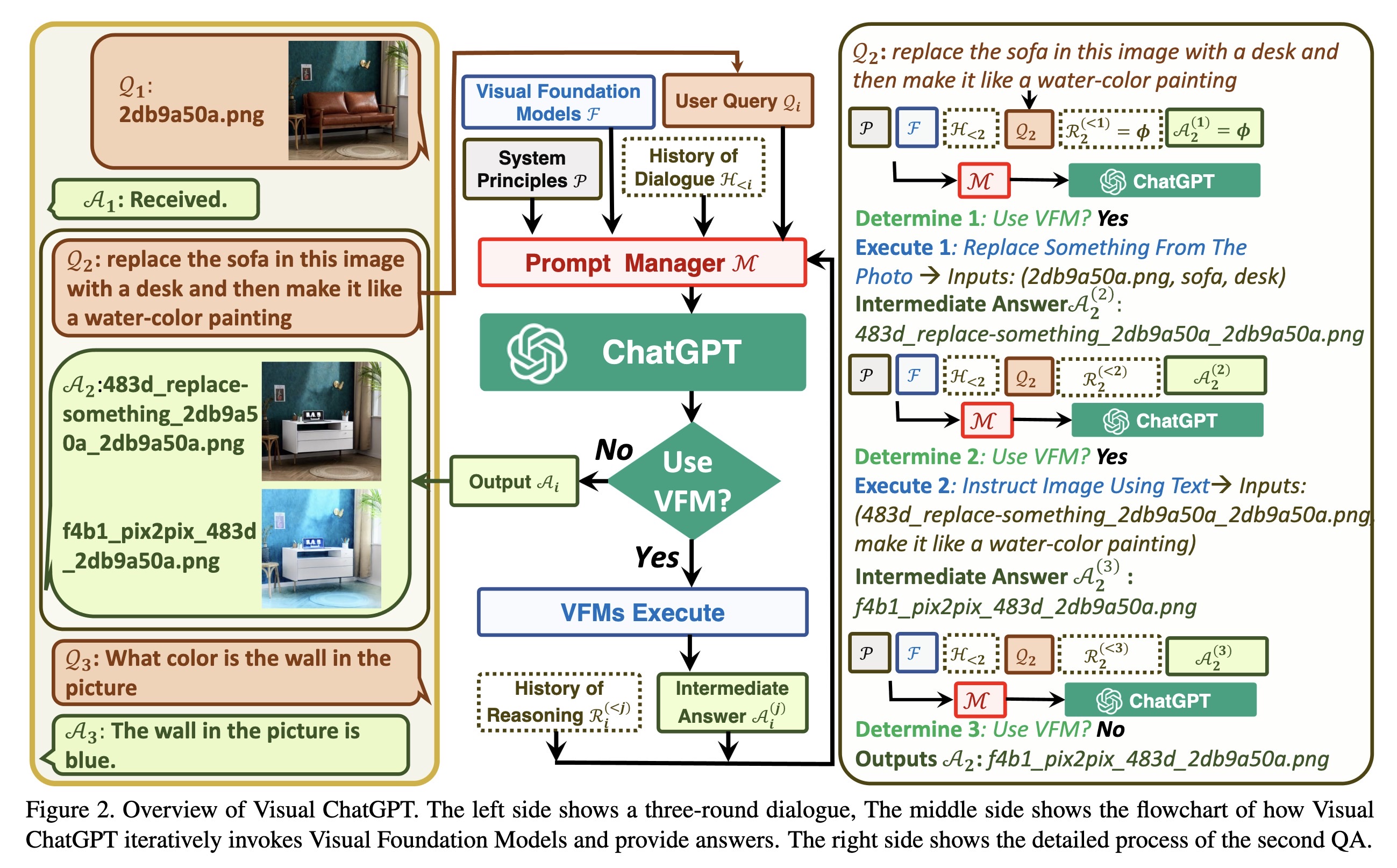
Paper: http://arxiv.org/abs/2303.04671
No repo exists on GitHub matching the one linked in the paper.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of Visual ChatGPT. The…
0
2
2
Fahim Farook
f
"A Prompt Log Analysis of Text-to-Image Generation Systems. (arXiv:2303.04587v1 [cs.HC])" — Analyzing prompts used with diffusion models to get an idea of the informational needs of the users and to get an idea as to how to improve text-to-image generation systems.
