Fahim Farook
Posts
1635Following
138Followers
881I'm currently working on my second novel which is complete, but is in the edit stage. I wrote my first novel over 20 years ago but then didn't write much till now.
I post about #Coding, #Flutter, #Writing, #Movies and #TV. I'll also talk about #Technology, #Gadgets, #MachineLearning, #DeepLearning and a few other things as the fancy strikes ...
Lived in: 🇱🇰🇸🇦🇺🇸🇳🇿🇸🇬🇲🇾🇦🇪🇫🇷🇪🇸🇵🇹🇶🇦🇨🇦
Fahim Farook
f
"Learning When to Say "I Don't Know". (arXiv:2209.04944v2 [cs.CV] UPDATED)" — A method to teach learning systems when they don't know something, or at least to identify areas of uncertainty. Perhaps this should be tried with ChatGPT and Bing to mitigate all the gaslighting? 😛
Paper: http://arxiv.org/abs/2209.04944
Code: https://github.com/osu-cvl/learning-idk
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
t-SNE plots of logits from a we…

Paper: http://arxiv.org/abs/2209.04944
Code: https://github.com/osu-cvl/learning-idk
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
t-SNE plots of logits from a we…
 0
0
 4
4
 4
4
Fahim Farook
f
"SoK: Anti-Facial Recognition Technology. (arXiv:2112.04558v2 [cs.CR] UPDATED)" — An analysis of the currently available Anti-Facial Recognition (AFR) research and the pros and cons of the different approaches.
Paper: http://arxiv.org/abs/2112.04558
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The workflow of how facial reco…
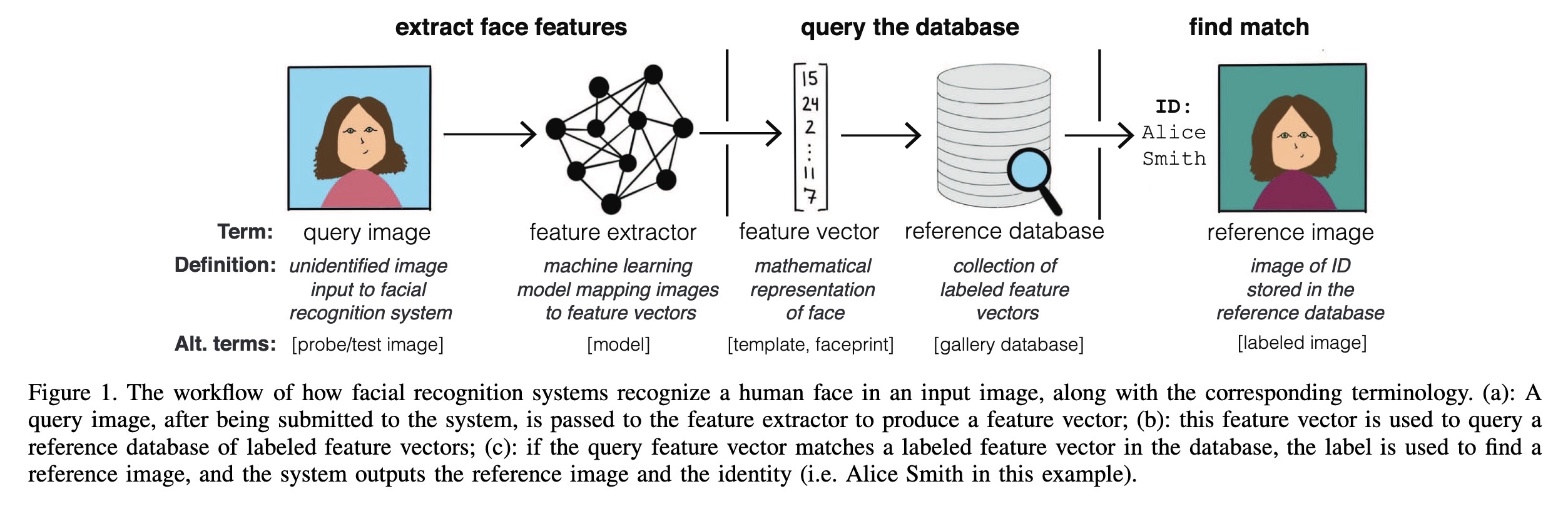
Paper: http://arxiv.org/abs/2112.04558
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The workflow of how facial reco…
0
0
0
Fahim Farook
f
"Team Triple-Check at Factify 2: Parameter-Efficient Large Foundation Models with Feature Representations for Multi-Modal Fact Verification. (arXiv:2302.07740v1 [cs.CL])" — Verifying facts across different modes (text and images) and types (claim and document).
Paper: http://arxiv.org/abs/2302.07740
Code: https://github.com/wwweiwei/Pre-CoFactv2-AAAI-2023
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An example of each category in …

Paper: http://arxiv.org/abs/2302.07740
Code: https://github.com/wwweiwei/Pre-CoFactv2-AAAI-2023
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
An example of each category in …
0
1
0
Fahim Farook
f
"Video Probabilistic Diffusion Models in Projected Latent Space. (arXiv:2302.07685v1 [cs.CV])" — Generating high-resolution and coherent video using diffusion models.
