Fahim Farook
Posts
1635Following
138Followers
881I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"Region-Aware Diffusion for Zero-shot Text-driven Image Editing. (arXiv:2302.11797v1 [cs.CV])" — A region-aware text-guided image editing method which aims to replace one entity with another.
What I always wonder with these approaches is whether you can replace a larger entity with a smaller one, or vice versa, (say a horse with a cat) in a way that looks realistic?
Paper: http://arxiv.org/abs/2302.11797
Code: https://github.com/haha-lisa/RDM-Region-Aware-Diffusion-Model
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The results of the proposed reg…

What I always wonder with these approaches is whether you can replace a larger entity with a smaller one, or vice versa, (say a horse with a cat) in a way that looks realistic?
Paper: http://arxiv.org/abs/2302.11797
Code: https://github.com/haha-lisa/RDM-Region-Aware-Diffusion-Model
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The results of the proposed reg…
 0
0
 0
0
 0
0
Fahim Farook
f
"Controlled and Conditional Text to Image Generation with Diffusion Prior. (arXiv:2302.11710v1 [cs.CV])" — Using a Diffusion Prior to constrain the generation to a specific domain without altering the larger Diffusion Decoder in a memory and compute efficient way.
Paper: http://arxiv.org/abs/2302.11710
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion Prior can be trained …

Paper: http://arxiv.org/abs/2302.11710
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Diffusion Prior can be trained …
0
0
0
Fahim Farook
f
"Composer: Creative and Controllable Image Synthesis with Composable Conditions. (arXiv:2302.09778v2 [cs.CV] UPDATED)" — A way to flexibly control the output image from diffusion models to modify the layout or style of the final image.
Paper: http://arxiv.org/abs/2302.09778
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of compositional image …

Paper: http://arxiv.org/abs/2302.09778
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Concept of compositional image …
0
0
0
Fahim Farook
f
"Entity-Level Text-Guided Image Manipulation. (arXiv:2302.11383v1 [cs.CV])" — A more accurate/efficient text-guided image editing/manipulation?
Paper: http://arxiv.org/abs/2302.11383
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison between our method a…

Paper: http://arxiv.org/abs/2302.11383
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Comparison between our method a…
0
0
1
Fahim Farook
f
"Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities. (arXiv:2302.11154v1 [cs.CV])" — Creating a non-task/domain specific, general visual recognition model.
Paper: http://arxiv.org/abs/2302.11154
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustration of the proposed…

Paper: http://arxiv.org/abs/2302.11154
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An illustration of the proposed…
0
0
0
Fahim Farook
f
"Teachable Reality: Prototyping Tangible Augmented Reality with Everyday Objects by Leveraging Interactive Machine Teaching. (arXiv:2302.11046v1 [cs.HC])" — An Augmented Reality (AR) prototyping tool for creating interactive AR applications using everyday objects.
Paper: http://arxiv.org/abs/2302.11046
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Teachable Reality is an augment…

Paper: http://arxiv.org/abs/2302.11046
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Teachable Reality is an augment…
0
0
0
Fahim Farook
f
"'The Taurus': Cattle Breeds & Diseases Identification Mobile Application using Machine Learning. (arXiv:2302.10920v1 [cs.LG])" — A cross-platform mobile application to identify cattle breeds, easily analyze and identify the diseases which cattle suffer from, and to provide solutions the identified diseases.
Paper: http://arxiv.org/abs/2302.10920
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Mobile app screens showing the …

Paper: http://arxiv.org/abs/2302.10920
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Mobile app screens showing the …
0
0
0
Fahim Farook
f
"Fair Diffusion: Instructing Text-to-Image Generation Models on Fairness. (arXiv:2302.10893v1 [cs.LG])" — Reducing bias in generative text-to-image models based on instructions.
Paper: http://arxiv.org/abs/2302.10893
Code: https://github.com/ml-research/Fair-Diffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Stable Diffusion (top row) runs…