Paper: http://arxiv.org/abs/2303.04587
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two tables showing most frequen…
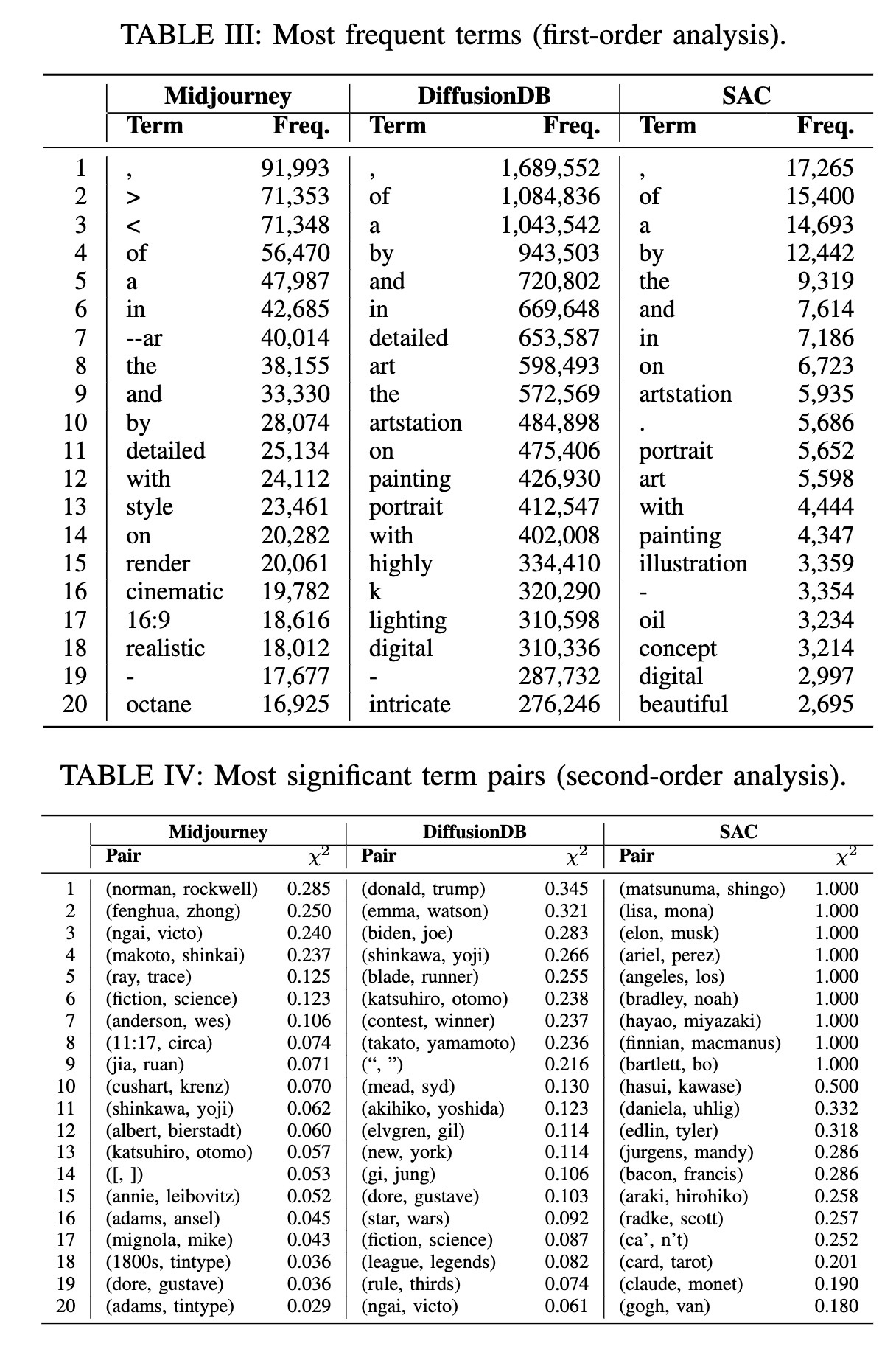
Paper: http://arxiv.org/abs/2303.04587
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two tables showing most frequen…
0
0
0
Fahim Farook
f
"Diffusion in the Dark: A Diffusion Model for Low-Light Text Recognition. (arXiv:2303.04291v1 [eess.IV])" — Recognizing text in images taken under low-light conditions while preserving high-frequency details in the image.