Paper: http://arxiv.org/abs/2302.07685
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
256×256 resolution, 128 frame v…
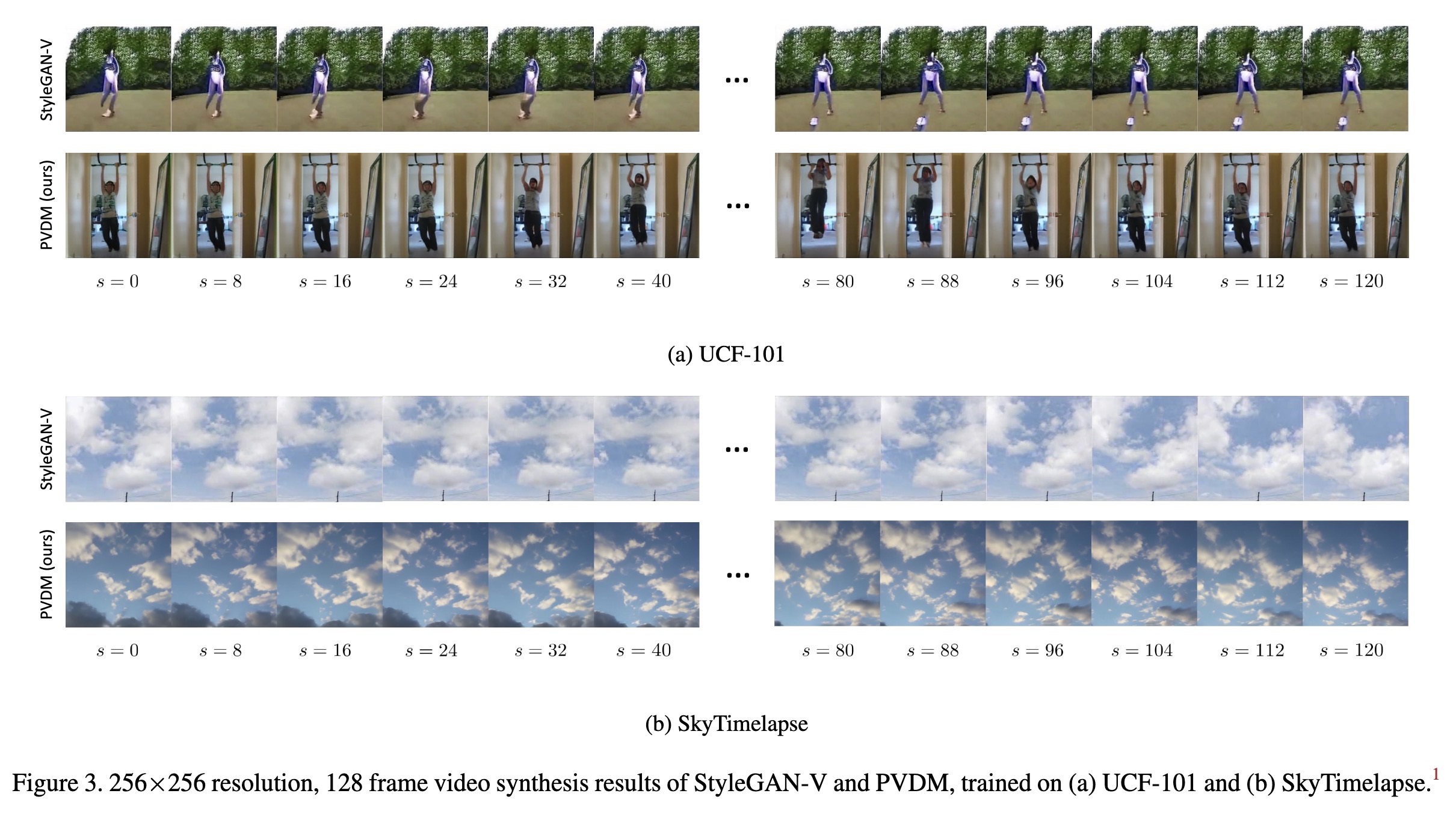
Paper: http://arxiv.org/abs/2302.07685
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
256×256 resolution, 128 frame v…
0
1
0
Fahim Farook
f
Yesterday's Pratchett novel title prompt was: "Snuff"
I didn't really expect much from that one since there isn't a lot to work with there. But I still got some interesting images 🙂
These are from multiple models and so the styles are a little different across images. But still, I thought the end results were interesting ...
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “Snuff”. Colourful pict…
Prompt: “Snuff”. A huge creatur…
Prompt: “Snuff”. A colourful im…
Prompt: “Snuff”. A colourful bu…




I didn't really expect much from that one since there isn't a lot to work with there. But I still got some interesting images 🙂
These are from multiple models and so the styles are a little different across images. But still, I thought the end results were interesting ...