Paper: http://arxiv.org/abs/2302.10893
Code: https://github.com/ml-research/Fair-Diffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Stable Diffusion (top row) runs…
0
1
1
Fahim Farook
f
Yesterday's #StableDiffusion prompt was: "Secret forest with hidden nooks" or "Fantasy forest with hidden nooks" ... I did some for each 🙂
These were done using multiple different models and different resolutions and so there's quite a range to the images.
I liked the results so much that I'll probably be doing a few more of this over the next few days ... Or, variations thereof.
Prompt: “secret forest with hid…
Prompt: “fantasy forest with hi…
Prompt: “fantasy forest with hi…
Prompt: “secret forest with hid…




These were done using multiple different models and different resolutions and so there's quite a range to the images.
I liked the results so much that I'll probably be doing a few more of this over the next few days ... Or, variations thereof.
Prompt: “secret forest with hid…
Prompt: “fantasy forest with hi…
Prompt: “fantasy forest with hi…
Prompt: “secret forest with hid…
0
5
7
Fahim Farook
f
"Learning 3D Photography Videos via Self-supervised Diffusion on Single Images. (arXiv:2302.10781v1 [cs.CV])" — Transforming static images into videos with additional effects using a diffusion model to handle the inpainting.
Paper: http://arxiv.org/abs/2302.10781
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
llustration of the proposed out…