Paper: http://arxiv.org/abs/2303.04291
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Low-light image reconstruction …

Paper: http://arxiv.org/abs/2303.04291
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Low-light image reconstruction …
0
0
1
Fahim Farook
f
"EscherNet 101. (arXiv:2303.04208v1 [cs.CV])" — Teaching an artificial neural network symmetry groups and their relations as found in M. C. Escher drawings and other similar artwork.
Paper: http://arxiv.org/abs/2303.04208
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(A) Three drawings by M.C. Esch…
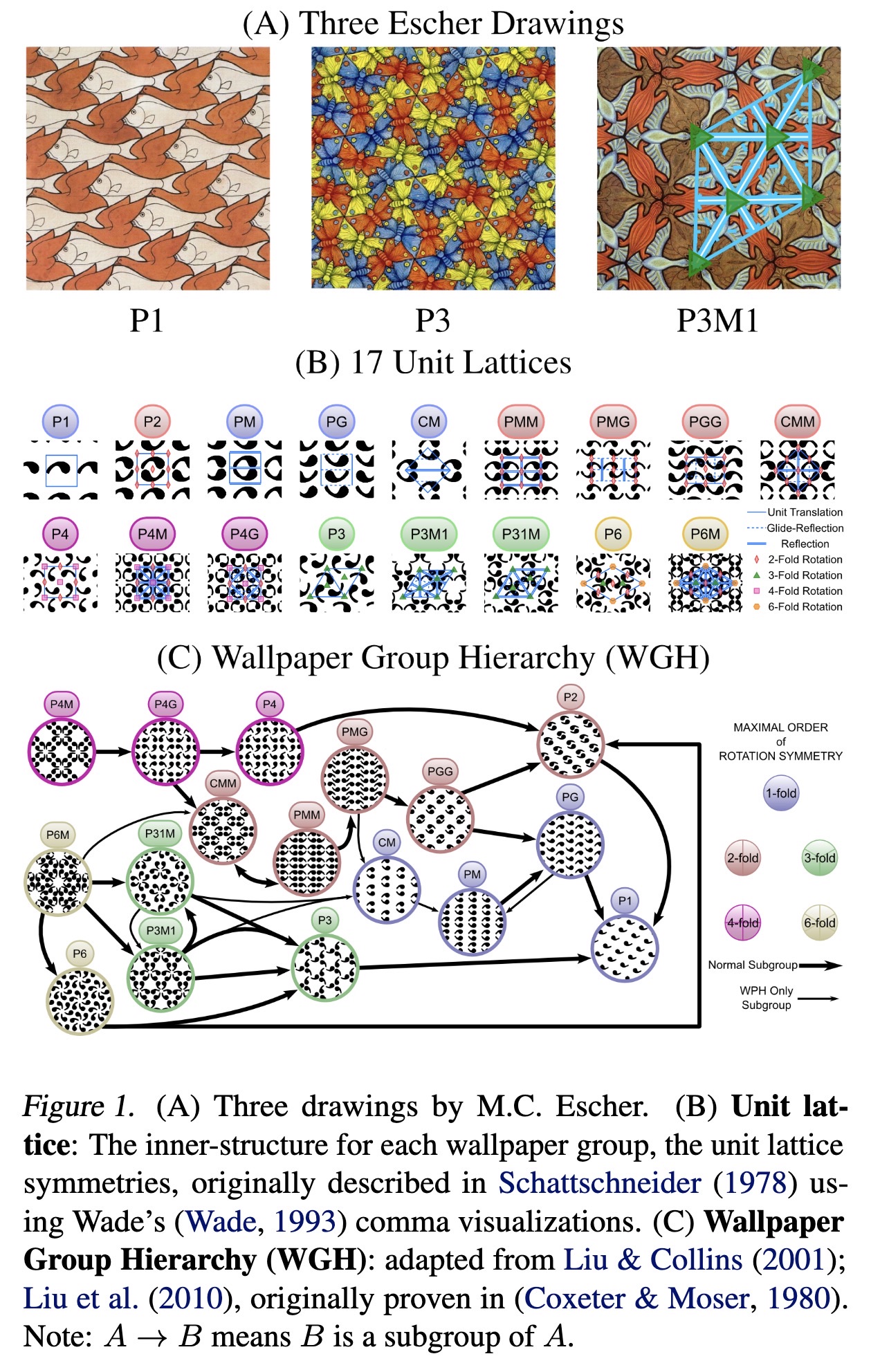
Paper: http://arxiv.org/abs/2303.04208
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(A) Three drawings by M.C. Esch…
0
1
1
Fahim Farook
f
"Neural Style Transfer for Vector Graphics. (arXiv:2303.03405v1 [cs.CV])" — Transferring style from an input style image to an source vector image to create a target vector image that adheres to the style of the input style image.