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “Snuff”. Colourful pict…
Prompt: “Snuff”. A huge creatur…
Prompt: “Snuff”. A colourful im…
Prompt: “Snuff”. A colourful bu…
0
0
2
Fahim Farook
f
"DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model. (arXiv:2302.06908v1 [cs.CV])" — Today seems to be the day for papers on turning sketches into realistic colour images using diffusion models 😛 This is another approach ...
Paper: http://arxiv.org/abs/2302.06908
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A Sketch-Guided Lantent Diffusi…

Paper: http://arxiv.org/abs/2302.06908
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
A Sketch-Guided Lantent Diffusi…
0
1
1
Fahim Farook
f
"Text-Guided Scene Sketch-to-Photo Synthesis. (arXiv:2302.06883v1 [cs.CV])" — Creating a whole scene color image based on a sketch using generative models such as Stable Diffusion.
Paper: http://arxiv.org/abs/2302.06883
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of training and sampli…
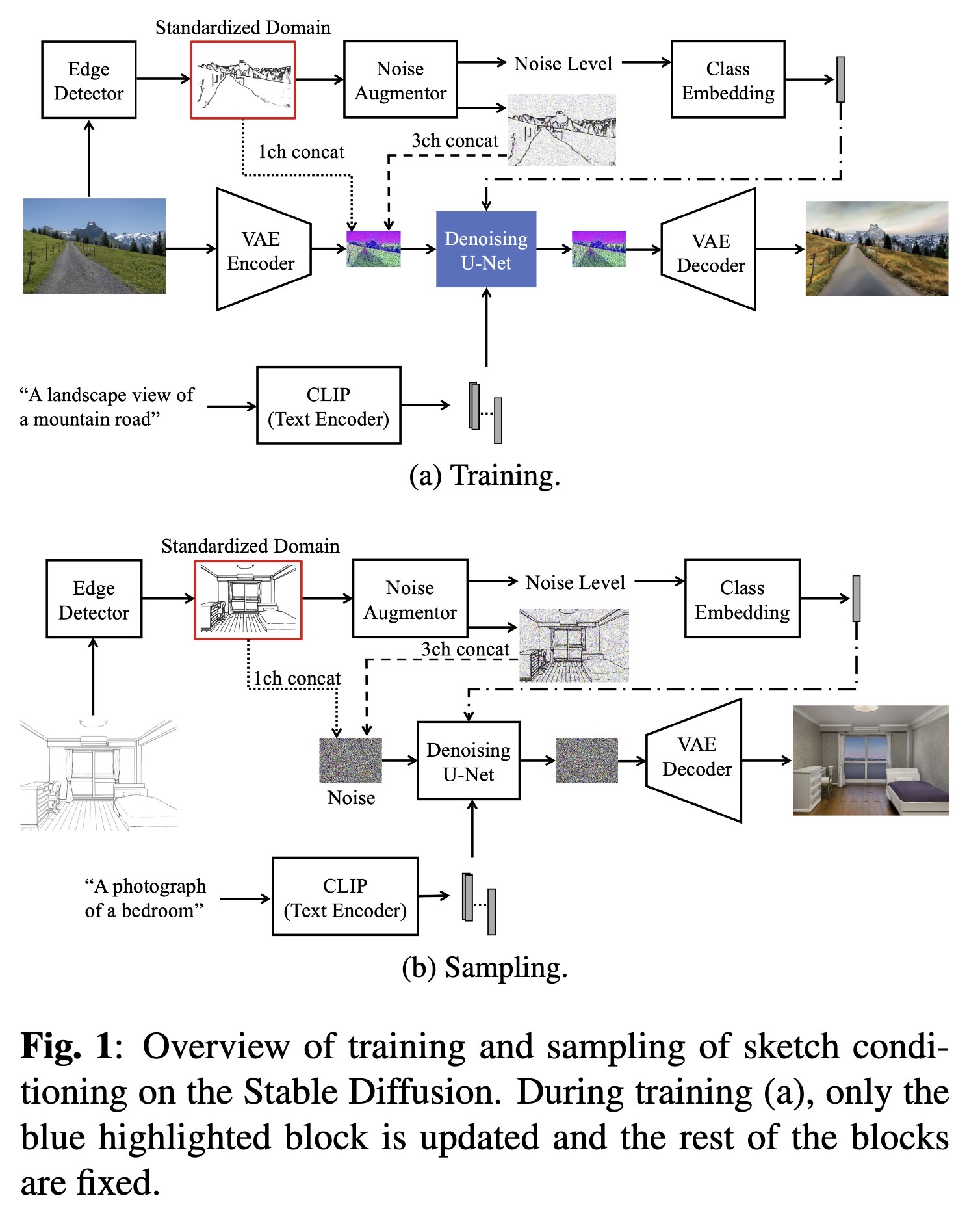
Paper: http://arxiv.org/abs/2302.06883
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of training and sampli…
0
1
0
Fahim Farook
f
"Make Your Brief Stroke Real and Stereoscopic: 3D-Aware Simplified Sketch to Portrait Generation. (arXiv:2302.06857v1 [cs.CV])" — Creating photorealistic images of people based on sketches using 3D generative models.