Paper: http://arxiv.org/abs/2302.10781
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
llustration of the proposed out…
0
1
1
Fahim Farook
f
"RealFusion: 360{\deg} Reconstruction of Any Object from a Single Image. (arXiv:2302.10663v1 [cs.CV])" — Creating a 360-degree photographic model of an object from a single image of it by fitting a neural radiance field to the image.
Paper: http://arxiv.org/abs/2302.10663
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
RealFusion generates a full 360…
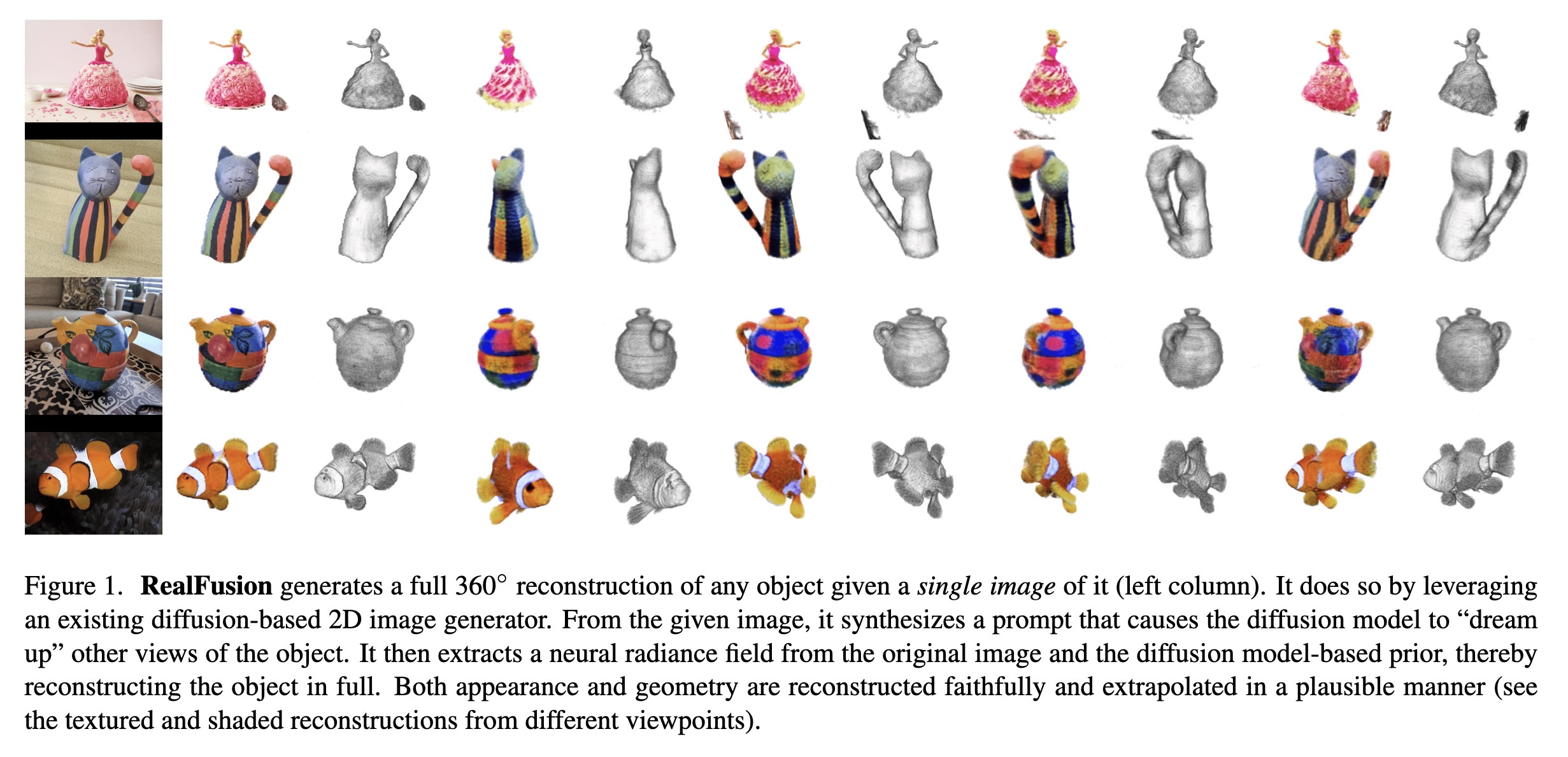
Paper: http://arxiv.org/abs/2302.10663
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
RealFusion generates a full 360…
0
4
4
Fahim Farook
f