Paper: http://arxiv.org/abs/2303.03405
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We propose a novel neural style…

Paper: http://arxiv.org/abs/2303.03405
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
We propose a novel neural style…
0
0
0
Fahim Farook
f
"DLT: Conditioned layout generation with Joint Discrete-Continuous Diffusion Layout Transformer. (arXiv:2303.03755v1 [cs.CV])" — Using diffusion models to create visual layouts as part of graphics design.
Paper: http://arxiv.org/abs/2303.03755
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of our Joint Discrete-…
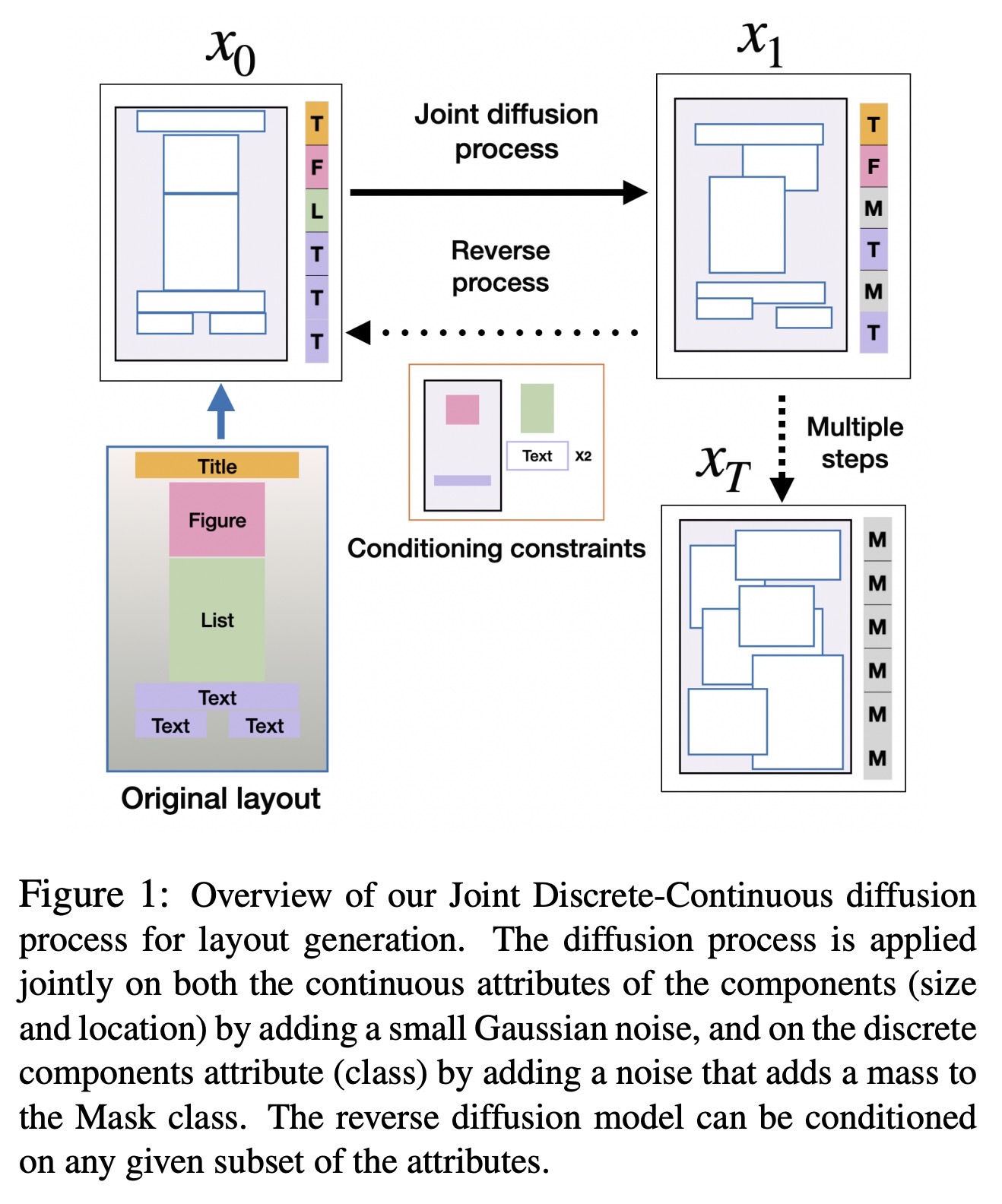
Paper: http://arxiv.org/abs/2303.03755
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of our Joint Discrete-…
0
2
2
Fahim Farook
f
"Extended Agriculture-Vision: An Extension of a Large Aerial Image Dataset for Agricultural Pattern Analysis. (arXiv:2303.02460v1 [cs.CV])" — What it says in the title, an improved dataset for agricultural pattern analysis.