Paper: http://arxiv.org/abs/2302.06857
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The visualization of our Stereo…

Paper: http://arxiv.org/abs/2302.06857
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The visualization of our Stereo…
0
1
0
Fahim Farook
f
"DiffFashion: Reference-based Fashion Design with Structure-aware Transfer by Diffusion Models. (arXiv:2302.06826v1 [cs.CV])" — Transfer the input image appearance onto images of items of clothing while not altering the structure of the clothing item.
Paper: http://arxiv.org/abs/2302.06826
Code: https://github.com/Rem105-210/DiffFashion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two examples of a reference-bas…

Paper: http://arxiv.org/abs/2302.06826
Code: https://github.com/Rem105-210/DiffFashion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Two examples of a reference-bas…
0
1
0
Fahim Farook
f
"Multiple Appropriate Facial Reaction Generation in Dyadic Interaction Settings: What, Why and How?. (arXiv:2302.06514v2 [cs.CV] UPDATED)" — An attempt to generate appropriate behavioral responses to received stimulus and to evaluate the appropriateness of the generated responses.
Paper: http://arxiv.org/abs/2302.06514
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multiple appropriate reaction g…

Paper: http://arxiv.org/abs/2302.06514
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multiple appropriate reaction g…
0
1
0
Fahim Farook
f
"NYCU-TWO at Memotion 3: Good Foundation, Good Teacher, then you have Good Meme Analysis. (arXiv:2302.06078v2 [cs.CL] UPDATED)" — Classifying the emotions and intensity expressed in memes using machine learning.
Paper: http://arxiv.org/abs/2302.06078
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of the Meme Encoder
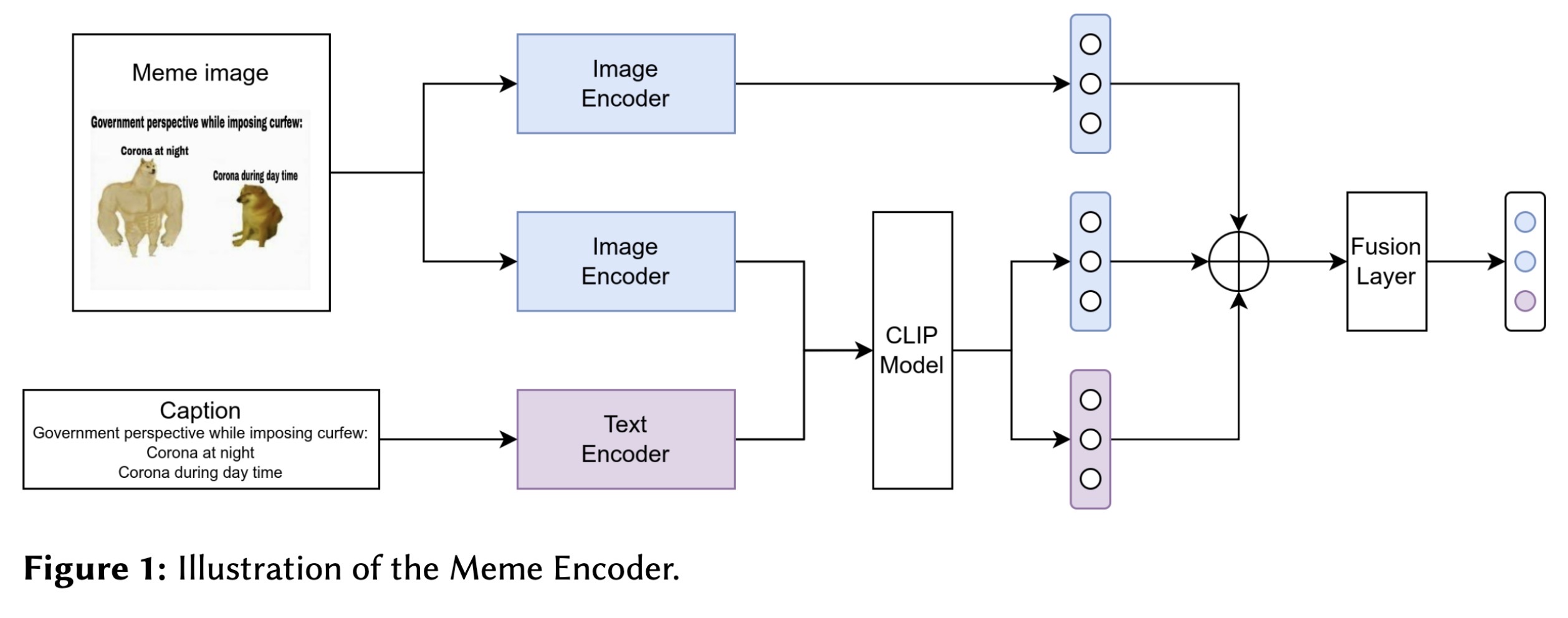
Paper: http://arxiv.org/abs/2302.06078
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of the Meme Encoder
0
1
0
Fahim Farook
f
"Vector Quantized Diffusion Model with CodeUnet for Text-to-Sign Pose Sequences Generation. (arXiv:2208.09141v2 [cs.CV] UPDATED)" — Using diffusion models to generate sign language pose sequences based on spoken language.
