Conversation
Fahim Farook
f
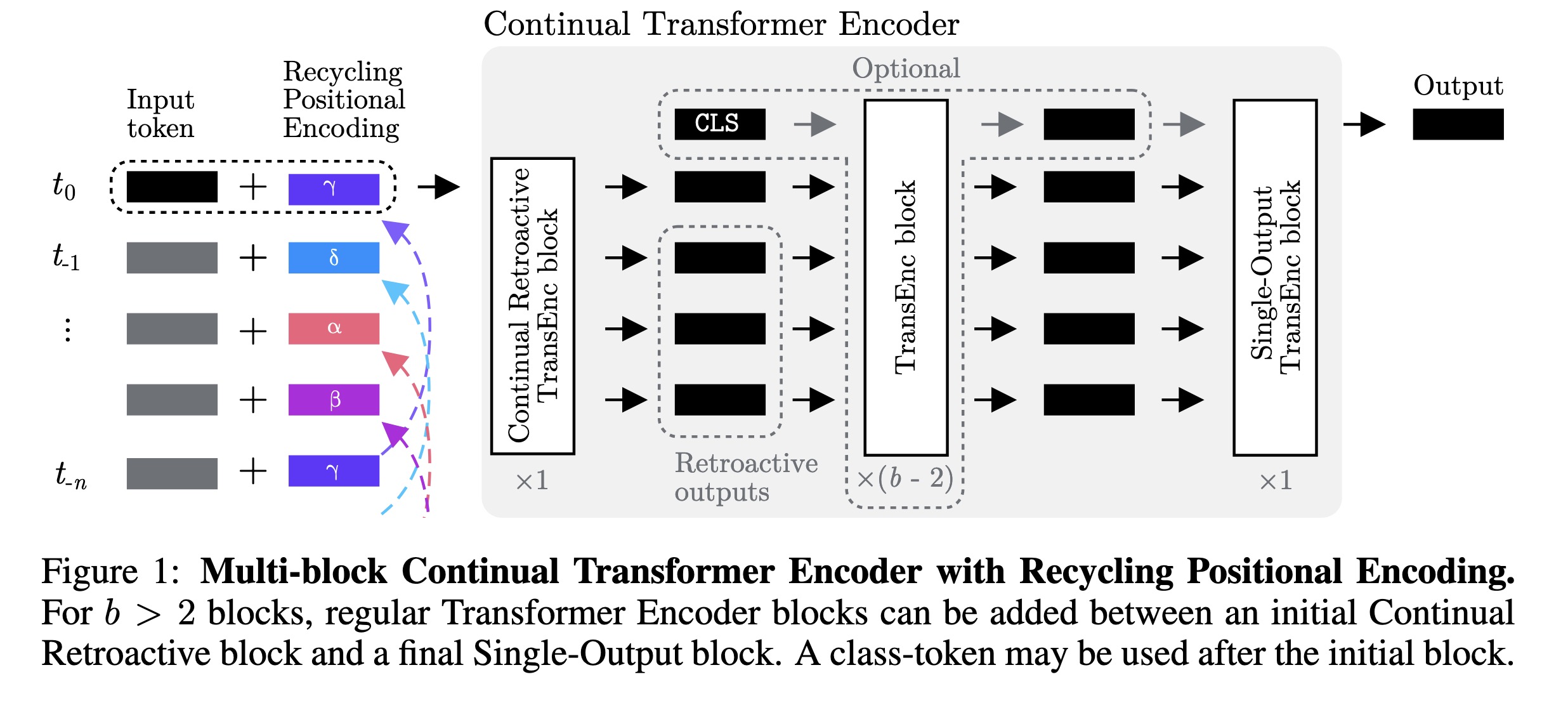
"Continual Transformers: Redundancy-Free Attention for Online Inference. (arXiv:2201.06268v3 [cs.AI] UPDATED)" — A novel formulations of the Scaled Dot-Product Attention, which enable Transformers to perform efficient online token-by-token inference on a continual input stream.
Paper: http://arxiv.org/abs/2201.06268
Code: https://github.com/lukashedegaard/continual-transformers
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multi-block Continual Transform…
Paper: http://arxiv.org/abs/2201.06268
Code: https://github.com/lukashedegaard/continual-transformers
#AI #CV #NewPaper #DeepLearning #MachineLearning
<<Find this useful? Please boost so that others can benefit too 🙂>>
Multi-block Continual Transform…
 0
0
 2
2
 3
3