Paper: http://arxiv.org/abs/2303.02460
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: Full-field imagery (RGB-o…

Paper: http://arxiv.org/abs/2303.02460
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Left: Full-field imagery (RGB-o…
0
2
0
Fahim Farook
f
"Diffusion Models Generate Images Like Painters: an Analytical Theory of Outline First, Details Later. (arXiv:2303.02490v1 [cs.CV])" — An exploration of the the theory that diffusion models generate images like painters creating a painting: that it involves first committing to an outline, and then adding in finer details.
Paper: http://arxiv.org/abs/2303.02490
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Characteristics of image genera…

Paper: http://arxiv.org/abs/2303.02490
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Characteristics of image genera…
0
3
2
Fahim Farook
f
"All are Worth Words: A ViT Backbone for Diffusion Models. (arXiv:2209.12152v3 [cs.CV] UPDATED)" — A simple and general ViT-based architecture for image generation with diffusion models which is capable of unconditional and class-conditional image generation, as well as text-to-image generation tasks.
Paper: http://arxiv.org/abs/2209.12152
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Text-to-image generation on MS-…

Paper: http://arxiv.org/abs/2209.12152
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Text-to-image generation on MS-…
0
0
0
Fahim Farook
f
A little bit more on the Edge browser and all the interesting activities it has built-in …
It has this little page of activities that you can try. One of them was to solve a tile puzzle — an image split into tiles and mixed up that you have to arrange corectly.
Once you complete the image, you get more information about the image and hotspots on the image you can click to get more information. If you click on a hotspot, you are taken to a Bing page with photos, relevant links, and a sidebar with additional links that you can explore.
As somebody who loves learning esoteric things, this just feels like the first time I discovered an encyclopaedia, but a lot more fun 🙂
#Edge #Browser #Gamification #Bing