Paper: http://arxiv.org/abs/2208.09141
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The forward diffusion process a…

Paper: http://arxiv.org/abs/2208.09141
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The forward diffusion process a…
0
1
0
Fahim Farook
f
"ChatCAD: Interactive Computer-Aided Diagnosis on Medical Image using Large Language Models. (arXiv:2302.07257v1 [cs.CV])" — Using Large Language Models (LLM) with Computer-Aided Diagnosis (CAD) networks to enhance the output of CAD networks by summarizing and presenting the information in a more understandable format.
Paper: http://arxiv.org/abs/2302.07257
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of our proposed strate…
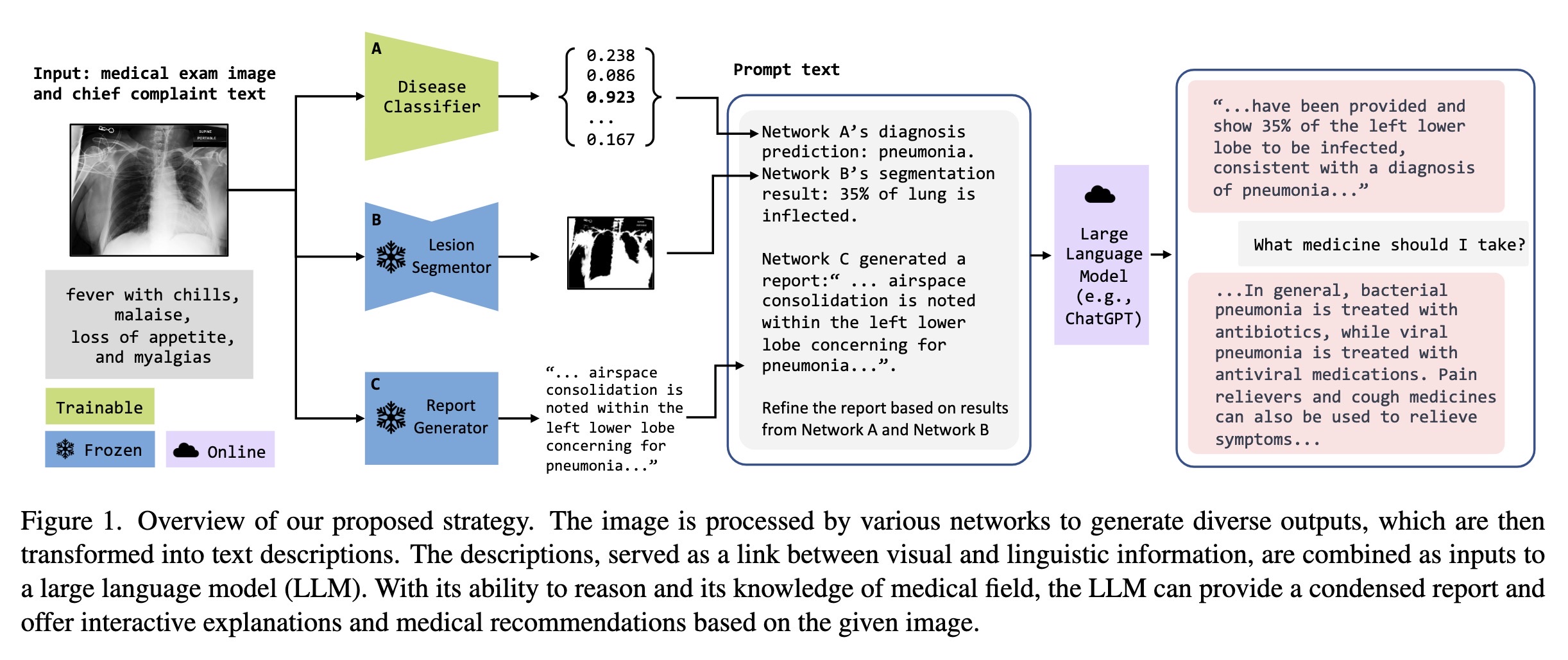
Paper: http://arxiv.org/abs/2302.07257
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Overview of our proposed strate…
0
0
0
Fahim Farook
f
"Painting 3D Nature in 2D: View Synthesis of Natural Scenes from a Single Semantic Mask. (arXiv:2302.07224v1 [cs.CV])" — Using a semantic mask as input to generate photorealistic color images of natural scenes.