"Diffusion Models and Semi-Supervised Learners Benefit Mutually with Few Labels. (arXiv:2302.10586v1 [cs.CV])" — A three-stage training strategy for conditional image generation and classification in semi-supervised learning.
Paper: http://arxiv.org/abs/2302.10586
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An overview of DPT. First, a (s…
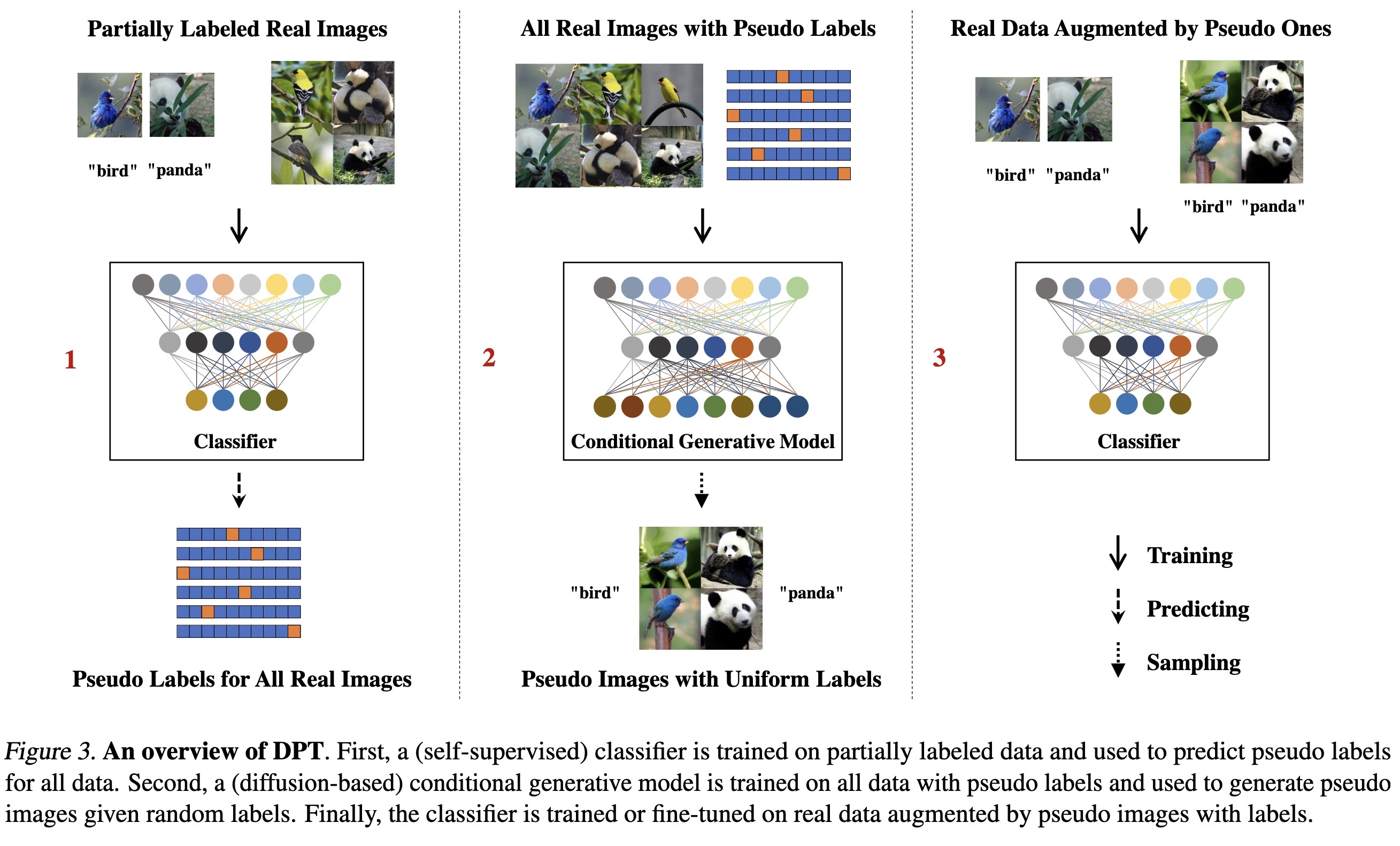
Paper: http://arxiv.org/abs/2302.10586
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An overview of DPT. First, a (s…
0
1
1
Fahim Farook
f
"A Comparative Analysis of CNN-Based Pretrained Models for the Detection and Prediction of Monkeypox. (arXiv:2302.10277v1 [cs.CV])" — Using Convolutional Neural Networks (CNN) to detect