An image of a tile/card which s…
A beautiful image of a bay with…
A Bing page with information ab…
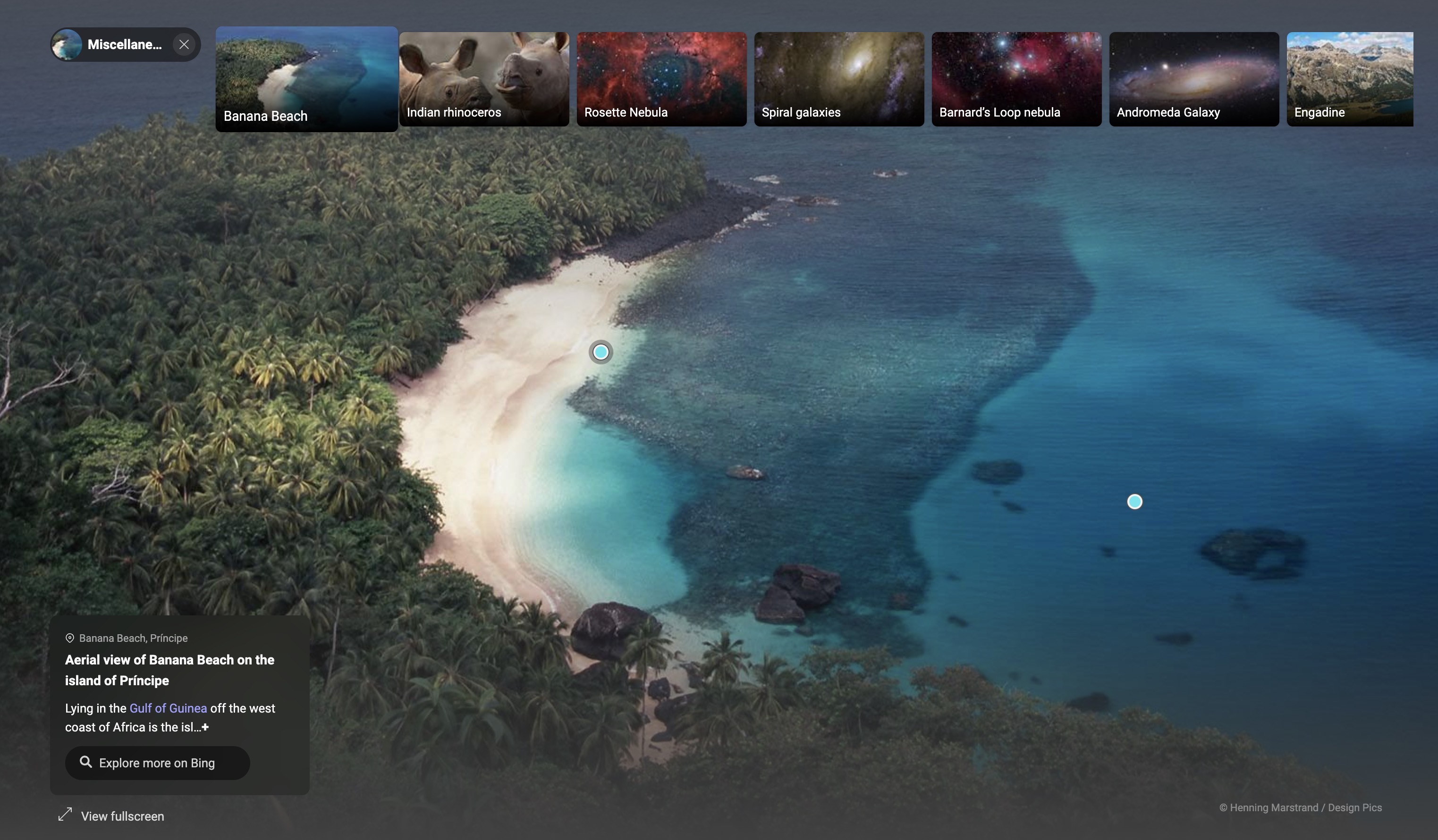
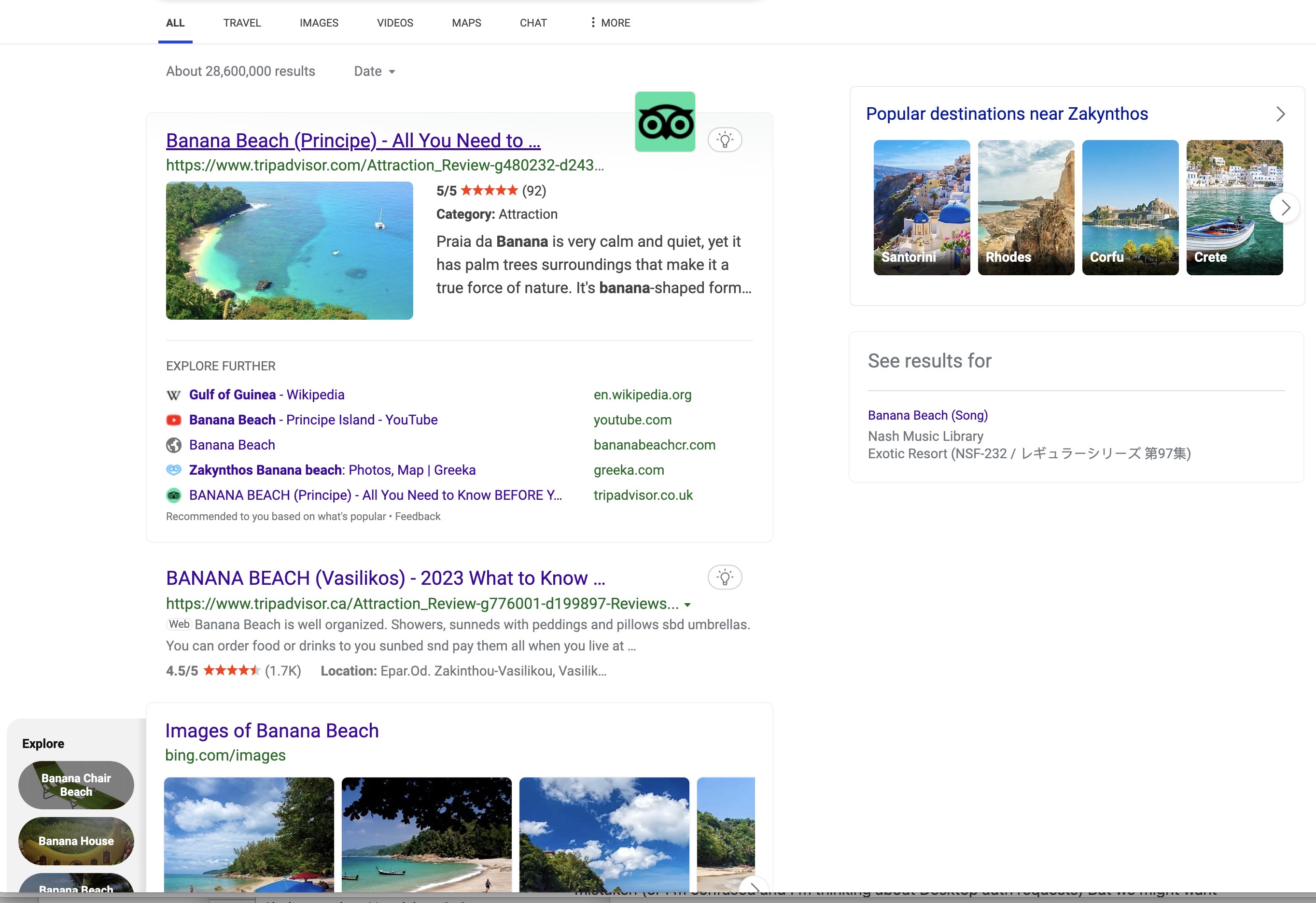
It has this little page of activities that you can try. One of them was to solve a tile puzzle — an image split into tiles and mixed up that you have to arrange corectly.
Once you complete the image, you get more information about the image and hotspots on the image you can click to get more information. If you click on a hotspot, you are taken to a Bing page with photos, relevant links, and a sidebar with additional links that you can explore.
As somebody who loves learning esoteric things, this just feels like the first time I discovered an encyclopaedia, but a lot more fun 🙂
#Edge #Browser #Gamification #Bing
An image of a tile/card which s…
A beautiful image of a bay with…
A Bing page with information ab…
0
1
1
Fahim Farook
f
"Defending against Adversarial Audio via Diffusion Model" — Using diffusion models to purify/remove adversarial audio which can cause abnormal behaviour in acoustic systems.