Paper: http://arxiv.org/abs/2302.07224
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given only a single semantic ma…
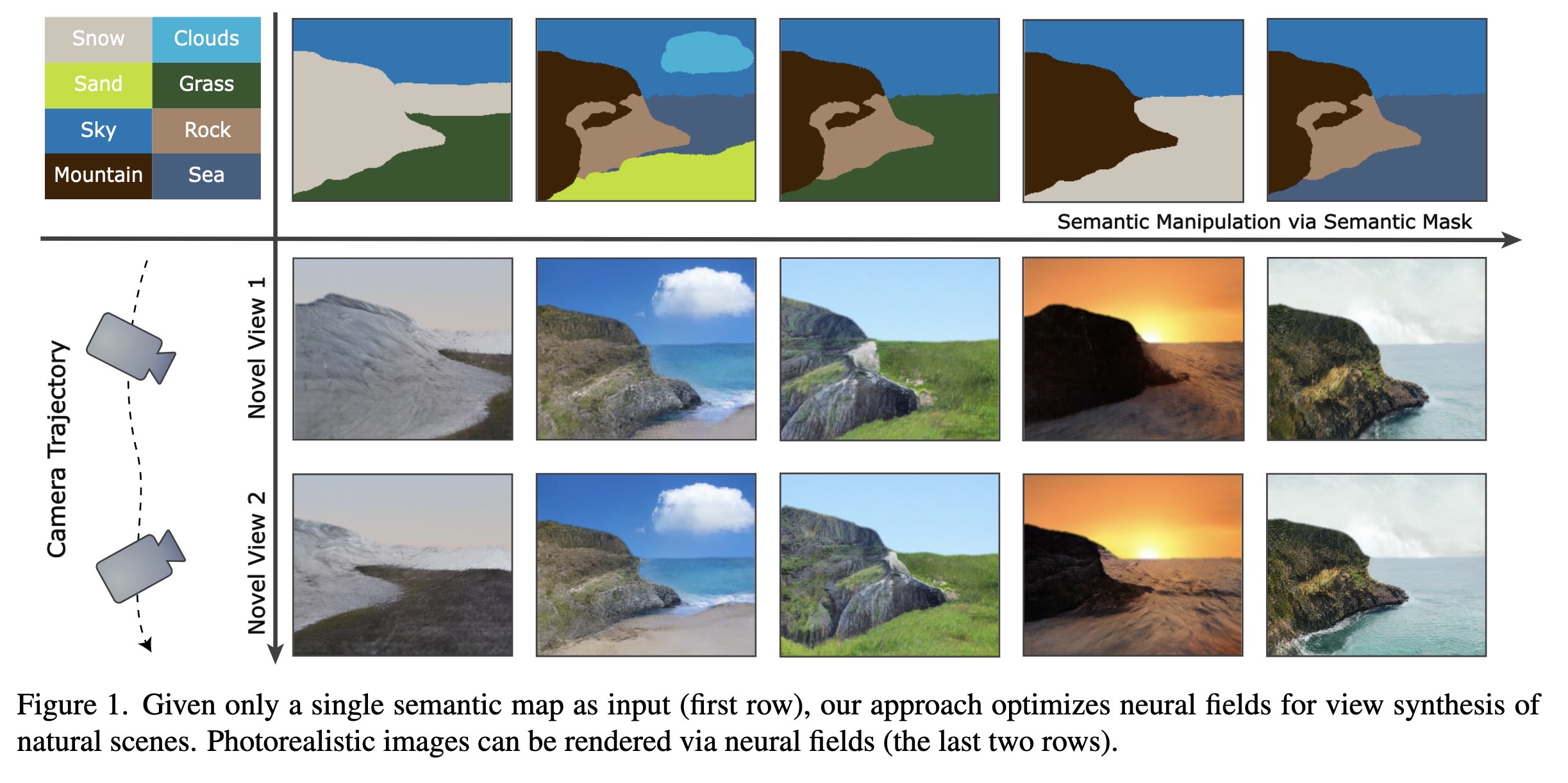
Paper: http://arxiv.org/abs/2302.07224
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Given only a single semantic ma…
0
1
0
Fahim Farook
f
"Universal Guidance for Diffusion Models. (arXiv:2302.07121v1 [cs.CV])" — a universal guidance algorithm that enables diffusion models to be controlled by arbitrary guidance methods such as segmentation, face recognition, object detection, and classifier signals, without the need to retrain for that specific method.
Paper: http://arxiv.org/abs/2302.07121
Code: https://github.com/arpitbansal297/Universal-Guided-Diffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of diffusion being gui…

Paper: http://arxiv.org/abs/2302.07121
Code: https://github.com/arpitbansal297/Universal-Guided-Diffusion
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Examples of diffusion being gui…
0
1
2
Fahim Farook
f
Now that I've got a working workflow for StableDiffusion image generation again, I can finally get back to the long neglected #DiscWorld novel title series ...