monkeypox since it's difficult to diagnose early due to its similarity to other diseases like chickenpox and measles.
Paper: http://arxiv.org/abs/2302.10277
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Chart showing confirmed monkeyp…
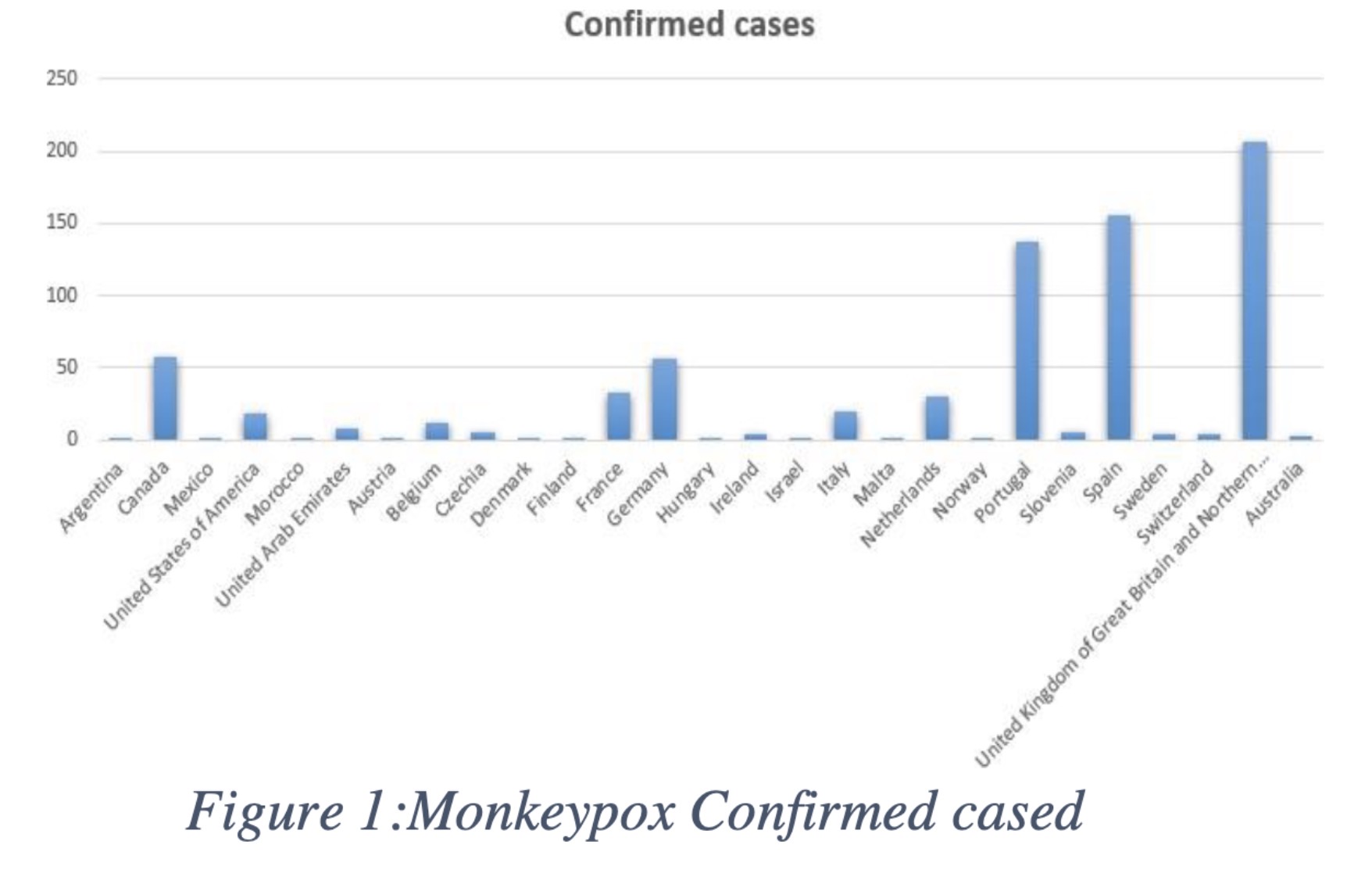
Paper: http://arxiv.org/abs/2302.10277
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Chart showing confirmed monkeyp…
0
0
1
Fahim Farook
f
I've been trying out leonardo.ai with a bunch of new prompts since yesterday.
The following are the best results for: "Burning the cradle at both ends" ... and no "cradle" wasn't a typo, that was the prompt I wanted 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …




The following are the best results for: "Burning the cradle at both ends" ... and no "cradle" wasn't a typo, that was the prompt I wanted 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
Prompt: “Burning the cradle at …
0
1
4
Fahim Farook
f
"Vulnerability analysis of captcha using Deep learning. (arXiv:2302.09389v1 [cs.CR])" — Using a Convolutional Neural Network (CNN) model to predict text-based CAPTCHAs to examine the flaws inherent in the system and to create more resilient CAPTCHAs.
Paper: http://arxiv.org/abs/2302.09389
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of different alphanume…

Paper: http://arxiv.org/abs/2302.09389
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of different alphanume…
0
1
0
Fahim Farook
f
"Exploring the Representation Manifolds of Stable Diffusion Through the Lens of Intrinsic Dimension. (arXiv:2302.09301v1 [cs.CL])" — An investigation into the basic geometric properties induced by prompts in Stable Diffusion and how this impact depends on the layer being considered.
Paper: http://arxiv.org/abs/2302.09301
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The output of the model at the …

Paper: http://arxiv.org/abs/2302.09301
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The output of the model at the …
0
1
0
Fahim Farook
f
"Web Photo Source Identification based on Neural Enhanced Camera Fingerprint. (arXiv:2302.09228v1 [cs.CV])" — Using a neural network to identify sensor patterns in an effort to identify the source camera for images published on the web.
Paper: http://arxiv.org/abs/2302.09228
Code: https://github.com/PhotoNecf/PhotoNecf
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three main stages of source ide…
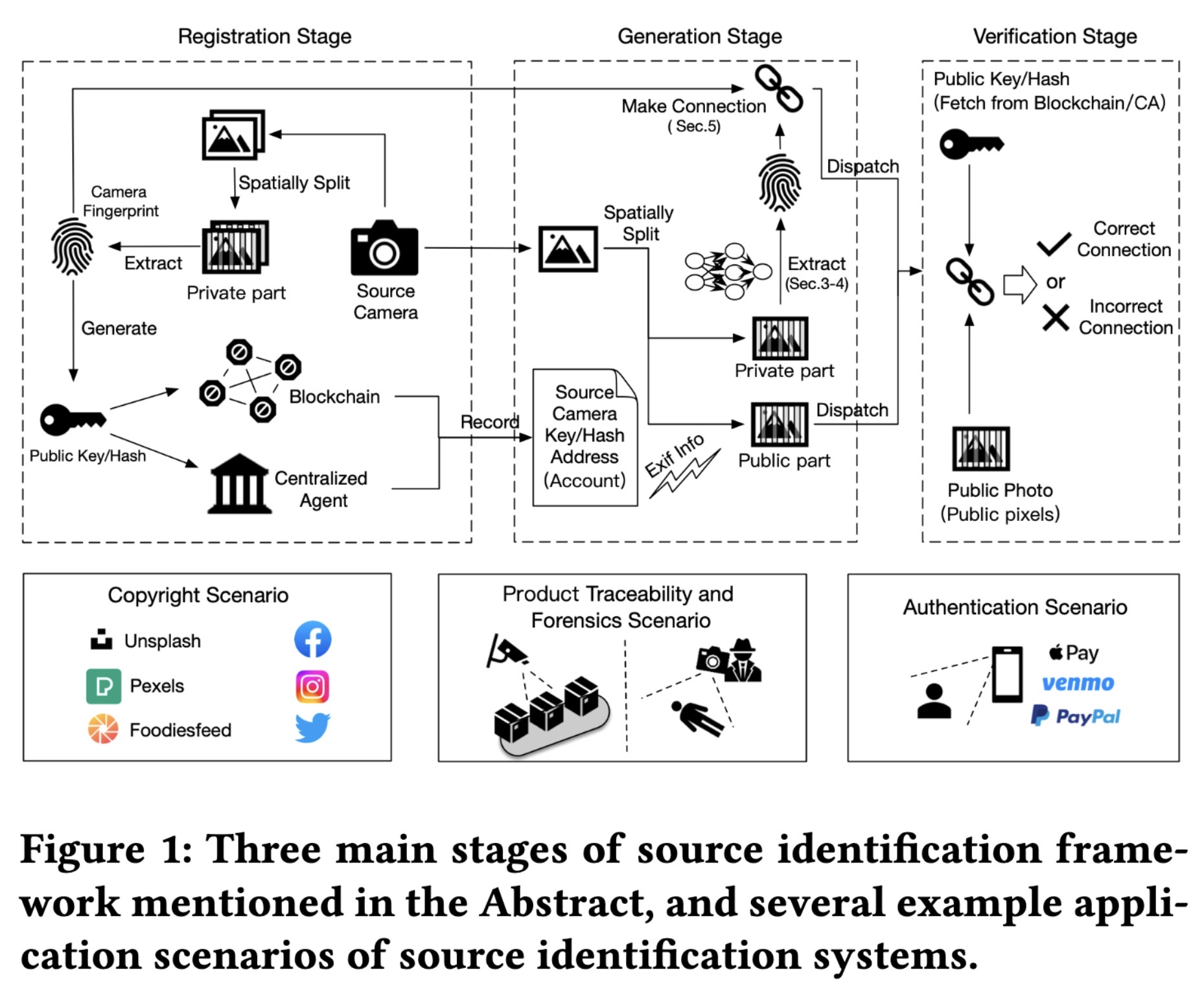
Paper: http://arxiv.org/abs/2302.09228
Code: https://github.com/PhotoNecf/PhotoNecf
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three main stages of source ide…
0
2
1
Fahim Farook
f
"A Pilot Evaluation of ChatGPT and DALL-E 2 on Decision Making and Spatial Reasoning. (arXiv:2302.09068v1 [cs.AI])" — An evaluation of ChatGPT and DALL-E2 to assess the spatial reasoning and decision making abilities of each model.
Paper: http://arxiv.org/abs/2302.09068
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
DALL-E output for the prompts: …