Paper: https://arxiv.org/abs/2303.01507
Code: https://github.com/cychomatica/AudioPure
#AI #NewPaper #DeepLearning #MachineLearning #Sound #Security #Audio #Cryptograpy
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of the whole a…
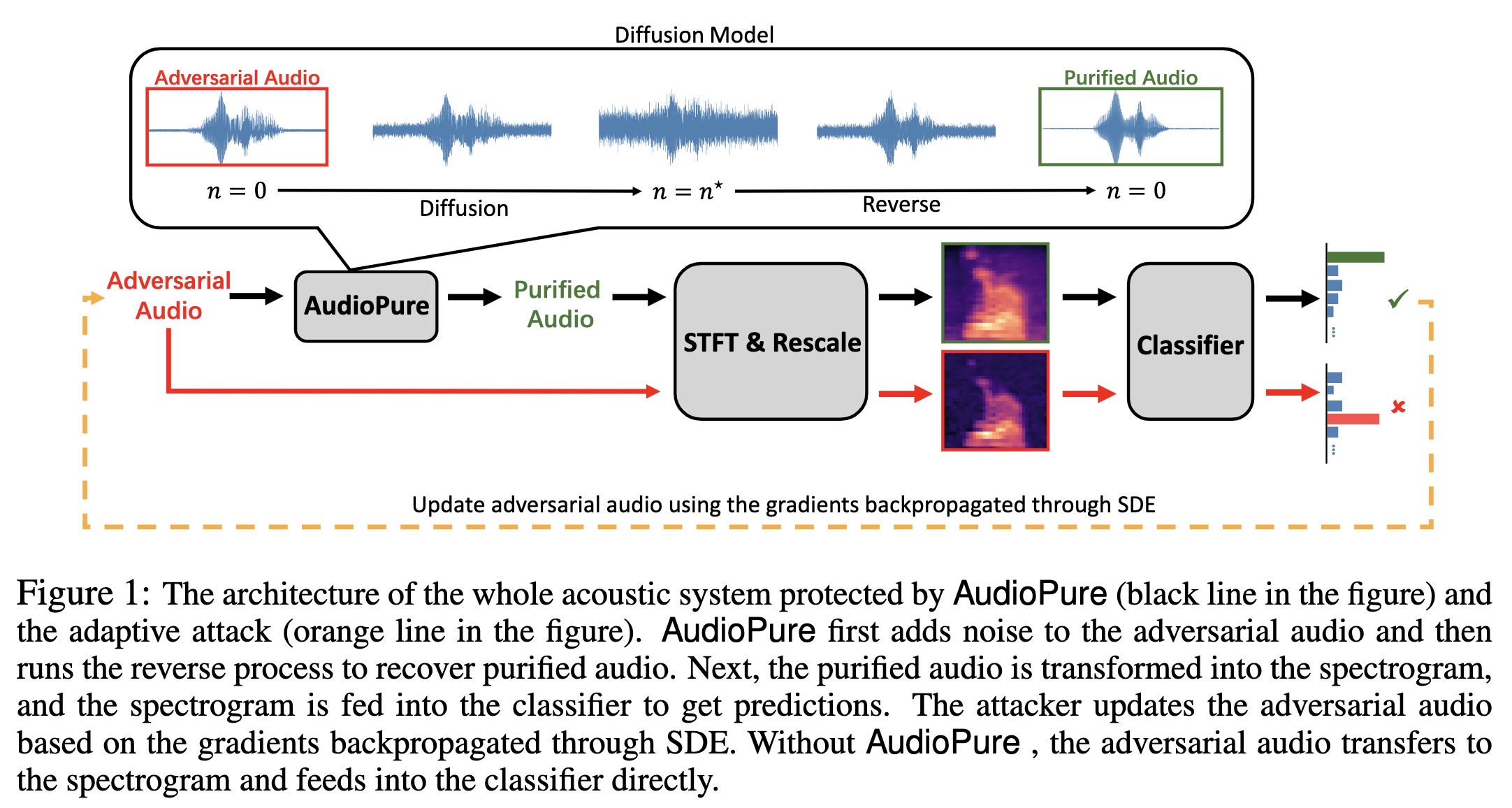
Paper: https://arxiv.org/abs/2303.01507
Code: https://github.com/cychomatica/AudioPure
#AI #NewPaper #DeepLearning #MachineLearning #Sound #Security #Audio #Cryptograpy
<<Find this useful? Please boost so that others can benefit too 🙂>>
The architecture of the whole a…
0
0
0
Fahim Farook
f
"Word-As-Image for Semantic Typography. (arXiv:2303.01818v1 [cs.CV])" — Automatically visualizing words by modifying the typography to depict the meaning/representation of the word.
Paper: http://arxiv.org/abs/2303.01818
Note: No code or demo available (yet) at the linked locations.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A few examples of our word-as-i…

Paper: http://arxiv.org/abs/2303.01818
Note: No code or demo available (yet) at the linked locations.
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A few examples of our word-as-i…
0
3
1
Fahim Farook
f
"Unleashing Text-to-Image Diffusion Models for Visual Perception. (arXiv:2303.02153v1 [cs.CV])" — Using the pre-trained autoencoder in a diffusion model for visual perception tasks such as segmentation or depth estimation.
Paper: http://arxiv.org/abs/2303.02153
Code: https://github.com/wl-zhao/VPD
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The main idea of the proposed V…

Paper: http://arxiv.org/abs/2303.02153
Code: https://github.com/wl-zhao/VPD
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The main idea of the proposed V…
0
2
0