Yesterday's prompt was: "I Shall Wear Midnight"
Not much DiscWorld-iness in the images, but they all were suitably dark to represent midnight, I guess 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…




Yesterday's prompt was: "I Shall Wear Midnight"
Not much DiscWorld-iness in the images, but they all were suitably dark to represent midnight, I guess 😛
#AIArt #StableDiffusion #DeepLearning #MachineLearning #CV #AI #DiscWorld
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
Prompt: “I Shall Wear Midnight”…
1
2
6
Fahim Farook
f
"Exploiting Cultural Biases via Homoglyphs in Text-to-Image Synthesis. (arXiv:2209.08891v2 [cs.CV] UPDATED)" — An interesting look at how replacing Latin characters with non-Latin (visual) equivalents, generative models reflect cultural stereotypes and biases in their generated images.
Paper: http://arxiv.org/abs/2209.08891
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of homoglyph manipulati…
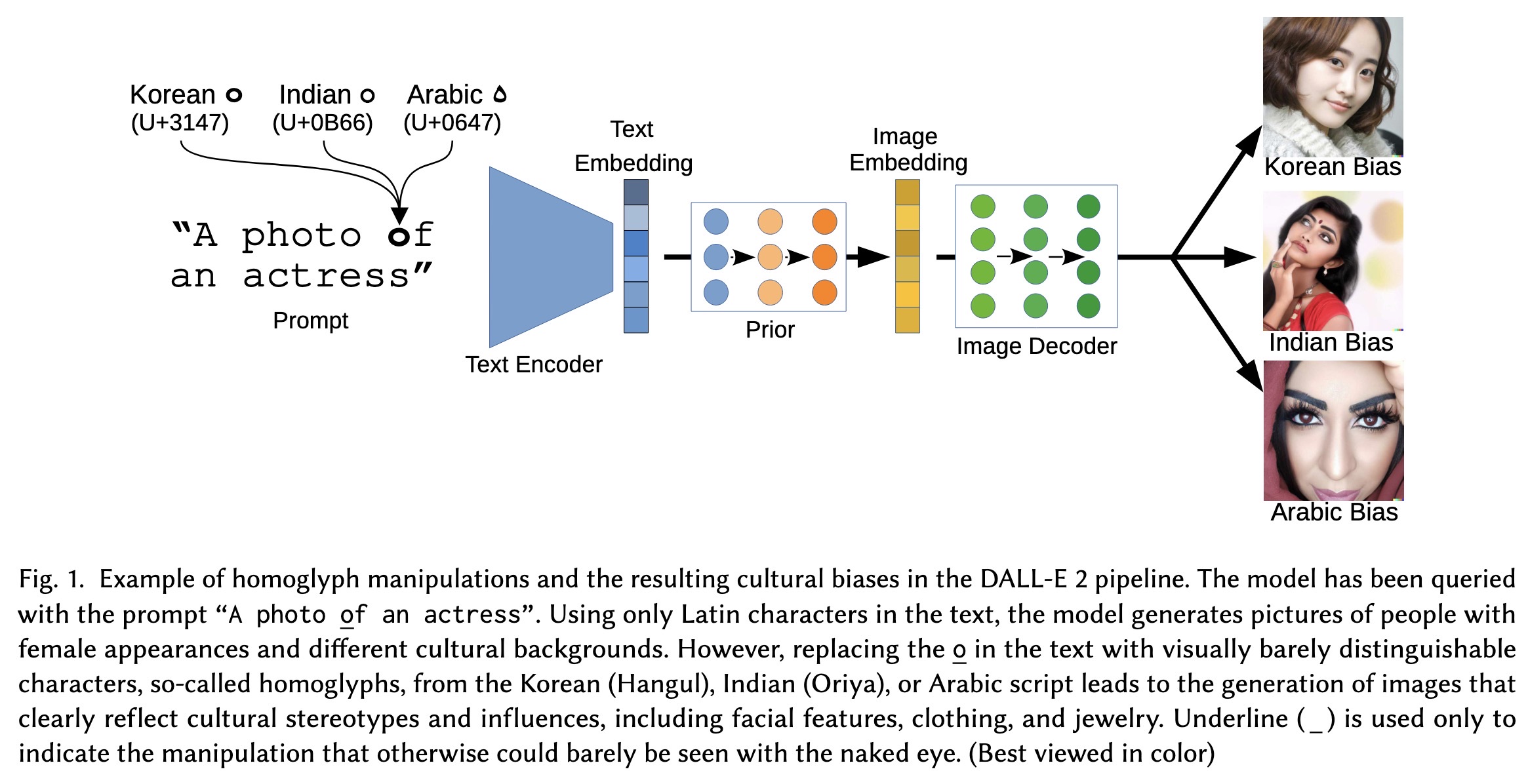
Paper: http://arxiv.org/abs/2209.08891
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Example of homoglyph manipulati…
0
1
0
Fahim Farook
f
"Dark solitons in Bose-Einstein condensates: a dataset for many-body physics research. (arXiv:2205.09114v2 [cond-mat.quant-gas] UPDATED)" — A dataset of over 1.6×10⁴ experimental images of Bose-Einstein condensates containing solitonic excitations to enable machine learning (ML) for many-body physics research.