Paper: http://arxiv.org/abs/2302.09068
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
DALL-E output for the prompts: …
0
1
0
Fahim Farook
f
""Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction. (arXiv:2210.03735v2 [cs.HC] UPDATED)" — A study of how explainability can support human-AI interaction using a real-world AI applicaiton.
Paper: http://arxiv.org/abs/2210.03735
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Screenshots of Merlin, our stu…
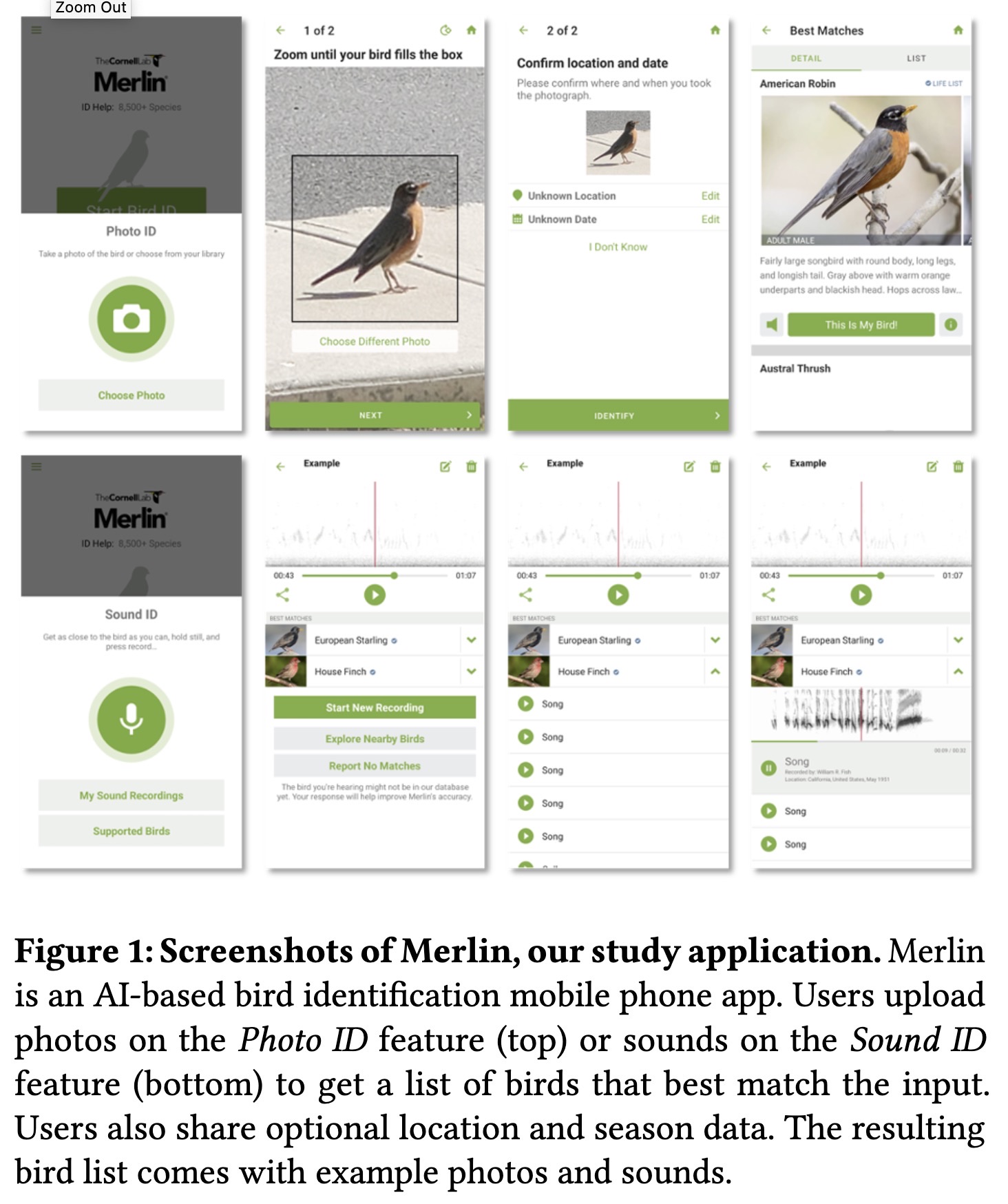
Paper: http://arxiv.org/abs/2210.03735
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Screenshots of Merlin, our stu…
0
5
4
Fahim Farook
f
"Which country is this picture from? New data and methods for DNN-based country recognition. (arXiv:2209.02429v2 [cs.CV] UPDATED)" — A framework to identify the country where an image was taken, which could be useful in debunking fake news and many other applications.
Paper: http://arxiv.org/abs/2209.02429
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three sample photos taken from …

Paper: http://arxiv.org/abs/2209.02429
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Three sample photos taken from …
0
2
0