Paper: http://arxiv.org/abs/2205.09114
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a)–(c) Raw data from which dat…
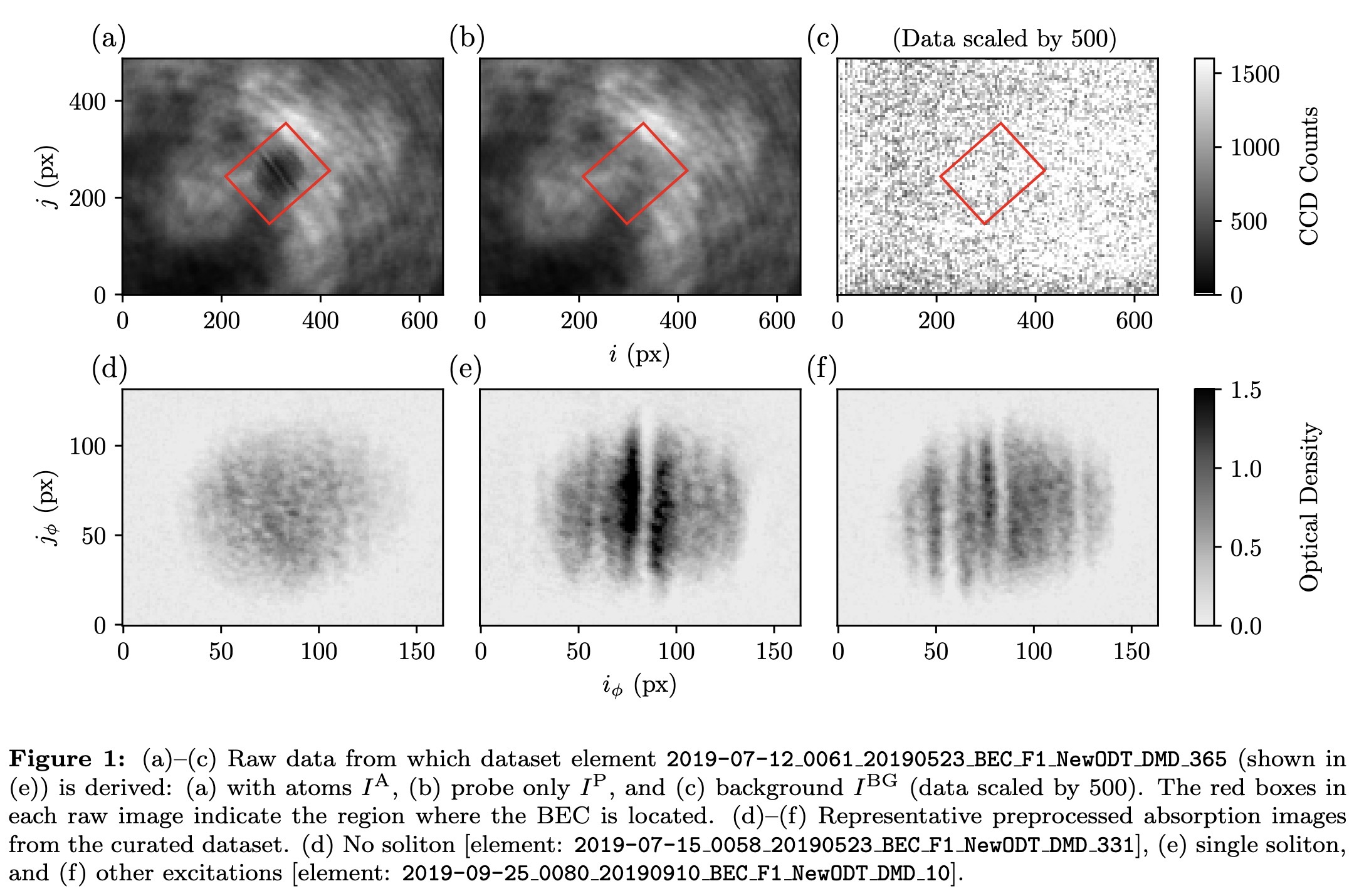
Paper: http://arxiv.org/abs/2205.09114
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
(a)–(c) Raw data from which dat…
0
0
1
Fahim Farook
f
"I²SB: Image-to-Image Schrödinger Bridge. (arXiv:2302.05872v1 [cs.CV])" — A new class of conditional diffusion models that directly learn the nonlinear diffusion processes between two given distributions.
Paper: http://arxiv.org/abs/2302.05872
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outputs of our proposed Image-t…

Paper: http://arxiv.org/abs/2302.05872
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Outputs of our proposed Image-t…
0
3
2
Fahim Farook
f
"Heckerthoughts" — A manuscript going through the basic concepts central to AI and Machine Learning where the author claims that some concepts he included are missing from modern ML courses. Conversational style, anecdotal, and not too long at 54 pages. Worth reading …
Paper: https://arxiv.org/abs/2302.05449
#AI #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The “burst” of emails that prom…

Paper: https://arxiv.org/abs/2302.05449
#AI #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
The “burst” of emails that prom…
0
4
1